
少数ショット プロンプトなどのプロンプト設計戦略では、 選択できます。ファインチューニングは、モデルの モデルが特定の出力に沿うように支援したり、 手順が不十分で一連の例がある場合に、 必要があります。
このページでは、Gemini API の背後にあるテキストモデルのファインチューニングに関するガイダンスについて説明します。 あります。
ファインチューニングの仕組み
ファインチューニングの目標は、1 対 1 または 1 の会話に対して できます。ファインチューニングは、モデルにトレーニング タスクの例を多数含むデータセットです。ニッチなタスクの場合は、 パフォーマンスの大幅な向上が期待できます。 例の数になります。
トレーニング データは、プロンプト入力を使用したサンプルとして構造化する必要があります。 出力を返します。サンプルデータを使用してモデルを直接チューニングすることも可能 Google AI Studio です目的は、期待される動作を模倣するようモデルに学習させること その動作やタスクを示す多くの例を与えます。
チューニング ジョブを実行すると、モデルはモデルの調整に役立つ追加のパラメータを学習 求められるタスクの実行や、求められるタスクの 確認します。これらのパラメータは推論時に使用できます。出力は、 チューニング ジョブは新しいモデルであり、実質的には 元のモデルとの差を測定します。
データセットを準備する
ファインチューニングを開始する前に、モデルのチューニングに使用するデータセットが必要です。対象 データセットのサンプルは高品質でなければならず 多様で、実際の入力と出力を表しています。
形式
データセットに含まれるサンプルは、想定される本番環境と一致している必要があります トラフィックです。データセットに特定の書式、キーワード、手順、 本番環境データを同じ方法でフォーマットし、 同じ手順が含まれています。
たとえば、データセットのサンプルに "question:" と "context:" が含まれている場合は、本番環境のトラフィックにも、データセットの例と同じ順序で "question:" と "context:" が含まれるように整形する必要があります。コンテキストを除外すると、モデルはパターンを認識できず、
データセットに含まれるサンプルに
完全に一致する質問が含まれていても
データセット内の各サンプルにプロンプトやプリアンブルを追加すると、 トレーニング済みモデルのパフォーマンスを改善しますプロンプトまたはプリアンブルが 含まれる場合、チューニングされたモデルに対するプロンプトに トレーニングされます。
トレーニング データサイズ
わずか 20 個のサンプルでモデルをファインチューニングできます。追加データ 一般的に回答の質が向上します。100 をターゲットとしてください 500 個の例があります次の表に示す さまざまな一般的なタスク向けにテキストモデルをファインチューニングするための推奨データセット サイズは次のとおりです。
| タスク | データセット内のサンプル数 |
|---|---|
| 分類 | 100 以上 |
| 要約 | 100 ~ 500 以上 |
| ドキュメントの検索 | 100 以上 |
チューニング用データセットをアップロードする
データは、API を使用してインラインで渡されるか、Google Cloud にアップロードされたファイルを通じて渡されます。 説明します。
[インポート] ボタンをクリックし、ダイアログの手順に沿ってデータをインポートします。 プロンプトを選択するか、サンプルを含む構造化プロンプトを選択して、チューニングとしてインポートします。 見てみましょう。
クライアント ライブラリ
クライアント ライブラリを使用するには、createTunedModel にデータファイルを指定します。
あります。ファイルサイズの上限は 4 MB です。ファインチューニングのクイックスタート:
Python の使用を開始してください。
cURL
cURL を使用して REST API を呼び出すには、JSON 形式のトレーニング サンプルを指定して、
training_data 引数。チューニングのクイックスタート:
cURL にアクセスしてください。
高度なチューニング設定
チューニング ジョブを作成するときに、次の詳細設定を指定できます。
- エポック: トレーニング セット全体に対するフル トレーニング パス。 1 回だけ処理されています。
- バッチサイズ: 1 回のトレーニング イテレーションで使用されるサンプルのセット。「 バッチサイズはバッチのサンプル数を決定します
- 学習率: アルゴリズムに学習過程を指示する浮動小数点数 モデルのパラメータを強く調整する必要があります。たとえば、 学習率を 0.3 にすると重みとバイアスが 3 倍に調整される 非常に強力です。学習率が高い / 低いことでは、 独自のトレードオフがあり、ユースケースに応じて調整する必要があります。
- 学習率の乗数: レートの乗数は、モデルの 予測します。値を 1 にすると、元の学習率が使用されます。 モデルです。値が 1 より大きい場合、学習率は高くなり、1 の間の値になります。 0 に設定すると学習率が低下します。
推奨構成
次の表に、Cloud Storage オブジェクトを微調整するための 基盤モデル:
| ハイパーパラメータ | デフォルト値 | 推奨される調整 |
|---|---|---|
| エポック | 5 |
5 エポックより前に損失が横ばいし始めた場合は、小さい値を使用します。 損失が収束しつつあり、横ばい状態でないと思われる場合は、より大きな値を使用します。 |
| バッチサイズ | 4 | |
| 学習率 | 0.001 | データセットが小さい場合は、小さい値を使用します。 |
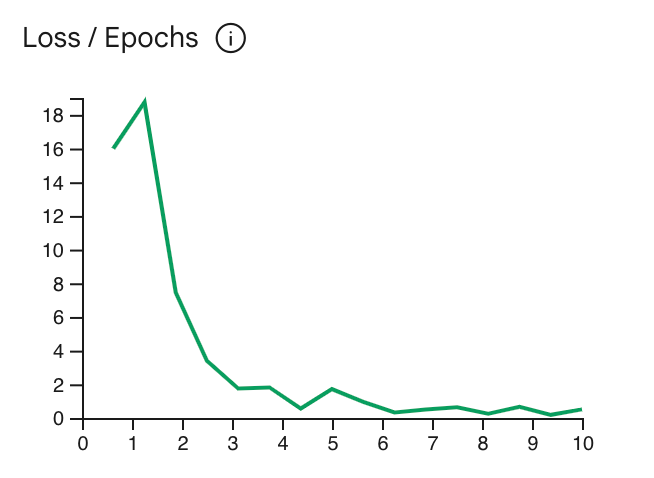
損失曲線は、モデルの予測が理想からどの程度逸脱しているかを示します。
エポックごとにトレーニングサンプルで予測が行われます。テストを中断して
停滞する直前の曲線の最も低いポイントでトレーニングを行うことになります。たとえば
下のグラフはエポック 4 ~ 6 点で損失曲線が横ばい状態になっていることを表しています。
Epoch パラメータを 4 に設定しても、同じパフォーマンスが得られます。
チューニング ジョブのステータスを確認する
チューニング ジョブのステータスは、Google AI Studio の
[マイライブラリ] タブを使用するか、metadata
Gemini API
エラーのトラブルシューティングを行う
このセクションでは、エラー発生時に発生する可能性のあるエラーの解決方法に関するヒントを紹介します。 モデルを作成します。
認証
API とクライアント ライブラリを使用してチューニングするには、ユーザー認証が必要です。API キー
単独では不十分です'PermissionDenied: 403 Request had
insufficient authentication scopes' エラーが発生した場合は、ユーザーを設定する必要があります。
あります。
Python 用の OAuth 認証情報を設定するには、OAuth のセットアップ チュートリアルをご覧ください。
キャンセルされたモデル
ファインチューニング ジョブは、ジョブが完了する前であればいつでもキャンセルできます。ただし、 キャンセルされたモデルの推論パフォーマンスは予測不可能です。 調整ジョブはトレーニングの早い段階でキャンセルされます。次の理由で解約した場合: 以前のエポックでトレーニングを停止する場合は、新しいチューニング エポックを低い値に設定します。
次のステップ
- 責任ある AI のベスト プラクティスについて学ぶ プラクティスをご覧ください。
- Python によるチューニングのクイックスタートを開始する またはチューニングのクイックスタート cURL を使用します。