
Les stratégies de conception de requête, telles que les requêtes few-shot, ne produisent pas toujours dont vous avez besoin. Le réglage est un processus permettant d'améliorer des performances sur des tâches spécifiques ou aider le modèle à respecter lorsque les instructions ne sont pas suffisantes et que vous disposez d'un ensemble d'exemples qui représentent les résultats souhaités.
Cette page explique comment affiner le modèle de texte utilisé par l'API Gemini service d'envoi de SMS.
Fonctionnement de l'affinage
L'objectif de ces réglages est d'améliorer encore davantage les performances du modèle votre tâche spécifique. L'affinage consiste à fournir au modèle un ensemble de données ensemble de données contenant de nombreux exemples de la tâche. Pour les tâches de niche, vous pouvez obtenir des améliorations significatives des performances du modèle en ajustant le modèle sur un petit nombre d'exemples.
Vos données d'entraînement doivent être structurées comme des exemples avec des entrées de requête et résultats de réponse attendus. Vous pouvez aussi régler des modèles en utilisant directement les exemples de données dans Google AI Studio. L'objectif est d'apprendre au modèle à imiter le comportement souhaité. ou une tâche spécifique, en lui donnant de nombreux exemples illustrant ce comportement ou cette tâche.
Lorsque vous exécutez un job de réglage, le modèle apprend des paramètres supplémentaires qui l'aident codent les informations nécessaires pour effectuer la tâche souhaitée ou comportemental. Ces paramètres peuvent ensuite être utilisés au moment de l'inférence. La sortie de la fonction de réglage est un nouveau modèle, qui combine en fait les paramètres appris et le modèle d'origine.
Préparer votre ensemble de données
Avant de commencer l'affinage, vous avez besoin d'un ensemble de données avec lequel régler le modèle. Pour les meilleures performances, les exemples de l'ensemble de données doivent être de haute qualité, diverses et représentatives des entrées et sorties réelles.
Format
Les exemples de votre ensemble de données doivent correspondre au trafic de production attendu. Si votre ensemble de données contient une mise en forme, des mots clés, des instructions ou des informations spécifiques, les données de production doivent utiliser le même format et contenir les mêmes instructions.
Par exemple, si les exemples de votre ensemble de données incluent "question:" et "context:", le trafic de production doit également être mis en forme de manière à inclure "question:" et "context:" dans le même ordre que les exemples de l'ensembles de données. Si vous excluez le contexte, le modèle ne peut pas reconnaître le modèle,
même si la question exacte se trouvait
dans un exemple du jeu de données.
L'ajout d'une requête ou d'un préambule à chaque exemple de votre jeu de données peut également aider d'améliorer les performances du modèle réglé. Notez que si une invite ou un préambule est dans votre ensemble de données, il doit aussi être inclus dans la requête de l'éditeur au moment de l'inférence.
Taille des données d'entraînement
Vous pouvez affiner un modèle avec seulement 20 exemples. Données supplémentaires améliore généralement la qualité des réponses. Vous devez cibler entre 100 et 500 exemples, selon votre application. Le tableau suivant montre tailles d'ensemble de données recommandées pour affiner un modèle de texte pour différentes tâches courantes:
| Tâche | Nombre d'exemples dans l'ensemble de données |
|---|---|
| Classification | 100+ |
| Synthèse | 100-500+ |
| Rechercher des documents | 100+ |
Importer votre ensemble de données de réglage
Les données sont transmises de façon intégrée à l'aide de l'API ou via des fichiers importés dans Google. AI Studio.
Cliquez sur le bouton Import (Importer) et suivez les instructions de la boîte de dialogue pour importer des données. à partir d'un fichier ou choisir une requête structurée avec des exemples à importer pour le réglage ensemble de données.
Bibliothèque cliente
Pour utiliser la bibliothèque cliente, fournissez le fichier de données dans createTunedModel
. La taille du fichier ne doit pas dépasser 4 Mo. Consultez le guide de démarrage rapide pour l'optimisation
Python pour commencer.
cURL
Pour appeler l'API REST à l'aide de cURL, fournissez des exemples d'entraînement au format JSON pour
l'argument training_data. Consultez le guide de démarrage rapide pour le réglage
cURL pour commencer.
Paramètres de réglage avancés
Lors de la création d'un job de réglage, vous pouvez spécifier les paramètres avancés suivants:
- Époques:passe d'entraînement complet sur l'ensemble de l'ensemble d'entraînement de sorte que chaque a été traité une fois.
- Taille de lot:ensemble d'exemples utilisés dans une itération d'entraînement. La la taille de lot détermine le nombre d'exemples dans un lot.
- Taux d'apprentissage:nombre à virgule flottante qui indique à l'algorithme comment fortement pour ajuster les paramètres du modèle à chaque itération. Par exemple, un un taux d'apprentissage de 0,3 ajusterait les pondérations et les biais trois fois plus de manière plus puissante qu'un taux d'apprentissage de 0,1. Les taux d'apprentissage élevés et faibles ont leurs propres compromis spécifiques et doivent être ajustés en fonction de votre cas d'utilisation.
- Multiplicateur du taux d'apprentissage:le multiplicateur de taux modifie le du taux d'apprentissage d'origine. Une valeur de 1 utilise le taux d'apprentissage d'origine de la dans un modèle de ML. Une valeur supérieure à 1 augmente le taux d'apprentissage et les valeurs comprises entre 1. et 0 sur le taux d'apprentissage.
Configurations recommandées
Le tableau suivant présente les configurations recommandées pour le réglage de fondation:
| Hyperparamètre | Valeur par défaut | Ajustements recommandés |
|---|---|---|
| Époque | 5 |
Si la perte commence à stagner avant cinq époques, utilisez une valeur plus faible. Si la perte converge et ne semble pas se stabiliser, utilisez une valeur plus élevée. |
| Taille de lot | 4 | |
| Taux d'apprentissage | 0,001 | Utilisez une valeur inférieure pour les ensembles de données plus petits. |
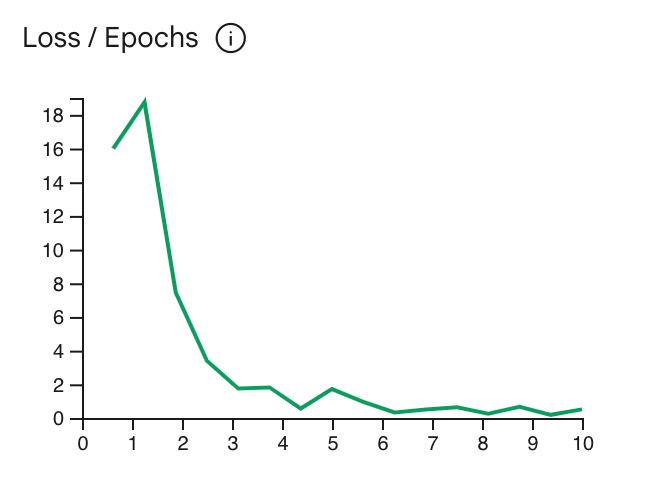
La courbe de fonction de perte montre dans quelle mesure la prédiction du modèle s'écarte de la valeur idéale
les prédictions dans les exemples d'entraînement
après chaque époque. Idéalement, vous devez arrêter
au point le plus bas de la courbe, juste avant de plafonner. Par exemple :
Le graphique ci-dessous montre que la courbe de fonction de perte se stabilise aux alentours de l'époque 4-6, ce qui signifie
vous pouvez définir le paramètre Epoch sur 4 et obtenir les mêmes performances.
Vérifier l'état du job de réglage
Vous pouvez vérifier l'état de votre job de réglage dans Google AI Studio sous la
l'onglet Ma bibliothèque ou en utilisant la propriété metadata du modèle réglé dans la
l'API Gemini.
Résoudre les erreurs
Cette section inclut des conseils sur la façon de résoudre les erreurs que vous pouvez rencontrer pour créer votre modèle réglé.
Authentification
Le réglage à l'aide de l'API et de la bibliothèque cliente nécessite une authentification de l'utilisateur. Une clé API
ne suffit pas. Si une erreur 'PermissionDenied: 403 Request had
insufficient authentication scopes' s'affiche, vous devez configurer le profil utilisateur
l'authentification unique.
Pour configurer les identifiants OAuth pour Python, consultez la configuration OAuth tutoriel.
Modèles annulés
Vous pouvez annuler une tâche d'ajustement à tout moment avant qu'elle ne soit terminée. Toutefois, les performances d'inférence d'un modèle annulé sont imprévisibles, surtout si le job de réglage est annulé au début de l'entraînement. Si vous avez résilié votre abonnement parce que vous si vous souhaitez arrêter l'entraînement à une époque antérieure, vous devez créer un autre réglage et définir l'époque sur une valeur inférieure.
Étape suivante
- Découvrez les bonnes pratiques de l'IA responsable pratiques.
- Lancez-vous à l'aide du guide de démarrage rapide pour le réglage avec Python. ou le guide de démarrage rapide cURL.