
本記事は Slack のエンジニアリングブログで公開されたものです。
Slack の技術者は、長く「保守的」な立場をとっています。つまり、新しいカテゴリーのインフラストラクチャに投資する際には、厳格な基準で評価したうえで採用を決めます。2016 年に導入した機械学習を活用した機能においても、私たちは同じ姿勢で、その分野の堅牢なプロセスを開発し、熟練したチームを育ててきました。
そんな私たちでも、この 1 年の商用の大規模言語モデル(LLM)の向上と、それが人々に与える影響の大きさに驚かされました。これにより、情報が多すぎる、知りたいことが見つからない、といったユーザーが抱える最大の問題が解決されつつあるのです。実際、AI を導入したユーザーの 90% が、導入していない人と比べて、より高度な生産性を実現できていると報告しています。
ただ、ほかの新しいテクノロジーを導入する場合と同じく、AI を搭載したプロダクトをリリースできるかどうかは、顧客データの管理責任に関する Slack の厳格な基準を満たした実装方法を見つけられるかどうかにかかっています。つまり、優れた AI 機能を提供することはもちろん、いかに信頼される AI を構築できるかが課題になります。
生成モデルの世界はまだ歴史が浅く、その大部分では依然として研究開発が重視され、企業での利用に十分に焦点が当てられていません。そのため、新しい Slack AI アーキテクチャの構築に適用できるエンタープライズグレードのセキュリティやプライバシーに関するモデルは、まだ世の中にほとんど存在していませんでした。
そこで私たちはまず、Slack AI の構築方法についての基本原則を定めるところから始めました。既存のセキュリティとコンプライアンスのサービス、および「顧客データは神聖なものである」といったプライバシーに対する基本理念を堅持することを必須条件とし、そのうえで、生成 AI 分野での指針となる新しい Slack AI の原則をチームで作成しました。具体的には以下のようなものです。
- 顧客データを Slack 外に出さない。
- 顧客データで大規模言語モデル(LLM)をトレーニングしない。
- Slack AI は、ユーザーがすでに閲覧できるデータに対してのみ動作する。
- Slack AI でも、Slack のエンタープライズグレードのセキュリティとコンプライアンス要件のすべてを維持する。
このような原則を定めることで、ときには課題に直面しながらも、より明確なアーキテクチャを設計することができました。以下では、それぞれの原則が、現在の Slack AI にどのように反映されているのかを見ていきます。
顧客データを Slack 外に出さない
私たちが直面した最初の、そしておそらく最も重要な決断を要した課題は、Slack が管理する仮想プライベートクラウド(VPC)内に顧客データを保ったまま、いかにトップレベルの基盤モデルを使用できるようにするかでした。生成モデルの世界では、基盤モデルを利用する企業のほとんどがホステッド型のサービスを直接呼び出しており、それに代わる選択肢は乏しい状況でした。
既存のアプローチではうまくいかないことはわかっていました。Slack とそのユーザー企業は、データのオーナーシップに対して高い期待を抱いています。特に Slack は FedRAMP Moderate 認証を取得しており、顧客データを信頼境界の外に送信しないなど、特定のコンプライアンス要件に対応しています。そのため私たちは、データが AWS の仮想プライベートクラウド(VPC)の外に出ないようにすることで、第三者がそのデータを保持したり、それを使ってトレーニングを行なったりできないようにしたかったのです。
そこで私たちは、Slack のインフラストラクチャで基盤モデルをホストする方法がないか頭をひねりました。しかし、基盤モデルのほとんどがクローズドソースです。プロバイダは、その秘密を公開して、ユーザー企業が自社のハードウェアにそれを実装できるようにすることを望みません。
幸いなことに、AWS は、基盤モデルのプロバイダとユーザー企業との間を信頼できる方法で仲介するサービス、AWS SageMaker を提供しています。SageMaker を使えば、クローズドソースの大規模言語モデル(LLM)をエスクロー VPC でホストしてデプロイできるため、ユーザー企業のデータのライフサイクルをコントロールしながら、モデルのプロバイダが Slack の顧客データにアクセスできないようにすることが可能になります。Slack が SageMaker をどのように使用しているかについて、詳しくは AWS ブログのこちらの記事をご覧ください。
このようにして、私たちは AWS VPC でホストされたトップレベルの基盤モデルを活用しながら、顧客データについての保証を得ることができました。
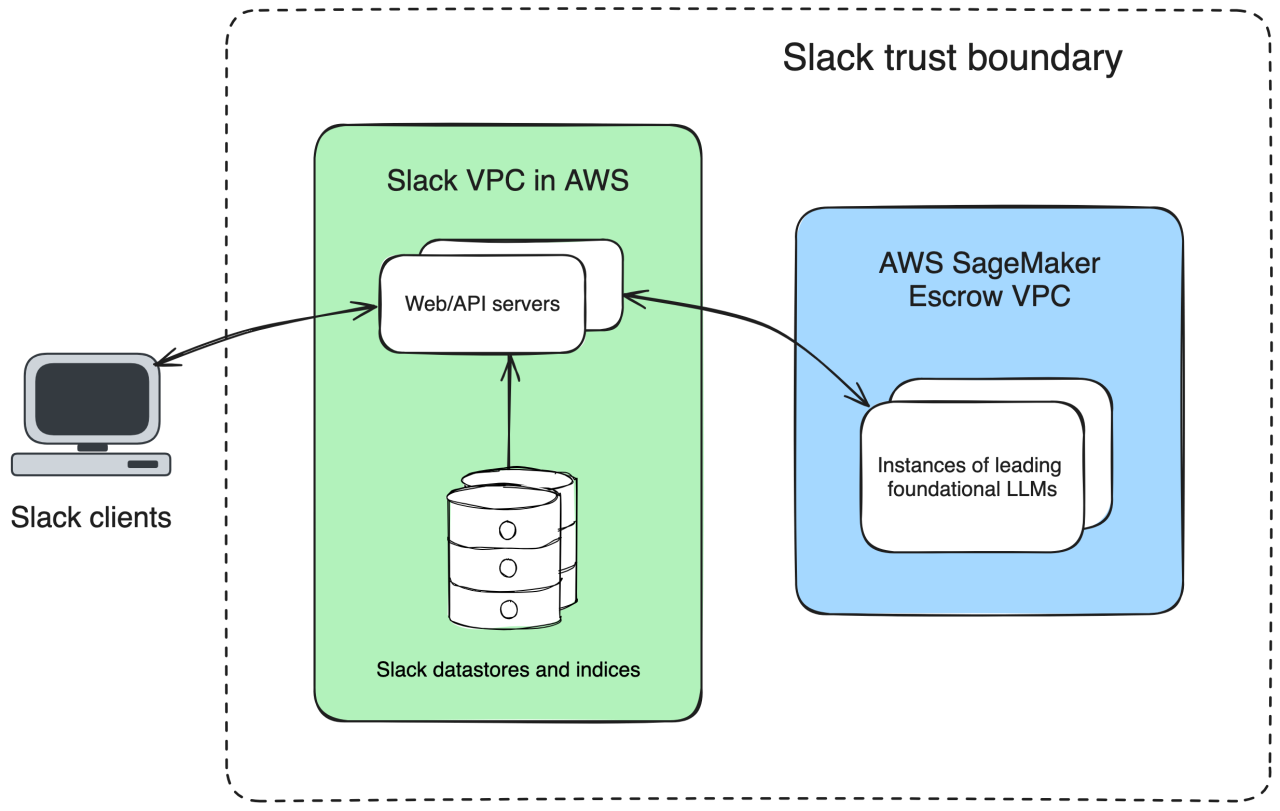
顧客データで大規模言語モデル(LLM)をトレーニングしない
次に私たちは、モデルのトレーニングや微調整を行わず、既成のモデルを使うことを選択しました。この決定も重要でした。Slack は、検索結果のランクづけなどに用いられている従来の機械学習(ML)モデルを採用したときから、プライバシーに対する基本理念を定めていました。これには、ワークスペース間でデータを漏えいさせないことや、このような手法の利用に関してユーザー企業に選択肢を提供することなどが含まれます。テクノロジーがまだ成熟していないなかで、Slack の顧客データを使って生成 AI モデルをトレーニングすれば、この理念を十分に保証することができないと私たちは考えました。
そこで私たちは、検索拡張生成(RAG)を採用して、既成のモデルをステートレスな方法で利用することを選択しました。RAG を使えば、タスクの実行に必要な背景情報のすべてが各リクエスト内に含まれるため、モデルはそのデータを保持しません。例えば、チャンネルを要約する場合、LLM には、要約するメッセージとその手順を含んだプロンプトが送信されます。この RAG のステートレス性は、プライバシー確保において大きなメリットになると同時に、プロダクトとしてのメリットももたらします。Slack AI が生成する内容はすべて、一般公開されているインターネットではなく、自社のナレッジベースに基づくため、より関連性が高く正確な結果が得られるからです。この方法により、モデルがデータを保持するというリスクなしに、ユーザー企業独自のデータセットを組み込むことが可能になります。
ただ、RAG を使うと、利用できるモデルが限られる場合があります。タスク処理に必要なすべてのデータを渡すのに十分なサイズの「コンテキストウィンドウ」を持つモデルが必要です。また、LLM に送るコンテキストデータが多いほど、モデルが処理しなければならないデータ量が増えるため、リクエストへの反応が遅くなります。ご想像のとおり、チャンネル内のすべてのメッセージを要約するというタスクでは、かなりの量のデータを処理する必要があります。
つまり、遅延時間を十分低く抑えられるような大きなコンテキストウィンドウを持つ、トップレベルのモデルを見つける必要がありました。そこでいくつかのモデルを評価し、最初のユースケースである要約と検索の機能に合ったモデルを見つけました。しかし、まだ改善の余地がありました。そこから、プロンプトの調整と、従来の機械学習モデルを生成モデルと結びつけて結果を向上させる工夫の両面において、長い挑戦の旅が始まったのです。
モデルが進化するごとに、RAG の処理はより簡単かつ高速になっていきます。コンテキストウィンドウも成長し、モデルはその大きくなったコンテキストウィンドウ全体からデータを合成できるようになります。このアプローチにより、目指している品質を確保しながら、顧客データを確実に保護できると私たちは確信しています。
Slack AI は、ユーザーがすでに閲覧できるデータに対してのみ動作する
Slack AI は、リクエスト元のユーザーが閲覧できるものと同じデータにしかアクセスできません。これも私たちの基本理念のひとつです。これにより、通常の検索では表示されないような結果が、Slack AI の検索機能によってユーザーに提示されることはありません。ユーザーがチャンネル内で閲覧できない内容が、要約機能によって要約されることもありません。
要約または検索の対象となるデータを取得する際に、リクエスト元ユーザーのアクセス制御リスト(ACL)を使い、チャンネルや検索結果ページに表示するデータを取得する既存のライブラリを利用することで、これを実現しています。
これは技術的には難しいことではありませんでしたが、方法を明確に選ぶ必要がありました。これを確実に行うには、Slack の主要な機能を再利用しながら、最後にその上に AI 機能を加える方法がベストです。
また「Slack AI を呼び出したユーザーだけが、AI が生成した出力を閲覧できる」という点も重要です。これにより、Slack が信頼できる AI パートナーであるという確信が築かれます。つまり、その人が見ることのできるデータのみが入力に使われ、その人だけが出力を見ることができる、ということです。
Slack AI でも、Slack のエンタープライズグレードのセキュリティとコンプライアンス要件のすべてを維持する
Slack なくして Slack AI はありません。そのため、私たちは Slack のエンタープライズグレードのコンプライアンスとセキュリティをすべて統合しました。そして、データを最小限にするという原則に従い、タスクの遂行に必要なデータのみを必要な期間だけ保存します。
データを最小限にした結果、データがまったく保存されない場合もあります。Slack AI の出力は可能なかぎり一時的なものとなっており、会話の要約や回答の検索が生成するその時々のレスポンスは、ディスクには保存されません。
その方法が不可能な場合は、Slack の既存のコンプライアンスインフラストラクチャを可能なかぎり再利用し、必要に応じて新しいサポートを構築しました。暗号化キー管理や国際データレジデンシーなど、提供するコンプライアンスサービスの多くは、既存のインフラストラクチャに組み込まれています。そのほかには、要約などの機能にどのようなメッセージが入力されるのかを認識できるよう、特別なサポートを組み込みました。例えば、データ損失防止(DLP)によってメッセージが非表示にされている場合、そのメッセージから派生した要約はすべて無効になります。これにより、DLP やその他の管理機能を Slack AI によってさらに強化できます。それらのコントロールが Slack のメッセージコンテンツに対して有効になっている場合、Slack AI の出力に対しても同様に有効になるということです。
ここまで読んでいただきありがとうございます。実際、ここまで来るのは長い旅だったんです!プロンプトの作成、モデルの評価、急増する需要への対応などの方法については今回は説明できませんでしたが、これは次の機会にとっておくことにしましょう。いずれにしても、まずセキュリティとプライバシーについてお伝えできてよかったと思います。私たちがデータ保護に真剣に取り組んでいること、そして各プロセスでどのようにデータを保護しているかについて、皆さまの理解を深めることに役立ちましたら幸いです。
 助かります!
助かります!
ご意見ありがとうございました!
了解です!
ご意見ありがとうございました!
うーん、システムがなにか不具合を起こしてるみたいです。後でもう一度お試しください。