Sticker Suggestion Function using Privacy Preserving Technologies
To preserve user privacy, LY Corporation may use privacy preserving technologies such as federated learning and differential privacy for sticker suggestions with the user’s taste.
For more information Close
We provide a function that suggests stickers with the user’s taste in chat rooms (hereinafter "sticker suggestion function").
In this function, we introduced two technologies called federated learning and differential privacy allowing to improve usability while preserving user privacy. These technologies are being established as a global standard, and we are also conducting world-leading research in this field.
LY Corporation takes user privacy preservation seriously. For the purpose of preserving user privacy while enhancing usability using data analysis, we will pursue research and development of these technologies and find ways to introduce them into a wide range of our services.
In this article, we will explain how the sticker suggestion function works and benefits users.
Importance of Sticker Suggestion Function
The sticker suggestion function displays and recommends stickers that are close to the meaning of what a user typed in the chat box, allowing to replace common expressions such as "Good morning" or "Thank you" with matching stickers.
This function is performed according to the following process.
- The LINE app downloads stickers, and each sticker is associated with multiple keywords.
- When a user types a message, the app extracts keywords from the message.
- The app makes suggestions from downloaded stickers with the matched keyword.
This process runs exclusively on the user device.
If the app makes suggestions uniformly to all users, it will not be convenient for the users because the recommended stickers are not suited to user's preference.
Therefore, it is necessary to learn about the user's preference for stickers, deduce usage trends, and recommend stickers customized for each user.
There are two types of data used as a reference for user preference:
- “1. Sticker Download Data”, data based on the download of stickers
- “2. Sent Sticker Data”, data of stickers used in actual communications
The technologies introduced in the sticker suggestion function reduce the information we receive from users by processing “2. Sent Sticker Data” on user devices, and keep users raw data on their devices, therefore preserving user privacy (*1).
Note that LY Corporation does not use text input in chat rooms to analyze or train ML models.
Processing Overview
The processing flow of the sticker suggestion function is shown in the Figure 1 below (*2).
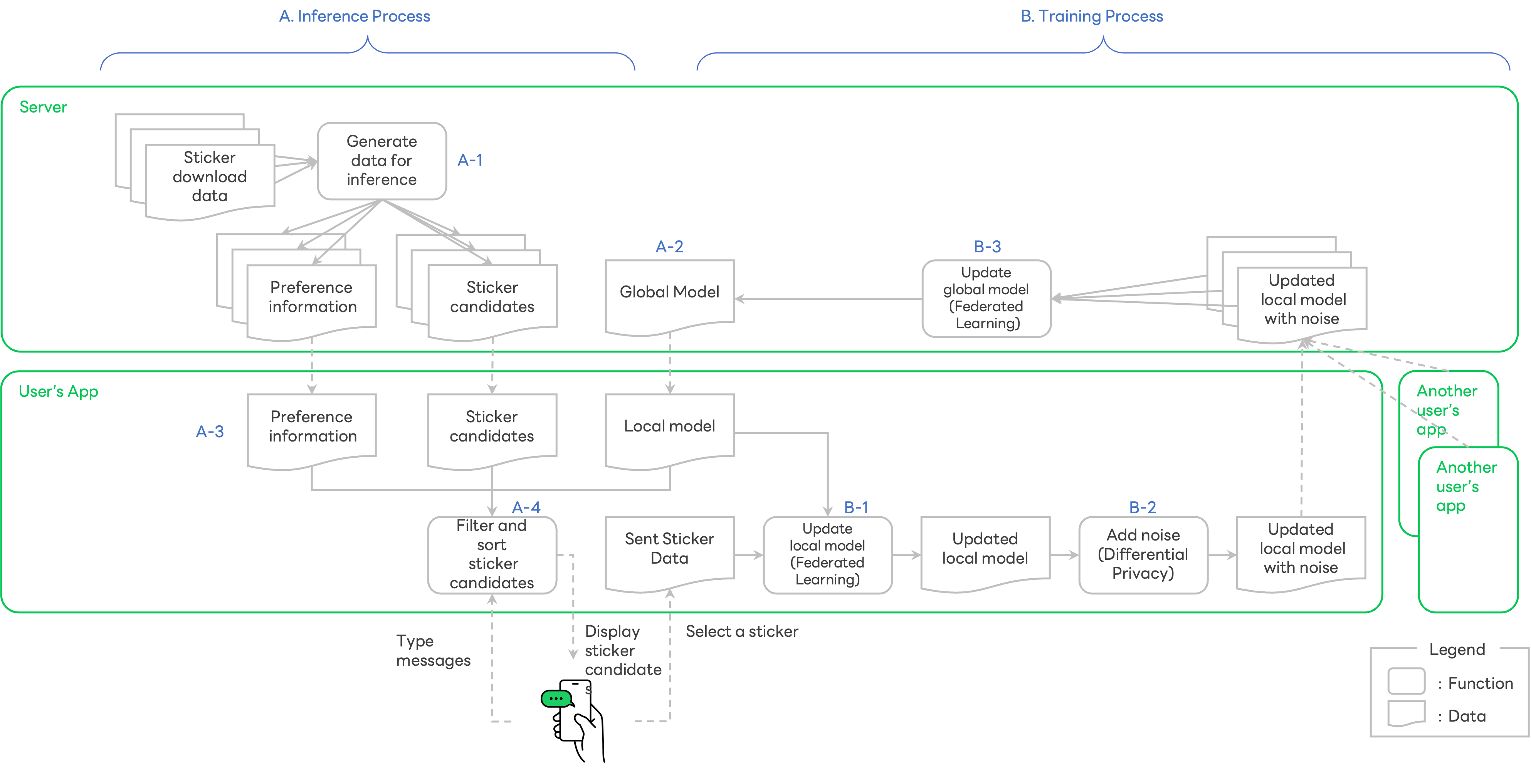 Figure 1:Overview of the sticker suggestion function
Figure 1:Overview of the sticker suggestion function
This feature basically consists of two processes, "A. Inference" and "B. Training".
First, let's talk about the “A. Inference” process.
A-1. Server generates preference information and sticker candidates from “1. Sticker Download Data”.
- Preference information is data representing user preference learned by the server, using download logs (including purchased and sponsored free stickers, and downloaded premium stickers).
- Sticker candidates is a list of stickers for suggestion. It contains keywords associated with each sticker.
A-2. Server also generates and updates a global model (*3) that lists up stickers in sequence via "B. Training Process".
A-3. App downloads preference information, sticker candidates, and global model from the server.
A-4. When users type messages in the app, the app extracts predetermined keywords from the message, and selects sticker candidates, matching the predetermined keywords. The app uses the preference information and local model to rank the selected stickers, and display them. All of these steps are processed on the device.
Next, it is the "B. Training" process.
B-1. Apps on the device of randomly selected users perform model training, using "2. Sent Sticker Data", and update the local model on the devices (*4,*5).
B-2. As an additional post process, the app adds noise to the model, using differential privacy technology. One of the main reasons for adding noise is to prevent another party from deducing the actual stickers sent by the user via the updated local model. When sending the updated local model, the app excludes the user identifier to minimize the amount of information sent to the server.
B-3. The server receives updated local models from multiple users, randomly selected in B-1. The models are averaged and used to update the global model (*6). This collaborative machine learning method that involves both client devices and server(s), is called federated learning.
Through the overall processes, LY Corporation improves the ML model used to rank sticker candidates without explicitly receiving "2. Sent Sticker Data", and reinforces the usability of sticker suggestion.
*1. Application of this technology does not change existing data handling policy at this time and does not immediately improve privacy.
*2. As an example, this document describes an overview of process in LINE Sticker Premium Service.
*3. At first, the global model randomly ranks stickers (No pre-training is performed on the server). Since the sticker candidates are sufficiently personalized, users still enjoy the benefit of personalization.
*4. The training process is performed only when the user's terminal is idle and charging.
*5. The local model learns which stickers the user selected from the list of stickers displayed. This learning process does not take into account the text input by the user at all.
*6. The updated global model on the server is again distributed to users. The updated global model better predicts the order of stickers than the previous one.