Theoretical Paper
- Computer Organization
- Data Structure
- Digital Electronics
- Object Oriented Programming
- Discrete Mathematics
- Graph Theory
- Operating Systems
- Software Engineering
- Computer Graphics
- Database Management System
- Operation Research
- Computer Networking
- Image Processing
- Internet Technologies
- Micro Processor
- E-Commerce & ERP
Practical Paper
Industrial Training

Architecture of Database Systems
"Architecture of Database Systems"
12.1 Introduction
Software systems generally have an architecture, ie. possessing of a structure (form) and organisation (function). The former describes identifiable components and how they relate to one another structurally; the latter describes how the functions of the various structural components interact to provide the overall functionality of the system as a whole. Since a database system is basically a software system (albeit complex), it too possesses an architecture. A typical architecture must define a particular configuration of and interaction between data, software modules, meta-data, interfaces and languages (see Figure 12-1).
The architecture of a database system determines its capability, reliability, effectiveness and efficiency in meeting user requirements. But besides the visible functions seen through some data manipulation language, a good database architecture should provide:
a) Independence of data and programs
b) Ease of system design
c) Ease of programming
d) Powerful query facilities
e) Protection of data
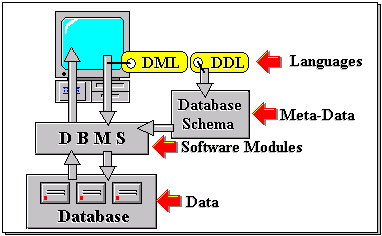
Figure 12-1: General database system architecture
The features listed above become especially important in large organisations where corporate data are held centrally. In such situations, no single user department has responsibility over, nor can they be expected to know about, all of the organisation’s data. This becomes the job of a Database Administrator (DBA) who has a daunting range of responsibilities that include creating, expanding, protecting and maintaining the integrity of all data while adressing the interests of different present and future user communities. To create a database, a DBA has to analyse and assess the data requirements of all users and from these determine its logical structure (database schema). This, on the one hand, will need to be efficiently mapped onto a physical structure that optimises retrieval performance and the use of storage. On the other, it would also have to be mapped to multiple user views suited to the respective user applications. For large databases, DBA functions will in fact require the full time services of a team of many people. A good database architecture should have features that can significantly facilitate these activities.
12.2 Data Abstraction
To meet the requirements above, a more sophisticated architecture is in fact used, providing a number of levels of data abstraction or data definition. The database schema, also known as Conceptual Schema, mentioned above represents an information model at the logical level of data definition. At this level, we abstract out details like computer storage structures, their restrictions, or their operational efficiencies. The view of a database as a collection of relations or tables, each with fixed attributes and primary keys ranging over given domains, is an example of a logical level of data definition.
The details of efficiently organising and storing objects of the conceptual schema in computers with particular hardware configurations are dealt with at the internal (storage) level of data definition. This level is also referred to as the Internal Schema. It maps the contents of the conceptual schema onto structures representing tuples, associated key organisations and indexes, etc, taking into account application characteristics and restrictions of a given computer system. That is, the DBA describes at this level how objects of the conceptual schema are actually organised in a computer. Figure 12-2 illustrates these two levels of data definition.
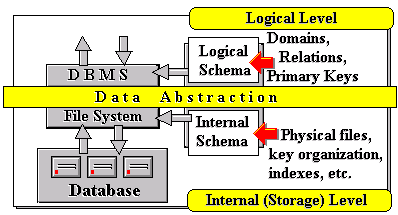
Figure 12-2: The logical and internal levels of data abstraction
At a higher level of abstraction, objects from the conceptual schema are mapped onto views seen by end-users of the database. Such views are also referred to as External Schemas. An external schema presents only those aspects of the conceptual schema that are relevant to the particular application at hand, abstracting out all other detaiils. Thus, depending on the requirements of the application, the view may be organised differently from that in the conceptual schema, eg. some tables may be merged, attributes may be suppressed, etc. There may thus be many views created - one for each type of application. In contrast, there is only one conceptual and one internal schema. All views are derived from the same conceptual schema. This is illustrated in Figure 12-3 which shows two different user views derived from the same conceptual schema.
Thus, modern database systems support three levels of data abstraction: External Schemas (User Views), Conceptual Schema, and Internal (Storage) Schema.
The DDL we discussed in earlier chapters is basically a tool only for conceptual schema definition. The DBA will therefore usually need special languages to handle the external and internal schema definitions. The internal schema definition, however, varies widely over different implementation platforms, ie. there are few common principles for such definition. We will therefore say little more about them in this book.
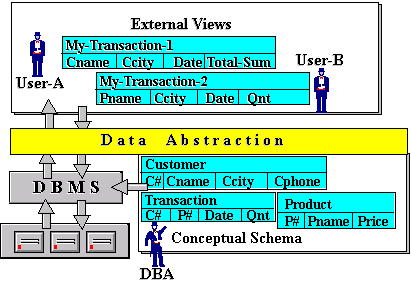
Figure 12-3: User views (external schema)
As to external schema definitions, note that in the relational model, the Data Sub- Languages can be used to both describe and manipulate data. This is because the expressions of a Data Sub-Language themselves denote relations. Thus, a collection of new (derived) relations can be defined as an external schema.
For example, suppose the following relations are defined:
Customer( C#, Cname, Ccity, Cphone )
Product( P#, Pname, Price )
Transaction( C#, P#, Date, Qnt )
We can then define an external view with a construct like the following:
Define View My_Transaction_1 As
Select Cname, Ccity, Date, Total_Sum=Price*Qnt From Customer, Transaction, Product Where Customer.C# = Transaction.C# & Transaction.P# = Product.P#
which defines the relation (view):
My_Transaction_1( Cname, Ccity, Date, Total_Sum )
This definition effectively maps the conceptual database structure into a form more convenient for a particular user or application. The extension of this derived table is itself derived from the extensions of the source relations. This is illustrated in Figure 12-4 below.
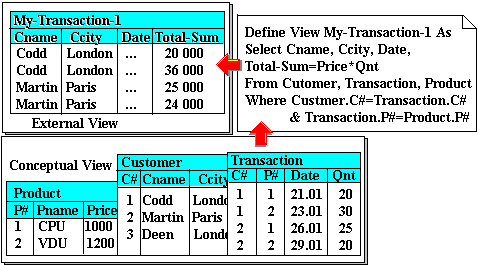
Figure 12-4: External view definition
This is a very important property of the relational data model: a unified approach to data definition and data manipulation.
12.3 Data Administration
Functions of a DBA include:
- Creation of the database
To create a database, a DBA has to analyse and assess the requirements of the users and from these determine its logical structure. In other words, the DBA has to design a conceptual schema and a first variant of an internal schema. When the internal schema is ready, the DBA must load the database with actual data. - Acting as intermediary between users and the database
A DBA is responsible for all user facilities determined by external schemas, ie. the DBA is responsible for defining all external schemas or user views. - Ensuring data privacy, integrity and security
In analysing user requirements, a DBA must determine who should have access to which data and subsequently arrange for appropriate privacy locks (passwords) for identified individuals and/or groups. The DBA must also determine integrity constraints and arrange for appropriate data validation to ensure that such constraints are never violated. Last, but not least, the DBA must make arrangements for data to be regularly backed up and stored in a safe place as a measure against unrecoverable data losses for one reason or another.
At first glance, it may seem that a database can be developed using the conventional "waterfall" technique. That is, the development process is a sequence of stages, with work progressing from one stage to the next only when the preceding stage has been completed. For relational database development, this sequence will include stages like eliciting user requirements, analysing data relationships, designing the conceptual schema, designing the internal schema, loading the database, defining user views and interfaces, etc, through to the deployment of user facilities and database operations.
In practice, however, when users start to work with the database, the initial requirements inevitably change for a number of reasons including experience gained, a growing amount of data to be processed, and, in this fast changing world, changes in the nature of the business it supports. Thus, a database need to evolve, learning from experience and allowing for changes in requirements. In particular, we may expect periodic changes to: