
邊緣裝置的記憶體或運算效能通常有限。您可以為模型套用各種最佳化設定,以便在這些限制內執行。此外,部分最佳化作業允許使用特殊硬體加速推論。
TensorFlow Lite 和 TensorFlow 模型最佳化工具包提供各種工具,可降低最佳化推論的複雜度。
建議您在應用程式開發過程中考慮模型最佳化。本文件概述最佳化 TensorFlow 模型以部署至邊緣硬體的最佳做法。
為什麼需要最佳化模型
模型最佳化有多種主要方式可協助您開發應用程式。
縮小
有些最佳化形式可用來縮減模型大小。小型模型有以下優點:
- 縮減儲存空間大小:較小的模型占用使用者裝置的儲存空間較少。舉例來說,採用小型模型的 Android 應用程式佔用較少使用者行動裝置儲存空間。
- 縮減下載大小:小型模型需要更少的時間和頻寬,才能下載到使用者的裝置。
- 降低記憶體用量:較小的模型在執行時會使用較少的 RAM,進而釋放記憶體供應用程式的其他部分使用,進而提高效能和穩定性。
量化可以在上述所有情況下縮減模型的大小,但可能會降低某些準確率。修剪和分群法可以簡化要下載的模型大小,輕鬆壓縮。
延遲時間縮短
延遲時間是指用特定模型執行單一推論所需的時間。有些最佳化形式可減少使用模型執行推論所需的運算量,進而縮短延遲時間。延遲時間也可能會影響耗電量。
目前,量化功能可以簡化推論期間發生的計算,進而減少延遲,但這有望犧牲某些準確率。
加速器相容性
部分硬體加速器 (例如 Edge TPU) 可透過經過正確最佳化的模型,以極快的速度執行推論。
一般來說,這類裝置的模型必須以特定方式量化。請參閱各硬體加速器的說明文件,進一步瞭解相關需求。
取捨
最佳化作業可能會導致模型準確率變更,您必須在應用程式開發過程中考量這點。
準確率變化會依正在最佳化的個別模型而定,且很難事先預測。一般來說,針對大小或延遲進行最佳化的模型 會失去少量準確率視您的應用程式而定,這不一定會影響使用者體驗。在極少數情況下,最佳化程序可能會使某些模型獲得一定的準確率。
最佳化類型
TensorFlow Lite 目前透過量化、修剪和分群法支援最佳化。
這些是 TensorFlow 模型最佳化工具包的一部分,可提供與 TensorFlow Lite 相容的模型最佳化技術資源。
量化
量化的運作方式是降低代表模型參數的數字精確度,根據預設為 32 位元浮點數。這樣可以縮減模型大小,並加快運算速度。
TensorFlow Lite 提供以下類型的量化:
| 做法 | 資料條件 | 縮小 | 準確 | 支援的硬體 |
|---|---|---|---|---|
| 訓練後的 float16 量化 | 沒有資料 | 50% 以內 | 準確度微損失 | CPU、GPU |
| 訓練後的動態範圍量化 | 沒有資料 | 75% 以內 | 準確度最低的損失 | CPU、GPU (Android) |
| 訓練後的整數量化 | 未加上標籤的代表性樣本 | 75% 以內 | 準確度偏低 | CPU、GPU (Android)、EdgeTPU |
| 量化感知訓練 | 為訓練資料加上標籤 | 75% 以內 | 準確度最低的損失 | CPU、GPU (Android)、EdgeTPU |
以下決策樹狀圖可協助您根據預期的模型大小和準確率,選取適合模型使用的量化配置。
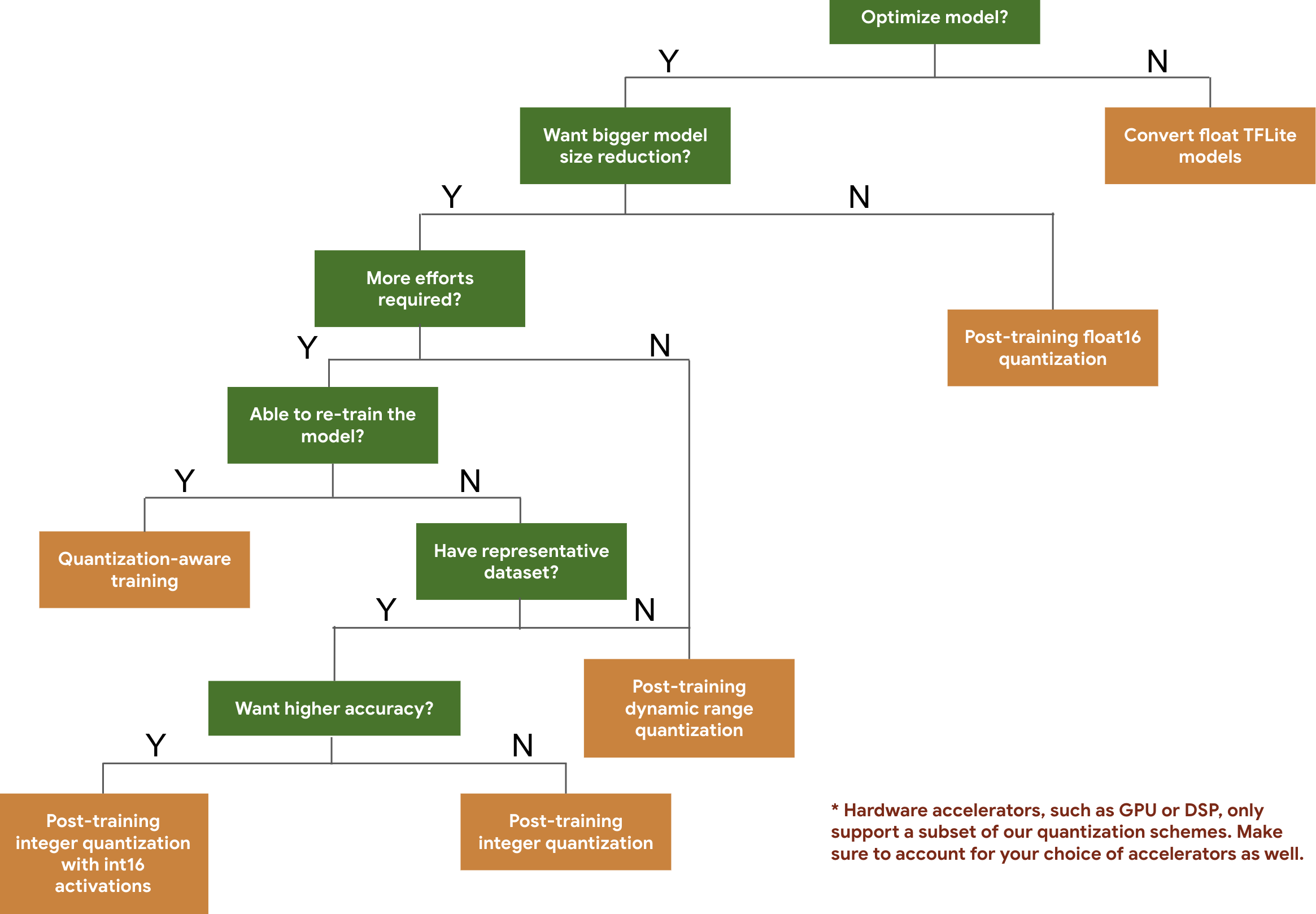
以下是一些模型的訓練後量化及量化感知訓練的延遲和準確率結果。所有延遲時間數字都是在搭載單一大型核心 CPU 的 Pixel 2 裝置上計算而得。隨著工具包不斷進步
| 模型 | 前 1 名準確率 (原始) | 一級準確率 (訓練後量化) | 1 大準確率 (量化感知訓練) | 延遲時間 (原始) (毫秒) | 延遲時間 (訓練後量化) (毫秒) | 延遲時間 (量化感知訓練) (毫秒) | 大小 (原始) (MB) | 大小 (最佳化) (MB) |
|---|---|---|---|---|---|---|---|---|
| Mobilenet-v1-1-224 | $709 美元 | $657 美元 | 0.70 | 124 | 112 | 64 | 16.9 | 4.3 |
| Mobilenet-v2-1-224 | $719 美元 | 0.637 | $709 美元 | 89 | 98 | 54 | 14 | 3.6 |
| Inception_v3 | 78 萬 | 0.772 | 775 萬 | 1130 | 845 | 543 | 95.7 | 2,390 |
| Resnet_v2_101 | $770 美元 | $768 美元 | 不適用 | 3973 | 2868 | 不適用 | 178.3 | 歐元 |
具有 int16 啟動項目和 int8 權重的完整整數量化
透過 int16 啟動的量化是完整的整數量化配置,具有 int16 中的啟動項目以及在 int16 中啟用的權重。相較於完整整數量化配置,這個模式可在 int8 中保留相似的模型大小,進而提高量化模型的準確度。如果啟動項目對量化敏感,則建議使用上述做法。
注意:TFLite 目前只有未最佳化的參考核心實作項目適用於這個量化配置,因此根據預設,與 int8 核心相比,效能會比較慢。這個模式的所有優點目前只能透過特殊的硬體或自訂軟體存取。
以下是部分可受益於此模式的模型的準確率結果。
| 模型 | 準確率指標類型 | 準確度 (float32 啟用) | 準確度 (int8 啟用) | 準確率 (int16 啟用項目) |
|---|---|---|---|---|
| Wav2letter | WER | 6.7% | 7.7% | 7.2% |
| DeepSpeech 0.5.1 (展開) | CER | 6.13% | 43.67% | 6.52% |
| YoloV3 | mAP(IOU=0.5) | $577 美元 | 563 萬 | 574 萬 |
| MobileNetV1 | 1 大準確率 | $7062 美元 | 歐元 | 0.6936 |
| MobileNetV2 | 1 大準確率 | $718 美元 | 0.7126 | 0.7137 |
| MobileBert | F1(完全比對) | 88.81(81.23) | 2.08(0) | 88.73(81.15) |
修枝鋸
「修剪」的運作方式是移除模型中只對預測產生輕微影響的參數。修剪後模型在磁碟上的大小相同,而且執行階段延遲時間也相同,但可以更有效率地壓縮模型。如此便可縮減模型下載大小,是實用的技術。
日後,TensorFlow Lite 將為縮減的模型提供延遲。
分群
分群的運作原理是將模型中每個層的權重組成一組預先定義的叢集,然後分享屬於個別叢集的權重群集值。這會減少模型中不重複權重值的數量,進而降低模型的複雜度。
因此,叢集模型能夠更有效率地進行壓縮,提供與修剪類似的部署優勢。
開發工作流程
一開始,請檢查託管模型中的模型是否適用於您的應用程式。如果沒有,我們建議使用者先使用訓練後量化工具,因為這項工具廣泛適用,也不需要訓練資料。
如果未達準確率和延遲時間目標,或是硬體加速器支援很重要,則量化感知訓練是更好的選項。請參閱 TensorFlow 模型最佳化工具包中的其他最佳化技術。