
Le strategie di progettazione dei prompt, come i prompt few-shot, potrebbero non produrre sempre i risultati di cui hai bisogno. L'ottimizzazione è un processo che può migliorare la qualità del modello il rendimento su attività specifiche o permettere al modello di rispettare dei requisiti quando le istruzioni non sono sufficienti e hai una serie di esempi che dimostrano gli output che vuoi ottenere.
Questa pagina fornisce indicazioni su come ottimizzare il modello di testo alla base dell'API Gemini di testo.
Come funziona l'ottimizzazione
L'obiettivo del perfezionamento è migliorare ulteriormente le prestazioni del modello per per l'attività specifica. Il processo di ottimizzazione prevede l'addestramento del modello contenente molti esempi dell'attività. Per attività di nicchia, puoi ottenere miglioramenti significativi nelle prestazioni del modello, grazie alla sua messa a punto di esempi.
I dati di addestramento devono essere strutturati come esempi con input di prompt e gli output di risposta previsti. Puoi anche ottimizzare i modelli utilizzando direttamente i dati di esempio in Google AI Studio. L'obiettivo è insegnare al modello a imitare il comportamento desiderato o attività, fornendo molti esempi che illustrano tale comportamento o attività.
Quando esegui un job di ottimizzazione, il modello apprende parametri aggiuntivi che lo aiutano codificare le informazioni necessarie per eseguire l'attività desiderata o comportamento degli utenti. Questi parametri possono quindi essere utilizzati al momento dell'inferenza. L'output del il job di ottimizzazione è un nuovo modello, che è di fatto una combinazione parametri appresi e il modello originale.
prepara il set di dati
Prima di poter iniziare l'ottimizzazione, hai bisogno di un set di dati per ottimizzare il modello. Per le prestazioni migliori, gli esempi nel set di dati devono essere di alta qualità, diversificati e rappresentativi di input e output reali.
Formato
Gli esempi inclusi nel set di dati devono corrispondere alla produzione prevista per via del traffico. Se il set di dati contiene formattazione, parole chiave, istruzioni, o informazioni, i dati di produzione devono essere formattati nello stesso modo e contengono le stesse istruzioni.
Ad esempio, se gli esempi nel tuo set di dati includono "question:" e una proprietà
"context:", anche il traffico di produzione deve essere formattato per includere un
"question:" e "context:" nello stesso ordine in cui vengono visualizzati nel set di dati
esempi. Se escludi il contesto, il modello non può riconoscere il pattern,
anche se la domanda esatta
si trovava in un esempio nel set di dati.
Anche l'aggiunta di un prompt o un preambolo a ogni esempio nel set di dati può essere utile a migliorare le prestazioni del modello ottimizzato. Tieni presente che se un prompt o un preambolo nel set di dati, dovrebbe essere incluso anche nel prompt del modello modello al momento dell'inferenza.
Dimensione dei dati di addestramento
Puoi ottimizzare un modello con solo 20 esempi. Dati aggiuntivi migliora generalmente la qualità delle risposte. Il target deve essere compreso tra 100 e 500 esempi, a seconda dell'applicazione. La tabella seguente mostra dimensioni consigliate per i set di dati per perfezionare un modello di testo per varie attività comuni:
| Attività | N. di esempi nel set di dati |
|---|---|
| Classificazione | 100+ |
| Riassunto | 100-500+ |
| Ricerca documenti | 100+ |
Carica il tuo set di dati di ottimizzazione
I dati vengono trasmessi in linea utilizzando l'API o tramite file caricati in Google AI Studio.
Fai clic sul pulsante Importa e segui le istruzioni della finestra di dialogo per importare i dati. da un file o scegli un prompt strutturato con esempi da importare come ottimizzazione del set di dati.
Libreria client
Per utilizzare la libreria client, fornisci il file di dati nell'createTunedModel
chiamata. La dimensione massima consentita per il file è 4 MB. Consulta la guida rapida all'ottimizzazione con
Python per iniziare.
cURL
Per chiamare l'API REST utilizzando cURL, fornisci esempi di addestramento in formato JSON per
l'argomento training_data. Consulta la guida rapida all'ottimizzazione con
cURL per iniziare.
Impostazioni di ottimizzazione avanzate
Quando crei un job di ottimizzazione, puoi specificare le seguenti impostazioni avanzate:
- Epoche: un passaggio completo dell'addestramento sull'intero set di addestramento in modo che ogni è stato elaborato una volta.
- Dimensione del batch: l'insieme di esempi utilizzato in un'iterazione di addestramento. La la dimensione del batch determina il numero di esempi in un batch.
- Tasso di apprendimento:un numero in virgola mobile che indica all'algoritmo come i parametri del modello a ogni iterazione. Ad esempio, un un tasso di apprendimento pari a 0,3 regoli ponderazioni e bias il triplo in modo potente rispetto a un tasso di apprendimento pari a 0,1. I tassi di apprendimento alti e bassi hanno e devono essere adattati in base al caso d'uso.
- Moltiplicatore del tasso di apprendimento: il moltiplicatore del tasso di apprendimento modifica il valore del modello. tasso di apprendimento originale. Il valore 1 utilizza il tasso di apprendimento originale della un modello di machine learning. Valori superiori a 1 aumentano il tasso di apprendimento e valori compresi tra 1 mentre 0 abbassano il tasso di apprendimento.
Configurazioni consigliate
La tabella seguente mostra le configurazioni consigliate per l'ottimizzazione di un modello di base:
| Iperparametro | Valore predefinito | Regolazioni consigliate |
|---|---|---|
| Epoca | 5 |
Se la perdita inizia ad appiattirsi prima di 5 epoche, utilizza un valore più basso. Se la perdita è convergente e non sembra stabilizzarsi, utilizza un valore più alto. |
| Dimensione del batch | 4 | |
| Tasso di apprendimento | 0,001 | Utilizza un valore più basso per set di dati più piccoli. |
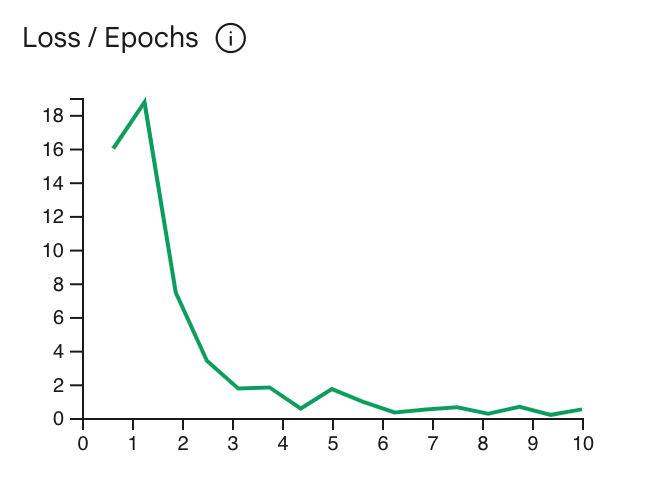
La curva di perdita mostra quanto la previsione del modello si discosta dall'ideale
le previsioni negli esempi di addestramento dopo ogni epoca. L'ideale sarebbe interrompere
l'addestramento nel punto più basso della curva, subito prima di alzarsi. Ad esempio:
il grafico seguente mostra la curva di perdita che si attenua all'incirca all'epoca 4-6, il che significa
puoi impostare il parametro Epoch su 4 e ottenere comunque lo stesso rendimento.
Controlla lo stato del job di ottimizzazione
Puoi controllare lo stato del tuo job di ottimizzazione in Google AI Studio nella sezione
La mia libreria o utilizzando la proprietà metadata del modello ottimizzato nella
dell'API Gemini.
Risolvere gli errori
Questa sezione include suggerimenti su come risolvere gli errori che potresti riscontrare durante la creazione del modello ottimizzato.
Autenticazione
L'ottimizzazione mediante l'API e la libreria client richiede l'autenticazione dell'utente. Una chiave API
da solo non è sufficiente. Se viene visualizzato un errore 'PermissionDenied: 403 Request had
insufficient authentication scopes', devi configurare l'utente
autenticazione.
Per configurare le credenziali OAuth per Python, fai riferimento alla configurazione di OAuth di Google Cloud.
Modelli annullati
Puoi annullare un job di ottimizzazione in qualsiasi momento prima del suo completamento. Tuttavia, le prestazioni di inferenza di un modello annullato sono imprevedibili, in particolare se il job di ottimizzazione viene annullato all'inizio dell'addestramento. Se hai annullato l'abbonamento perché hai interrompere l'addestramento in un'epoca precedente, devi creare una nuova ottimizzazione job e impostiamo l'epoca su un valore più basso.
Passaggi successivi
- Scopri di più sulla migliore AI responsabile pratiche.
- Inizia con la guida rapida all'ottimizzazione con Python o la guida rapida all'ottimizzazione cURL.