Implante e gerencie esse serviço para produzir relatórios resumidos da API Attribution Reporting ou da API Private Aggregate.
Implante e gerencie um serviço de agregação para processar os dados agregáveis do API Attribution Reporting ou a API Private Aggregate para criar um relatório de resumo.
Status da implementação
- O serviço de agregação agora está em disponibilidade geral.
- O serviço de agregação pode ser testado com a API Attribution Reporting e API Private Aggegration para API Protected Audience e Armazenamento compartilhado.
A explicação descreve termos-chave, úteis para entender o serviço de agregação.
Disponibilidade
| Proposta | Status |
|---|---|
| Suporte ao serviço de agregação da Amazon Web Services (AWS) na API Attribution Reporting e na API Private Aggregate
Explainer |
Disponível |
| Suporte ao serviço de agregação do Google Cloud na API Attribution Reporting e na API Private Aggregate Explainer |
Disponível na versão Beta |
| Registro do site do serviço de agregação e mapeamento de um site para contas de nuvem (AWS ou GCP) Perguntas frequentes no GitHub |
Disponível |
| O valor de épsilon do serviço de agregação será mantido como um intervalo de até 64 para facilitar a experimentação e o feedback sobre diferentes parâmetros.
Envie feedback sobre Épsilon ARA. Envie feedback sobre épsilon do PAA. |
Disponível. Avisaremos o ecossistema com antecedência antes que os valores do intervalo épsilon sejam atualizados. |
| Filtragem de contribuição mais flexível para consultas do serviço de agregação
Explainer |
Prevista no 2o trimestre de 2024 |
| Processo para recuperação de orçamento após desastres (erros, configurações incorretas etc.)
Problema no GitHub |
Prevista no 2o trimestre de 2024 |
| Accenture operando como um dos coordenadores na AWS
Blog para desenvolvedores |
Disponível |
| Parte independente que opera como um dos coordenadores do Google Cloud
Blog para desenvolvedores |
Prevista no 3o trimestre de 2024 |
Processamento de dados seguro
O serviço de agregação descriptografa e combina os dados coletados dos relatórios agregáveis, adiciona ruído e retorna o relatório de resumo final. Esse serviço é executado em um ambiente de execução confiável (TEE), implantado em um serviço de nuvem que oferece suporte às medidas de segurança necessárias para proteger esses dados.
O código do TEE é o único local no serviço de agregação que tem acesso e os relatórios brutos, esse código poderá ser auditado por pesquisadores de segurança, defensores e adtechs. Para confirmar que o TEE está executando a operação exata e que os dados permaneçam seguros, um coordenador realiza o atestado.
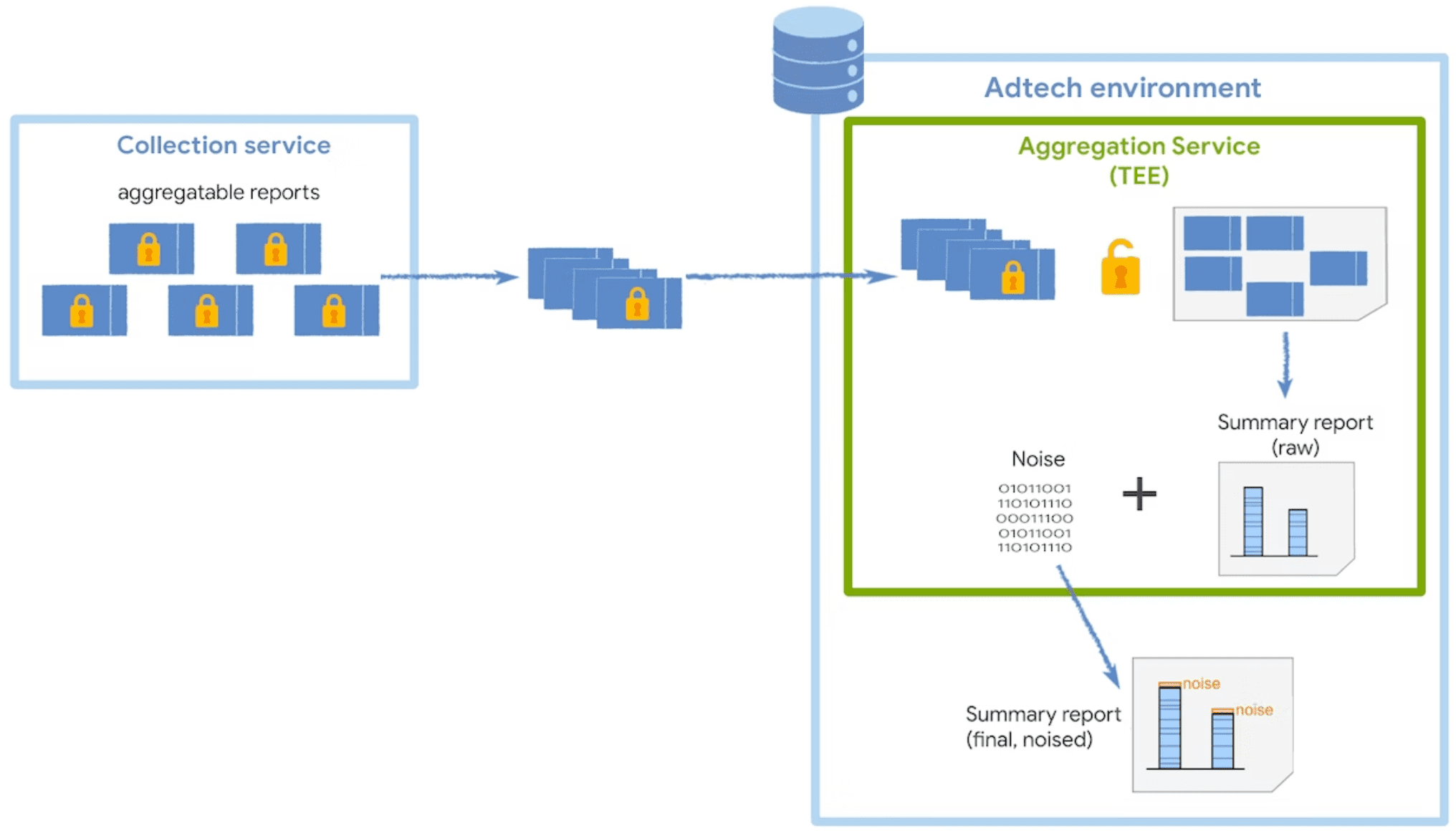
Atestado do coordenador do TEE
O coordinador é uma entidade responsável pelo gerenciamento de chaves e pelo contabilização de relatórios.
Um coordenador tem várias responsabilidades:
- Manter uma lista de imagens binárias autorizadas. Essas imagens são hashes criptográficos dos builds de software do serviço de agregação, que o Google vai lançamento. Isso será reproduzível para que qualquer parte possa verificar as imagens são idênticos aos builds do serviço de agregação.
- Opera um sistema de gerenciamento de chaves. As chaves de criptografia são necessárias para a no dispositivo de um usuário para criptografar relatórios agregáveis. As chaves de descriptografia são necessário para provar que o código do serviço de agregação corresponde às imagens binárias.
- Rastrear os relatórios agregáveis para evitar a reutilização na agregação para fins de resumo já que a reutilização pode revelar informações de identificação pessoal (PII).
"Nenhuma cópia" regra
Para ter insights sobre o conteúdo de um relatório agregável específico, um o invasor pode fazer várias cópias do relatório e incluí-las em um em um ou vários lotes. Por isso, o serviço de agregação aplica "nenhuma duplicata" regra:
- Em um lote: um relatório agregável só pode aparecer uma vez em um lote.
- Entre lotes: os relatórios agregáveis não podem aparecer em mais de um lote nem contribuir para mais de um relatório de resumo.
Para isso, o navegador atribui um ID compartilhado a cada relatório agregável.
O navegador gera o ID compartilhado a partir de vários pontos de dados, incluindo: API
versão, origem do relatório, site de destino, hora de registro da fonte e
a hora do relatório programado. Esses dados vêm da
shared_info no relatório.
O serviço de agregação confirma que todos os relatórios agregáveis com os mesmos o ID compartilhado está no mesmo lote e informa ao coordenador O ID foi processado. Se vários lotes forem criados com o mesmo ID, somente um lotes podem ser aceitos para agregação, e outros lotes são rejeitados.
Ao realizar uma execução de depuração, a opção "sem duplicatas" não é aplicada aos lotes. Em outras palavras, de lotes anteriores podem aparecer em uma execução de depuração. No entanto, a regra é aplicadas em um lote. Assim, você testa o serviço e várias estratégias de lotes, sem limitar o processamento futuro em uma ambiente de produção.
Ruído e escalonamento
Para proteger a privacidade do usuário, o serviço de agregação aplica uma mecanismo de ruído aditivo aos dados brutos dos relatórios agregáveis. Isso significa que uma certa quantidade o ruído estatístico é adicionado a cada valor agregado antes de sua liberação relatório de resumo.
Embora você não esteja no controle direto de como o ruído é adicionado, é possível influenciam o impacto do ruído nos dados de medição.

O valor do ruído é extraído aleatoriamente de uma Distribuição de probabilidade de Laplace e a distribuição é a mesma, independentemente da quantidade de dados coletados em relatórios agregáveis. Quanto mais dados você coletar, menor será o impacto do ruído sobre os resultados do relatório resumido. É possível multiplicar o relatório agregável usando um fator de escalonamento para reduzir o impacto do ruído.
Para entender como o ruído é adicionado, seus controles e o impacto na sua consulte o Orçamento de contribuição e Escalonar para orçamento de contribuição em Como trabalhar com ruído.
Gerar relatórios resumidos
A geração do relatório de resumo depende do uso da API. Saiba mais sobre gerar relatórios de resumo para o API Private Aggregate e a API Attribution Reporting.
Testar o serviço de agregação
Recomendamos a leitura do guia correspondente a cada API que você está testando:
Para testar o serviço de agregação, confira nossos codelabs:
Uma ferramenta de teste local também está disponível para processar relatórios agregáveis da API Attribution Reporting e da API Private Aggregate.
O framework de teste de carga do serviço de agregação (em inglês) oferece uma sugestão de framework.
Interaja e compartilhe feedback
O serviço de agregação é uma parte essencial das APIs de medição do Sandbox de privacidade. Assim como outras APIs do Sandbox de privacidade, ela é documentada e discutida publicamente no GitHub.
- Suporte ao serviço de agregação: leia a explicação, faça perguntas, envie feedback sobre a implementação e participe da discussão. Se precisar de mais ajuda, entre em contato com nosso alias de suporte.
- Suporte ao desenvolvedor do Sandbox de privacidade: faça perguntas e participe de discussões no repositório de suporte ao desenvolvedor do Sandbox de privacidade.