
エッジデバイスでは、メモリや演算能力が限られていることがよくあります。これらの制約内でモデルを実行できるように、さまざまな最適化をモデルに適用できます。さらに、一部の最適化では、専用ハードウェアを使用して推論を高速化できます。
TensorFlow Lite と TensorFlow モデル最適化ツールキットには、推論の最適化の複雑さを最小限に抑えるツールが用意されています。
アプリケーション開発プロセス中にモデルの最適化を検討することをおすすめします。このドキュメントでは、エッジ ハードウェアにデプロイするために TensorFlow モデルを最適化するためのベスト プラクティスの概要について説明します。
モデルの最適化が必要な理由
モデルの最適化がアプリケーション開発に役立つ主な方法はいくつかあります。
サイズの削減
いくつかの形式の最適化を使用して、モデルのサイズを縮小できます。小さいモデルには次のような利点があります。
- ストレージ サイズが小さい: モデルが小さいほど、ユーザーのデバイスの占める保存容量が少なくなります。たとえば、Android アプリのサイズが小さいほど、ユーザーのモバイル デバイスで消費されるストレージ容量が少なくなります。
- ダウンロード サイズの削減: モデルが小さいほど、ユーザーのデバイスにダウンロードするために必要な時間と帯域幅が少なくなります。
- メモリ使用量が少ない: サイズが小さいモデルでは、実行時の RAM の使用量が少なくなるため、アプリケーションの他の部分で使用するメモリが解放され、パフォーマンスと安定性が向上します。
量子化は、これらすべてのケースでモデルのサイズを縮小できますが、精度が犠牲になる可能性があります。プルーニングとクラスタリングにより圧縮が容易になり、ダウンロードするモデルのサイズを縮小できます。
レイテンシの短縮
レイテンシは、特定のモデルで 1 回の推論を実行するのにかかる時間です。最適化の形式によっては、モデルを使用して推論を実行するために必要な計算量を減らし、レイテンシを短縮できます。レイテンシも消費電力に影響する可能性があります。
現在は、量子化を使用して推論中に行われる計算を簡素化することでレイテンシを短縮できますが、これにはある程度の精度が犠牲になることがあります。
アクセラレータの互換性
Edge TPU などの一部のハードウェア アクセラレータは、正しく最適化されたモデルを使用して推論を非常に高速に実行できます。
一般に、このタイプのデバイスでは、モデルを特定の方法で量子化する必要があります。要件の詳細については、各ハードウェア アクセラレータのドキュメントをご覧ください。
トレードオフ
最適化によりモデルの精度が変化する可能性があります。アプリケーション開発プロセスでこれを考慮する必要があります。
精度の変化は最適化される個々のモデルによって異なり、事前に予測することは困難です。一般に、サイズまたはレイテンシが最適化されたモデルでは、精度がわずかに低下します。アプリケーションによって、この操作がユーザー エクスペリエンスに影響する場合と影響しない場合があります。まれに、最適化プロセスの結果として特定のモデルの精度が向上することがあります。
最適化の種類
TensorFlow Lite は現在、量子化、プルーニング、クラスタリングによる最適化をサポートしています。
これらは TensorFlow Model Optimization Toolkit の一部です。このツールキットは、TensorFlow Lite と互換性のあるモデル最適化手法のリソースを提供します。
量子化
量子化では、モデルのパラメータを表す数値(デフォルトでは 32 ビット浮動小数点数)の精度を下げることで量子化を行います。これにより、モデルサイズが小さくなり、計算速度が向上します。
TensorFlow Lite では、次の量子化を使用できます。
| 技術 | データ要件 | サイズの削減 | 精度 | サポートされているハードウェア |
|---|---|---|---|---|
| トレーニング後の float16 の量子化 | データなし | 最大 50% | 精度が大幅に低下 | CPU、GPU |
| トレーニング後のダイナミック レンジ量子化 | データなし | 最大 75% | 最小の精度損失 | CPU、GPU(Android) |
| トレーニング後の整数量子化 | ラベルのない代表サンプル | 最大 75% | 精度の低下が小さい | CPU、GPU(Android)、EdgeTPU |
| 量子化認識トレーニング | ラベル付けされたトレーニング データ | 最大 75% | 最小の精度損失 | CPU、GPU(Android)、EdgeTPU |
次のディシジョン ツリーは、予想されるモデルのサイズと精度に基づいて、モデルに使用する量子化スキームを選択するのに役立ちます。
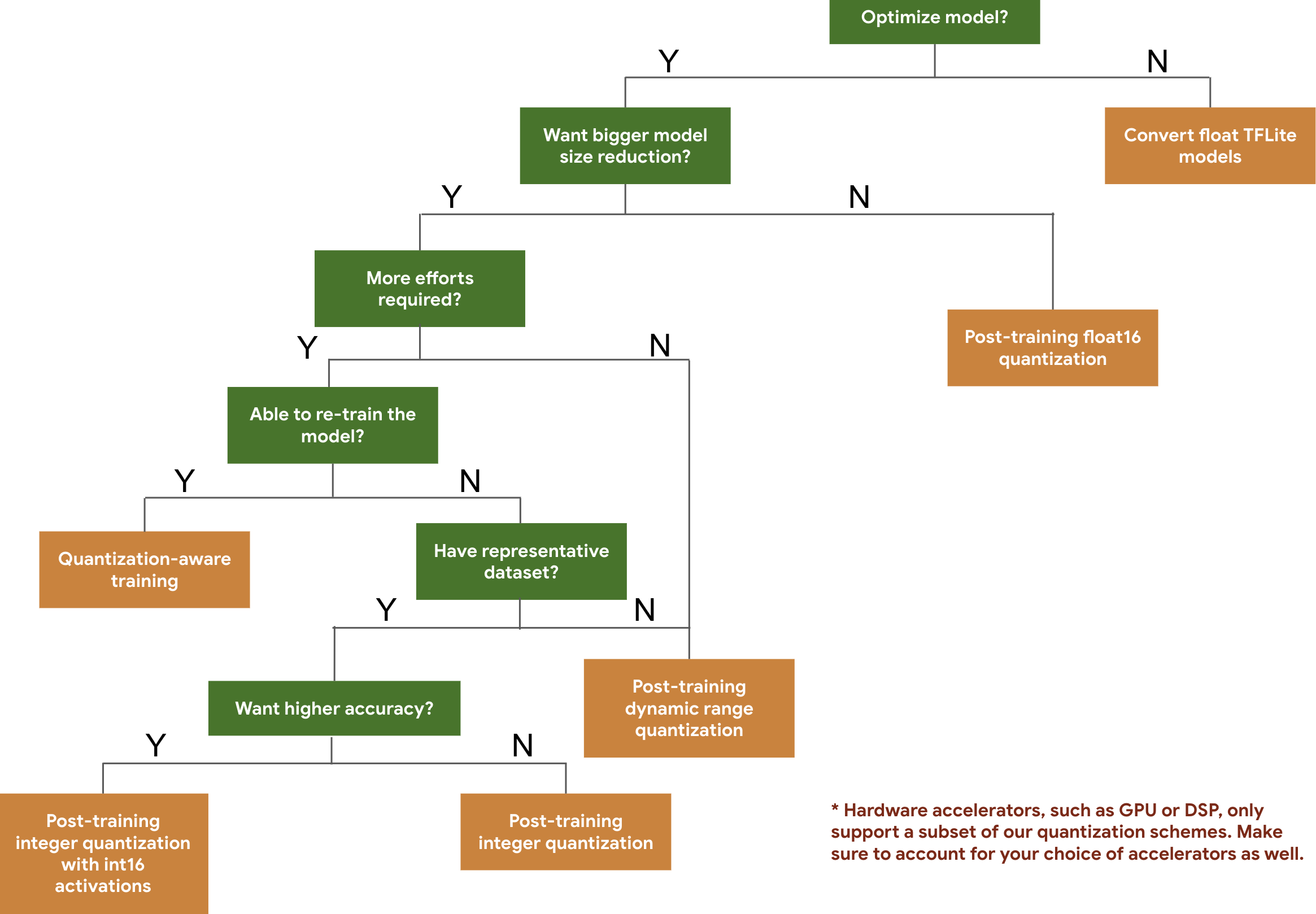
以下に、いくつかのモデルでのトレーニング後の量子化と量子化認識トレーニングのレイテンシと精度の結果を示します。すべてのレイテンシの数値は、単一の大きなコア CPU を使用する Pixel 2 デバイスで測定されています。ツールキットが改善するにつれ この数値も向上します
| モデル | トップ 1 の精度(オリジナル) | トップ 1 の精度(トレーニング後の量子化) | トップ 1 の精度(量子化認識トレーニング) | レイテンシ(オリジナル)(ミリ秒) | レイテンシ(量子化トレーニング後)(ミリ秒) | レイテンシ(量子化認識トレーニング)(ミリ秒) | サイズ(オリジナル)(MB) | サイズ(最適化)(MB) |
|---|---|---|---|---|---|---|---|---|
| Mobilenet-v1-1-224 | 709 万台 | 657 万台 | 0.70 | 124 | 112 | 64 | 1,690 万台 | 4.3 |
| Mobilenet-v2-1-224 | 719 万台 | 637 万台 | 709 万台 | 89 | 98 | 54 | 14 | 3.6 |
| Inception_v3 | 0.78 | 0.772 | 775 万台 | 1130 | 845 | 543 | 9,570 万台 | 2,390 万台 |
| Resnet_v2_101 | 770 万台 | 768 万台 | なし | 3973 | 2868 | なし | 1,783 | 4,490 |
int16 活性化と int8 重みによる完全な整数量子化
int16 活性化による量子化は、int16 の活性化と int8 の重みを持つ完全な整数量子化スキームです。このモードでは、int8 の活性化と重みの両方が同じモデルサイズを維持している完全な整数量子化スキームと比較して、量子化モデルの精度が向上します。活性化が量子化の影響を受けやすい場合におすすめします。
注: 現在、この量子化スキームの TFLite では、最適化されていないリファレンス カーネル実装のみを使用できるため、デフォルトでは、int8 カーネルと比較してパフォーマンスが遅くなります。現在、このモードのすべてのメリットには、専用のハードウェアまたはカスタム ソフトウェアを介してアクセスできます。
このモードの恩恵を受ける一部のモデルの精度の結果を以下に示します。
| モデル | 精度の指標タイプ | 精度(float32 活性化) | 精度(int8 アクティベーション) | 精度(int16 アクティベーション) |
|---|---|---|---|---|
| Wav2letter | WER | 6.7% | 7.7% | 7.2% |
| DeepSpeech 0.5.1(展開済み) | CER | 6.13% | 43.67% | 6.52% |
| YoloV3 | mAP(IOU=0.5) | 577 万台 | 563 万台 | 574 万台 |
| MobileNetV1 | トップ 1 の精度 | 0.7062 | 694 万台 | 0.6936 |
| MobileNetV2 | トップ 1 の精度 | 718 万台 | 0.7126 | 0.7137 |
| MobileBert | F1(完全一致) | 88.81(81.23) | 2.08(0) | 88.73(81.15) |
枝刈り
プルーニングは、モデルの予測への影響がわずかなパラメータを削除することで機能します。プルーニングされたモデルは、ディスク上では同じサイズで、ランタイム レイテンシも同じですが、より効果的に圧縮できます。このため、プルーニングはモデルのダウンロード サイズを削減するための有用な手法となります。
将来的には、TensorFlow Lite によって、プルーニングされたモデルのレイテンシが短縮される予定です。
クラスタリング
クラスタリングは、モデル内の各レイヤの重みを事前定義されたクラスタ数にグループ化し、各クラスタに属する重みのセントロイド値を共有することで機能します。これにより、モデル内の一意の重み値の数が減り、複雑さが軽減されます。
その結果、クラスタ化されたモデルの圧縮効率が向上し、プルーニングと同様のデプロイ上のメリットが得られます。
開発ワークフロー
まず、ホストされているモデルのモデルがアプリケーションで使用できるかどうかを確認します。それ以外の場合は、トレーニング後の量子化ツールを使用することをおすすめします。このツールは幅広く適用可能で、トレーニング データを必要としないためです。
精度とレイテンシの目標が満たされていない場合や、ハードウェア アクセラレータのサポートが重要な場合は、量子化認識トレーニングをおすすめします。TensorFlow Model Optimization Toolkit でその他の最適化手法を確認する。