
こんにちは。LINEの小林滉河(@kajyuuen)です。NLPチームで固有表現抽出、有害表現の検知、LINEスタンプ推薦の改善など自然言語処理に関する仕事をしています。
この記事ではLINEが公開した言語モデル「LINE DistilBERT」について紹介します。
- https://huggingface.co/line-corporation/line-distilbert-base-japanese
- https://github.com/line/LINE-DistilBERT-Japanese
LINE DistilBERTは次のような特徴を持つ日本語言語モデルです。
- 高性能・高速・軽量
- Hugging Faceのtransformersから簡単に利用可能
- 商用利用可能なApache License 2.0でのモデル配布
このモデルは、大規模日本語Webコーパスを用いたモデル構築により、日本語自然言語理解のベンチマークであるJGLUEの全てのタスクにおいて、Laboro DistilBERTやBandaiNamco DistilBERTといった既存の日本語DistilBERTを超える性能を実現しています。
LINE DistilBERTは特に次のようなエンジニア・研究者におすすめのモデルです。
- 事前学習にかかる時間を短くして、実験のイテレーションを多く回したい方
-
高速な推論速度が必要な方
-
スマートフォンなどの限られた計算資源の中で言語モデルを動かしたい方
次項では、LINE DistilBERTの詳細と様々な自然言語処理タスクにおける評価について詳しく紹介していきたいと思います。
使い方
説明の前にLINE DistilBERTを使いたい方は、以下のようなコードで簡単に利用できます。
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("line-corporation/line-distilbert-base-japanese", trust_remote_code=True)
model = AutoModel.from_pretrained("line-corporation/line-distilbert-base-japanese")
sentence = "LINE株式会社で[MASK]の研究・開発をしている。"
print(model(**tokenizer(sentence, return_tensors="pt")))詳細
背景・目的
近年、BERTやRoBERTaのような大規模言語モデルが自然言語処理におけるデファクトスタンダードになっています。これらのモデルは様々な自然言語処理タスクを高い精度で解くことができます。しかし、大規模言語モデルは1億以上のパラメーターを有していることが殆どであり、fine-tuningに必要な計算コストが高く、推論速度は遅いといった問題を抱えています。これらの問題を解決するため、パラメーターサイズを落としながら計算量・計算コストを削減する手法の研究開発が進んでいます。
現在、LINEではパラメーターサイズが小さいモデルを使うことは殆ど無いのですが、要素技術の研究開発として、蒸留を用いてパラメーターサイズを削減する方法について検証を行いました。蒸留とは教師モデル(パラメーターサイズが大きいモデル)の出力を生徒モデル(パラメーターサイズが小さい)が再現できるように学習を行うことで、パラメーターサイズを削減する手法であり、蒸留をBERTに適用したものがDistilBERTになります。
検証の結果、開発したDistilBERTが既存の日本語DistilBERTより性能が高く、社内で眠らせておくには勿体ないモデルであったため、「LINE DistilBERT」として公開するに至りました。
LINE DistilBERTについて
LINE DistilBERTは高性能で使いやすいモデルを提供するための様々な工夫を行っています。その中で特徴的な取り組みを2つ紹介します。
1つ目は大量のデータ学習に使用したことです。LINE DistilBERTでは性能向上のため、教師モデルの構築と蒸留に用いるデータにLINEが独自で構築した大規模日本語Webコーパスを利用しています。具体的なコーパスサイズですが、教師モデルは約2TB、蒸留時には約130GBのコーパスを使っています。日本語BERTモデルの構築時によく利用される、日本語Wikipediaから作成したコーパスは大体3~4GB程度です。したがって、今回蒸留に利用したデータは非常に大きいと言えると思います。
2つ目はDistilBertJapaneseTokenizerの実装です。LINE DistilBERTのトークナイズでは、MeCab+UniDicによる分かち書き後、SentencePieceによるサブワード化を行います。これらの処理をtransformersで行うには`transformers.BertJapaneseTokenizer`トークナイザーとして利用する必要がありますが、この返り値はモデルである`transformers.DistilBertModel`の引数と一致しません。トークナイザーの出力とモデルの引数が一致しない場合、transformersのPipelinesを始めとする様々なAPIの恩恵を受け取ることができません。そこでLINE DistilBERTでは`BertJapaneseTokenizer`の出力を`DistilBertModel`の入力に合わせる、`DistilBertJapaneseTokenizer`を作成しました。これによって、次のようにPipelinesによるモデル推論を簡単に試すことができます。
from transformers import pipeline
unmasker = pipeline('fill-mask', model='line-corporation/line-distilbert-base-japanese', trust_remote_code=True)
print(unmasker("LINE株式会社で[MASK]の研究・開発をしている。"))
# => [{'score': 0.16280120611190796,
# 'token': 2120,
# 'token_str': 'アプリ',
# 'sequence': 'line 株式 会社 で アプリ の 研究 ・ 開発 を し て いる 。'},
# {'score': 0.08093959093093872,
# 'token': 8853,
# 'token_str': 'ai',
# 'sequence': 'line 株式 会社 で ai の 研究 ・ 開発 を し て いる 。'},
# ...}]実験
以下ではJGLUEに基づいて、性能の評価と推論速度の評価を行いました。JGLUEは文章分類、文ペア分類、QAの3種類タスクを6つのデータセットでモデルを言語理解能力を測定するベンチマークです。
まず本実験では用いたモデルについて下記の表で示します。東北大BERT-baseはDistilBERTに比べ、パラメーター数が多いモデルですが、性能比較のために利用させていただきました。
|
Model |
Model Type |
Num Layers |
Num Parameters |
Model File Size† |
Vocab Size |
|---|---|---|---|---|---|
|
LINE DistilBERT |
DistilBERT |
6 |
68.1M |
270MB |
32768 |
|
Laboro DistilBERT |
DistilBERT |
6 |
67.5M |
270MB |
32000 |
|
BandaiNamco DistilBERT |
DistilBERT |
6 |
67.5M |
273MB |
32000 |
|
東北大 BERT-base†† |
BERT-base |
12 |
111.2M |
447MB |
32768 |
†: Model Hubのpytorch_model.binから算出
††: cl-tohoku/bert-base-japanese-v2
性能評価
性能評価ではハイパーパラメータによる、性能の違いが出ないよう、バッチサイズ={16, 32}, 学習率={2e-5, 3e-5, 5e-5}, エポック数={2, 3, 4}の設定でグリッドサーチを行いました。以下が各モデルのJGLUEのdevセットに対する性能です。
|
Model |
Model File Size |
Marc_ja |
JNLI |
JSTS |
JSQuAD |
JCommonSenseQA |
||
|---|---|---|---|---|---|---|---|---|
|
acc |
acc |
Pearson |
Spearman |
EM |
F1 |
EM |
||
|
LINE DistilBERT |
262MB |
95.6 |
88.9 |
89.2 |
85.1 |
87.3 |
93.3 |
76.1 |
|
Laboro DistilBERT |
270MB |
94.7 |
82.0 |
87.4 |
82.7 |
70.2 |
87.3 |
73.2 |
|
BandaiNamco DistilBERT |
273MB |
94.6 |
81.6 |
86.8 |
82.1 |
80.0 |
88.0 |
66.5 |
|
東北大 BERT(参考) |
447MB |
95.8 |
92.5 |
89.9 |
86.1 |
87.1 |
94.4 |
80.8 |
実験の結果、LINE DistilBERTはJGLUEの全てのタスクにおいて、他のDistilBERTよりも性能が高いことが確認できました。またBERT-baseである東北大BERTと比較して、モデルサイズが41%小さいにも関わらず、全てのタスクにおいて94%以上の性能を実現しています。
平均推論速度
次にCPUとGPU環境における平均推論速度について実験を行いました。この実験ではJGLUEの各タスクにおいて、データ一件に対する平均推論時間を計測します。バッチサイズは32です。これらの計測はブレを少なくするために三回行い、その平均を最終結果として利用しています。
まずCPU、MacBook Pro 14 M1 Max (10-core CPU, 24-core GPU, 16-core neural engine)での実験結果を下に記します。

このグラフにおいて、縦軸はデータ一件に対する推論速度(単位はms)、横軸はJGLUEのタスクを表しています。つまり、ここでは棒グラフが低いほど、推論速度が早いことを示しています。DistilBERTであるLINE DistilBERT、Laboro DistilBERT、BandaiNamco DistilBERTの推論速度は、ほぼ同じであることが分かります。さらに、DistilBERTのグループ全体は、東北大BERTのBERT-baseよりも約1.9~4.0倍程度速く推論できることが確認されました。
続いてはGPU、A100 40GBによる推論速度の結果になります。
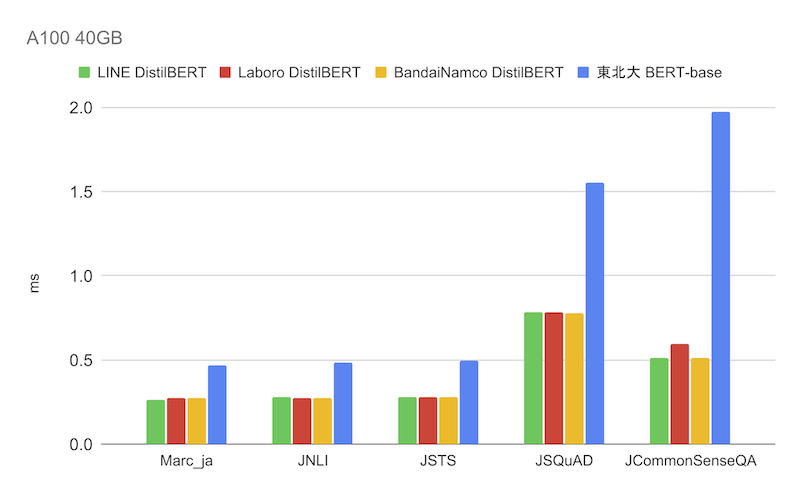
GPUを使用した実験でも、DistilBERTのグループはCPUとほぼ同じ傾向を示しており、東北大BERTの約1.8~3.8倍の推論速度が確認できます。
おわりに
本記事では、当社が開発したLINE DistilBERTの解説と、具体的な実験結果について紹介しました。このモデルは、Hugging Faceのtransformersから利用でき、学習・推論にかかるコストも少ないため、ぜひ気軽にお試しいただければと思います。
またLINE株式会社は言語処理学会第29回年次大会(NLP2023)のプラチナスポンサーとして参加しています。LINEでの自然言語処理の活用に関心のある方は、ぜひスポンサーブースにお立ち寄りください。
参考文献
- Sanh Victor, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter, arXiv preprint arXiv:1910.01108.
- Kentaro Kurihara, Daisuke Kawahara, and Tomohide Shibata. 2022. JGLUE: Japanese General Language Understanding Evaluation. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pages 2957–2966, Marseille, France. European Language Resources Association.