
LINEでClovaの開発をしている上村です。これはLINE Advent Calendar 2017の13日目の記事です。今日は文字列の話をします。
はじめに
与えられた文字列によく似たものを大きな文字列集合から探すということは、古典的でありふれていながら奥が深く難しい問題です。文字列の類似度を正確に見積もるには複雑な計算が必要ですが、膨大な量のコーパスが与えられたときも可能な限り高速に応答を返す必要があります。
検索する文字列の性質をよく把握することも、品質のよい類似文字列検索を行うためには極めて大切です。ここで、今回考える問題の例を見てみます。

この例では、1文字ずつ違いを見つけ出したり、単語単位で見たり、文全体が疑問文や否定文であるかどうかを調べ、それらを総合的に見ることで最終的な判断を下しています。文字だけを見た場合、1文字の違いによって全く違う単語になることは見つけられませんし、単語単位で考えても、活用形のわずかな違いで文全体の意味が真逆になってしまうことを知るのは難しいです。かといって疑問文や否定文であるかを大局的に判断するだけでは、文字や単語の細かな違いを見逃してしまいます。このように、文字列の類似性を測るには、さまざまな観点が必要となり得ます。
また、上記のような例をうまく解くことができたとしても、同じ手法を異なる検索対象にそのまま適用できるとは限りません。多くのユーザーや大量のコンテンツ、頻繁なコミュニケーションを扱うようなサービスでは、例えば以下のような要求が考えられます。
- 人名や愛称等の単語:同音異義語や表記揺れを吸収できるか
- 曲名や歌手名等のフレーズ:単語の抜けや誤りを許容できるか
- 決まった命令や簡単な雑談等の短い文:全体として意味の合う文を見つけられるか
短い文字列の類似性を求めることが簡単とは限らず、むしろ単語単位の処理を前提とする洗練された手法の多くが適用できなくなる場合もあります。すべての可能な文字列に対する究極の類似度を定義するのは、現在のところ困難であるといえるでしょう。
Resemblaは、このように複雑で多岐にわたる問題に取り組むため、以下の2点に主眼を置いて開発している類似文字列検索ライブラリです。
- 文字列の性質に合わせた尺度の選択と組み合わせによる品質の改善
- 候補の絞り込みとコーパスの前処理による速度の向上
ここからは、Resemblaのアーキテクチャとアルゴリズム、および実装の概要を説明します。
https://github.com/tuem/resembla
アーキテクチャ
用いる尺度によって細部の構成は異なりますが、短い文を対象として類似度計算を行う場合の典型的な例を以下に示します。
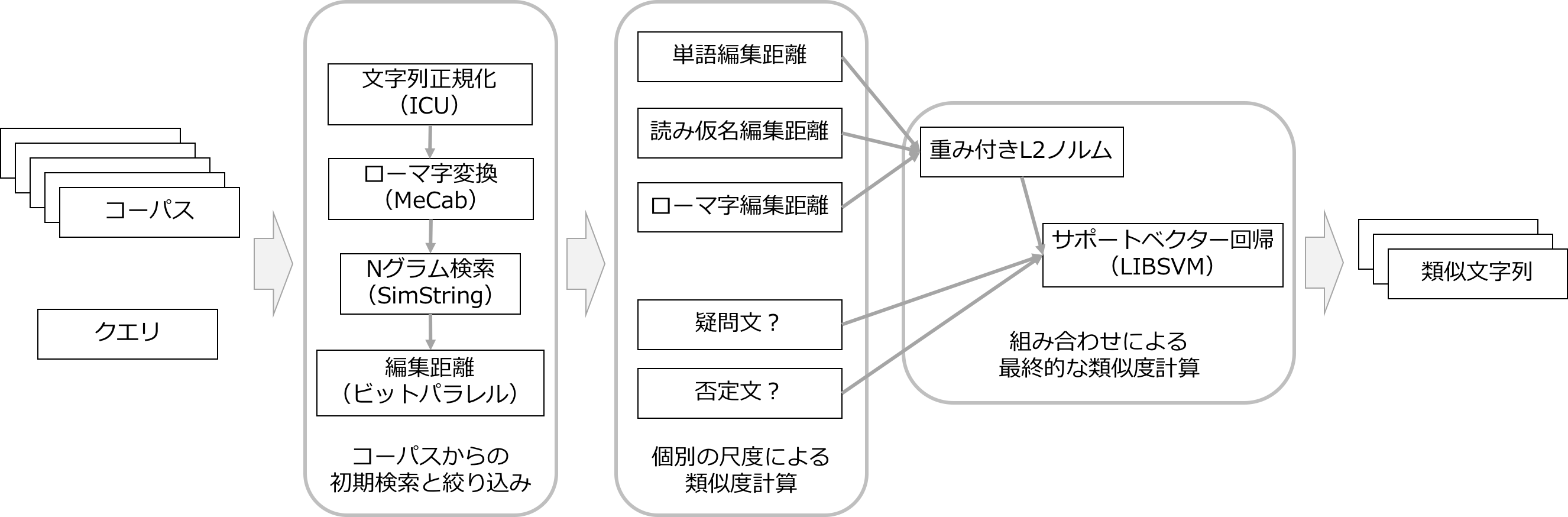
全体の流れ
検索したい文字列が与えられたとき、大きく分けて以下のような流れで類似文字列を計算します。
- コーパスからの検索
- 候補の絞り込み
- 類似度の計算
全体として、より高速な手法で候補を絞り込んでいき、より精度の高い手法を適用するという方針をとっています。
コーパスからの検索と候補の絞り込み
コーパスを保持するデータベースとして、日本語1文字単位のNグラムに基づいた検索をサポートするSimStringを用います。まずコーパス中の全文字列から、文字Nグラムの集合に基づいた尺度を用いて、一定以上の類似度を持つ文字列をすべて列挙します。異表記や読みの違い等による検索漏れを減らすため、元の文字列そのものではなく、読み仮名やローマ字表記にした状態でNグラム索引を構築・利用することもできます。変換のために用いる形態素解析器はMeCabです。ICUを用いた正規化をコーパスとクエリに適用することもできます。
クエリによっては、この時点で多くの文字列が候補として列挙されてしまうことがあるので、次の段階の絞り込みを行います。ビットパラレル法を用いた編集距離により、後段の各尺度よりも格段に速く類似度を求められます。
最終的な類似度計算で編集距離ベースの手法を用いる場合、経験的に、この段階で得られた類似度順の文字列リストからそれほど大きくは変動しないことがわかっています。そのため、Nグラム検索で閾値やNの値をある程度緩く設定した上で絞り込みを積極的に行えば、検索漏れを少なく抑えながら計算時間の削減が期待できます。
類似度の計算
2つの文字列に対して類似度を計算するとき、尺度によっては多くの計算が必要です。しかしコーパス中の各文字列に対しては、事前に前処理を行うことで、クエリが与えられたときの計算を減らせる場合があります。これを一般化するため、類似度の計算を以下の2つに分けます。
- 前処理関数
- 類似度関数
前処理関数は、例えば形態素解析や何らかの重み付け等、類似度の計算対象となる文字列を何らかの型に変換する関数です。類似度関数は、前処理関数によって変換された後の2つの値を受け取り、その類似度を返す関数です。前処理の内容は後段の類似度関数によって異なりますが、例えば以下のようなものがあります。
- 形態素解析
- 読み仮名やローマ字表記への変換
- 各要素への重み付け
尺度によって前処理の結果得られるデータは異なりますが、これらをネイティブな型でメモリ上に直接保持するため、クエリが与えられたとき、そのクエリ自体に対してのみ前処理を行えば、コーパス中の各候補との類似度を計算できます。
結果の組み合わせ
複数の類似度関数を組み合わせることで最終的な類似度を得ることもできます。例えば単語や短いフレーズの場合、文字単位の尺度とローマ字表記の尺度を併用することが考えられます。複数の尺度を用いればそれだけ時間がかかりますが、コーパスのサイズや実際の検証に基いて前段の絞り込みを適切に行い、最終的な尺度を適用する対象を十分少なくできれば、全体の計算時間に占める割合を低く抑えることができます。
アルゴリズム
2つの文字列の類似度を計算するためのよく知られた尺度である編集距離は汎用性の高い手法ですが、入力される文字列に何らかの性質が仮定できるならば、よりよい尺度を与えられる可能性があります。
Resemblaでは現在のところ以下の尺度を用いることができます。
- 文字単位(通常)の編集距離
- 単語単位の編集距離
- 読み仮名の編集距離
- ローマ字表記の編集距離
まだ実験段階ですが、以下の機能も開発を進めています。
- 単語の分散表現を用いた編集距離
- 単語の分散表現から得た文の分散表現の距離
また、複数の尺度を組み合わせて最終的な類似度を計算することもできます。
- 重み付きL2ノルム
- サポートベクター回帰
サポートベクター回帰では、編集距離のような尺度の他、疑問文かどうか、否定文かどうかといった言語的な特性を素性として扱います。このような素性の計算には、正規表現によるパターン照合と、LIBSVMによるサポートベクターマシンを用いることができます。
コスト関数と重み付けを導入した編集距離
通常の編集距離の場合、挿入・削除・置換にそれぞれ固定の値が割り当てられますが、これを拡張して、より柔軟に文字列の類似性を測れるようにします。コスト関数はある文字を別の文字に置換する際のコスト、すなわち2つの文字の異なり度合いを返す関数です。重みはオプションで、挿入・削除・置換のいずれかが行われたときコストに乗じる値です。置換以外の操作にも影響する他、同じ要素に対して異なる値を割り当てることもできます。例えばローマ字表記に対する編集距離では、"M"と"N"のように比較的似ている文字同士の置換コストを相対的に低く設定したり、母音と子音で重みを変えたりして利用します。
単語単位の編集距離
単語単位の編集距離では、単語同士のコスト関数と、単語に対する重みを用いて、類似度を計算します。コスト関数は、表層文字列の一致や読み仮名の一致、単語間の各文字の一致数を用いて計算しています。重みは品詞情報と文字列長に基いて割り当てています。対象とする入力が短い文である場合、単語単位での尺度を用いることで、比較的重要度の低い助詞の不一致を吸収する等して、名詞や動詞等を重視した上で編集距離ベースの類似度計算を行うことができます。
読み仮名およびローマ字表記の編集距離
自然言語を扱うとき、単語単位の処理は多くの場面で有効ですが、チャットや音声のようなインターフェースの場合、スペルミスや音声認識誤りの影響が無視できず、正しい単語として解釈されないという問題があります。特にクエリが短い場合、その影響が類似度計算に顕著な影響を及ぼすこともあり、十分注意が必要です。このような現象を軽減するため、元の文字列を読み仮名に変換し、読み仮名1文字単位に重み付けした上で編集距離を計算したり、さらにローマ字表記に変換して編集距離を計算したりできます。
ここまで挙げた手法を比べると、ローマ字表記、読み仮名、文字、単語の順に、小さな粒度で文字列を解釈していると見ることができます。直観的には短い文字列ほど小さな粒度で見るのが良さそうですが、他の手法との組み合わせで精度が上がることも多く、最終的には対象となる文字列に合わせて調整することになります。
実装
ResemblaはC++11で開発していますが、実装を進めるうちに構成要素が増えたことでコードが複雑化したため、性能を犠牲にせず作業を効率化するための工夫をいくつか導入しました。
フレームワーク
新たな尺度を導入したり、それを既存の尺度と組み合わせたりする際、余分なコードを極力書くことなく、データベースからの検索や絞り込み最終的な結果の出力までを実装するため、テンプレートと継承を併用したクラス構成をとっています。
具体的には、まず純粋仮想関数によって定義したインターフェース(resembla_interface.hpp)を定義し、次にそれをテンプレートクラス(basic_resembla.hpp)で継承します。ここまでがResemblaの基本的なフレームワークです。最後に個別の尺度を実装して、テンプレートクラスをインスタンス化します。前処理済みデータの型はテンプレート引数から定まるので、コーパスに対する前処理関数の結果をフレームワークで保持し、類似度関数で再利用できます。
また、個別の尺度の組み合わせ(resembla_ensemble.hpp)も、このインターフェースを実装した上で、メンバー変数として同インターフェースのインスタンスを複数保持・利用します。これにより、個別の尺度を任意に組み合わせて構築した新たな尺度も、単一のインターフェースで同様に利用できます。
編集距離
編集距離ベースの尺度はedit_distance.hppによって実装しています。コスト関数として任意の関数オブジェクトを渡す構造をとり、類似度を測る対象の型はテンプレートによって定義されるので、charのような通常の文字型の他、単語とその品詞情報を表す構造体、単語の分散表現等、任意の型の列に対して、カスタマイズしたコスト関数を用いて編集距離を計算できます。重み付きの系列に対する実装weighted_edit_distance.hppも構造は同様です。
パラメーター管理
Resemblaでは、評価実験やデプロイを円滑に行ったり、索引構築と検索サーバーのパラメーターを共通化したりするため、パラメーター毎に以下の3つを順に適用して最終的な値を得ています。
- デフォルト値
- JSONファイル
- コマンドライン引数
当初はJSON for Modern C++とcmdlineを用いてパラメーター毎にJSONとコマンドラインからの読み込みを書いていましたが、早々にパラメーターが100を超えそうなことがわかり、上記のパラメーター管理・設定機能を提供するライブラリとして開発しました。
https://github.com/tuem/paramset
paramsetを用いることで、各パラメーターに対して定義を1行だけ記述すれば、JSONファイルからの読み込みとコマンドライン引数による上書きをサポートできます。また、パラメーターの参照時は文字列型だけでなく、intやboolとして安全に取得できます。
gRPC
実際の応用ではさまざまな言語とのインターフェースが求められる場合がありますが、パフォーマンスや型安全性といった点でgRPCは有力な選択肢の1つです。example/grpcに最低限の類似文字列検索機能を実装したgRPCサンプルアプリケーションを置いていますので、参考にしてみてください。
おわりに
作り始めたものの一向に完成する気配がないのはよくある話としても、ソースコード以外の資料がほぼ存在しないのはいかがなものかと思い、この機会に紹介記事を書かせてもらいました。
全体的な進捗としては、アーキテクチャが概ね固まりつつあるものの、アルゴリズムはまだ改善・追加を続けていく必要があり、実装やパラメーターの最適化はまだまだこれから、といったところです。現在はまだ未完成の機能や拙い実装も多く、動かしながら必要になった機能を積み上げている状況ですが、今後も改善を続けていきたいと思います。
明日はezuraさんの「Swift 4.1+」です。お楽しみに。