Containers and Kubernetes deliver portability on standardized infrastructure, and today Oracle supports databases running in containers; they’ve also released container build files and images and helm charts to simplify provisioning. What is missing for the next level of integration is support for lifecycle operations and an extension of the Kubernetes API to the primitives needed for database management.
In addition, fully managed or autonomous services for Oracle may not make available all the required features, such as Active Data Guard, Multitenant, and In-Memory, parameters/flags, versions, and patch levels. DBAs also find themselves locked out of many roles, including sysadmin and root. These restrictions make many cloud architects fall back to lift and shift Oracle databases onto infrastructure as a service offerings and miss out on opportunities to modernize and transform database operations. And with transactional databases growing in number and criticality, organizations are struggling to deliver innovation and modernization. Engineers are already busy keeping up with sprawl and mundane operational tasks while adhering to strict change management processes.
How do we solve this database operations gap?
El Carro solves this. It is built with scalability in mind, using the same container orchestration infrastructure, Kubernetes, that powers many businesses and is a top choice for modern architectures. Its open API allows you to manage your database configurations as declarative code, enabling CI/CD or Gitops workflows for auditability and control mechanisms. El Carro automates many database lifecycle operations, like backups, replication, and patching. And, when it distributes databases on the nodes of a cluster, it is aware of the priority and resource requirements of each database to optimize tight packing while respecting quality of service. Lastly, it helps DBAs by delivering automation without restrictions and leaving DBAs in full control over their systems. You can choose to let the operator drive for you, but you can also take over the steering wheel yourself at any time.Because Kubernetes is now the standard for portable infrastructure automation and orchestration, engineers appreciate how Kubernetes abstracts complex problems into manageable infrastructure as code. Kubernetes can scale from small projects to large projects that support the infrastructure that powers Google products and services for billions of users around the world. Moreover, Google pioneers the next generation of infrastructure as code that we refer to as Configuration as Data to declaratively establish a contract between developer intent and the runtime operation. According to the Cloud Native Survey 2020, two-thirds of respondents were either already running stateful workloads in production or were considering doing so within the next 12 months. We expect that datastores are going to drive the next wave of enterprise Kubernetes adoption.
A number of open source operators for databases, such as PostgreSQL, MySQL, and many others, have been released, are actively maintained by the community, and are popular among developers and architects looking for a hands-off approach to manage databases with their applications. El Carro extends the list of database operators to include Oracle.
What are we building with El Carro for Oracle databases?
The operator pattern emerged in late 2016 as an extension of the Kubernetes API and control loop aimed at automating more complicated and application-specific tasks that are beyond the native Kubernetes objects.El Carro implements a custom resource definition (CRD), which is tailored to database management. Users set and change attributes of the custom resource using the Kubernetes API the same way they do for built-in objects such as pods, deployments, or services. The El Carro controller observes changes to the CRs and compares the declared state with the current reality in the cluster, then makes the necessary changes. Those changes could either affect the Kubernetes resources used by the database such as persistent volumes or the pod itself, or may result in issuing calls via SQL or command line tools to the database to create and modify users or other database objects.
Here’s a look at how this works:
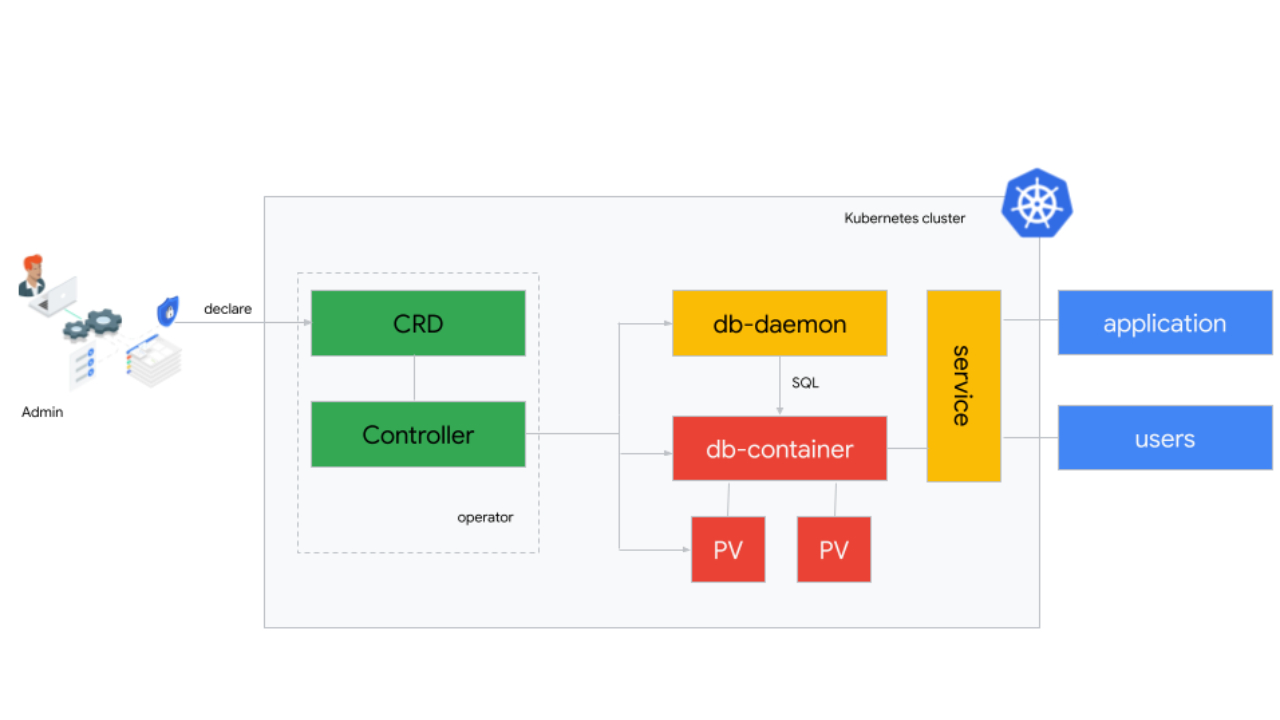
El Carro Architecture
The diagram above shows how the major components of a database managed by the El Carro Operator interact with each other. The controller monitors the CRD for any changes made by admins. It creates and manages the cluster resources that make up the actual database deployment: persistent volumes for filesystems and data, a pod to run containers with the actual database, and a daemon that allows the controller to securely run SQL commands on the database. And lastly, a service makes sqlnet connections available to applications and end users that can either run in the same Kubernetes cluster or outside of it.
At release time, the El Carro Operator can provision Oracle databases of 12c Enterprise Edition and 18c Express Edition. It manages instance parameters, pluggable databases, and users. You can take and restore backups either using rman or storage snapshots, and we are working to add additional features.
At release time, the El Carro Operator can provision Oracle databases of 12c Enterprise Edition and 18c Express Edition. It manages instance parameters, pluggable databases, and users. You can take and restore backups either using rman or storage snapshots, and we are working to add additional features.
How to get involved with El Carro?
In the development process, we collaborated with users and partners in the Oracle community to help us validate the approach. "Pythian has helped Oracle users to automate and optimize the operations of their mission-critical systems for over 20 years,” says Simon Pane, principal consultant at Pythian. “We are excited about the possibilities that El Carro brings to users on their cloud modernization journeys. We are proud to work with the community on a vision for the future of database management.".Sean Scott covers Docker for databases on his blog oraclesean.com, and says: "There are many benefits to running Oracle databases in containers. Adding Kubernetes orchestration introduces new opportunities to bring the DevOps and Oracle communities together."
You can try out El Carro today. Follow the quick start guide and try out provisioning of instances, databases, users. Import data via Data Pump, manage instance parameters, choose between different methods for backups, and try out a restore. Have a look at how we integrate with external logging and monitoring solutions. Reach out via our Google group and leave feedback for what features you would like to see next, or even create your own patch and pull request on GitHub.





 buttons to our
buttons to our 
