Déployez et gérez ce service afin de générer des rapports récapitulatifs pour l'API Attribution Reporting ou l'API Private Aggregation.
Déployer et gérer un service d'agrégation pour traiter les données agrégables des rapports API Attribution Reporting ou l'API Private Aggregation pour créez un rapport récapitulatif.
État d'implémentation
- Le service d'agrégation est désormais en disponibilité générale.
- Le service d'agrégation peut être testé à l'aide de la classe API Attribution Reporting et API Private Aggegration pour les API Protected Audience et Shared Storage.
La vidéo explicative présente termes clés, utiles pour comprendre le service d'agrégation.
Disponibilité
| Proposition | État |
|---|---|
| Compatibilité du service d'agrégation pour Amazon Web Services (AWS) via l'API Attribution Reporting et l'API Private Aggregation
Explication |
Disponible |
| Compatibilité du service d'agrégation pour Google Cloud via l'API Attribution Reporting et l'API Private Aggregation Explication |
Disponible en version bêta |
| Enregistrement et mappage d'un site via un service d'agrégation avec des comptes cloud (AWS ou GCP) Questions fréquentes sur GitHub |
Disponible |
| La valeur epsilon du service d'agrégation sera conservée sous la forme d'une plage allant jusqu'à 64, afin de faciliter l'expérimentation et l'envoi de commentaires sur différents paramètres.
Envoyez vos commentaires sur l'ARA epsilon. Envoyez vos commentaires sur PAA epsilon. |
Disponible. Nous informerons l'écosystème avant la mise à jour des valeurs de la plage epsilon. |
| Filtrage des contributions plus flexible pour les requêtes du service d'agrégation Explication |
Prévision 2e trimestre 2024 |
| Processus de récupération budgétaire post-catastrophes (erreurs, erreurs de configuration, etc.)
Problème GitHub |
Prévision 2e trimestre 2024 |
| Accenture faisant partie des coordinateurs sur AWS Blog des développeurs |
Disponible |
| Organisme indépendant agissant en tant que coordinateur sur Google Cloud
Blog des développeurs |
Prévision 3e trimestre 2024 |
Traitement sécurisé des données
Le service d'agrégation déchiffre et combine les données collectées à partir des rapports agrégables, ajoute du bruit, puis renvoie le rapport récapitulatif final. Ce service s'exécute dans un environnement d'exécution sécurisé (TEE), qui est déployé sur un service cloud qui applique les mesures de sécurité nécessaires pour protéger ces données.
Le code du TEE est le seul endroit du service d'agrégation qui a accès à des rapports bruts : ce code pourra être audité par des chercheurs en sécurité, et les technologies publicitaires. Pour vérifier que le TEE exécute la version logiciel et que les données restent sécurisées, un coordinateur procède à une attestation.
<ph type="x-smartling-placeholder">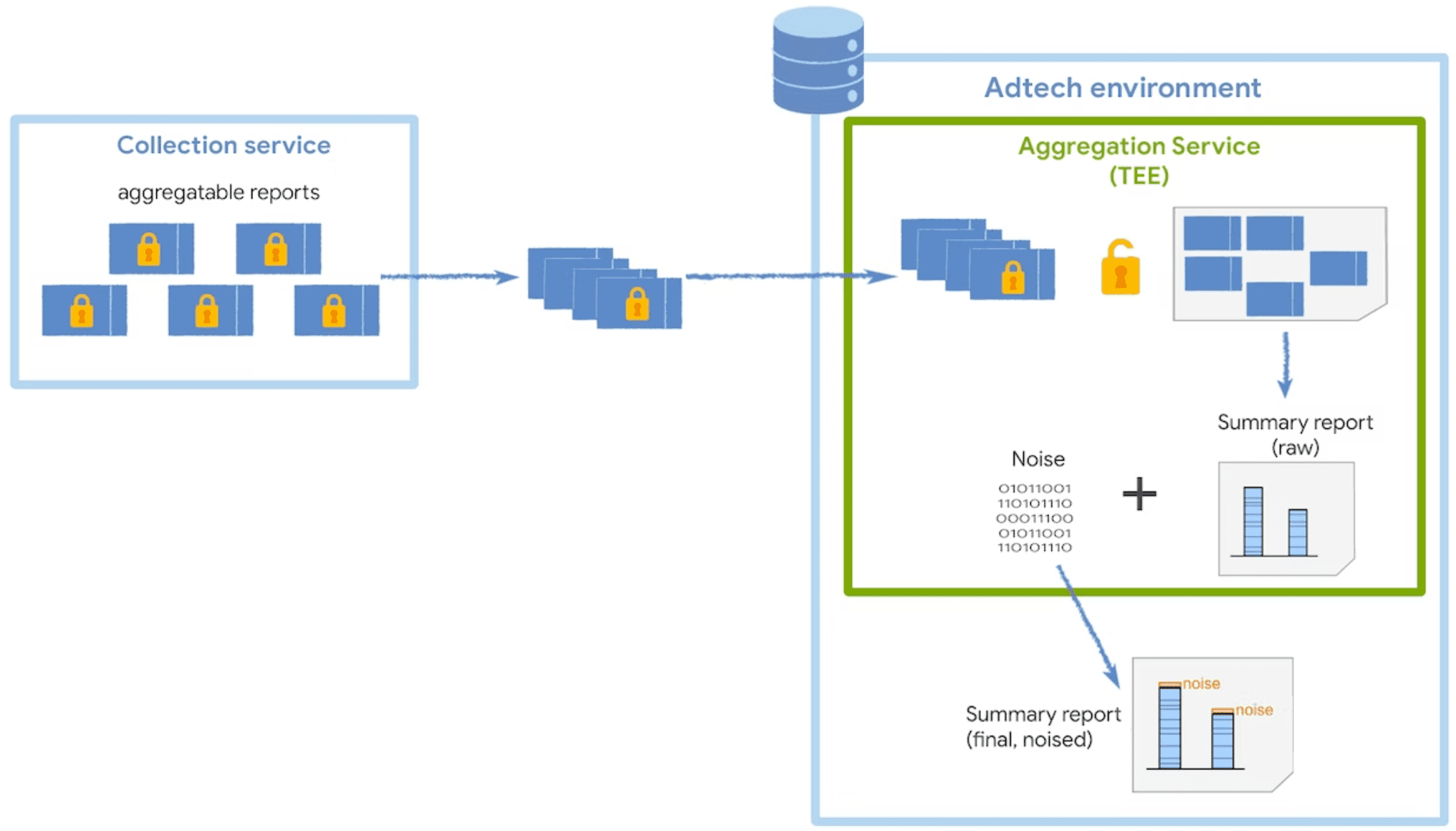
Attestation du coordinateur du TEE
Le coordonnateur est une entité responsable de la gestion des clés et de l'agrégation la traçabilité des rapports.
Un coordinateur a plusieurs responsabilités:
- Gérez une liste des images binaires autorisées. Ces images sont hachages cryptographiques des versions logicielles du service d'agrégation, que Google effectuera régulièrement de sortie. Cela permettra à n'importe quelle partie de vérifier les images. sont identiques aux builds du service d'agrégation.
- exploiter un système de gestion des clés ; Les clés de chiffrement sont requises pour sur l'appareil d'un utilisateur pour chiffrer les rapports agrégables. Les clés de déchiffrement nécessaire pour prouver que le code du service d'agrégation correspond aux images binaires.
- Suivre les rapports agrégables pour éviter de les réutiliser dans l'agrégation pour le récapitulatif car leur réutilisation peut révéler des informations permettant d'identifier personnellement l'utilisateur.
"Aucun doublon" règle
Pour mieux comprendre le contenu d'un rapport agrégable spécifique, une le pirate informatique peut faire plusieurs copies du rapport et les inclure dans un un ou plusieurs lots. Pour cette raison, le service d'agrégation applique une "aucun doublon" d'entrée:
- Dans un lot: un rapport agrégable ne peut apparaître qu'une seule fois dans un lot.
- Sur les lots: les rapports agrégables ne peuvent pas apparaître dans plusieurs lots ni contribuer à plusieurs rapports récapitulatifs.
Pour ce faire, le navigateur attribue à chaque rapport agrégable un ID partagé.
Le navigateur génère l'ID partagé à partir de plusieurs points de données, y compris: l'API
version, origine du rapport, site de destination, date et heure d'enregistrement de la source, et
l'heure du rapport planifié. Ces données proviennent
shared_info du rapport.
Le service d'agrégation vérifie que tous les rapports agrégables présentant la même d'ID partagé se trouvent dans le même lot et indique au coordinateur que l'ID partagé La pièce d'identité a été traitée. Si plusieurs lots sont créés avec le même identifiant, un seul peut être accepté pour l'agrégation, et les autres lots sont rejetés.
Lorsque vous effectuez un débogage, l'option « aucun doublon » n'est pas appliquée à tous les lots. Autrement dit, les rapports des lots précédents peuvent apparaître lors d'une exécution de débogage. Cependant, la règle est toujours appliquée dans un lot. Vous pouvez ainsi tester le service et diverses stratégies de traitement par lot, sans limiter le traitement ultérieur dans un environnement de production.
Bruit et mise à l'échelle
Pour protéger la confidentialité des utilisateurs, le service d'agrégation applique une mécanisme de bruit additionnel aux données brutes des rapports agrégables. Cela signifie qu'une certaine quantité du bruit statistique est ajouté à chaque valeur agrégée avant sa publication dans une dans un rapport récapitulatif.
Bien que vous ne contrôliez pas directement la façon dont le bruit est ajouté, vous pouvez influencer l'impact du bruit sur ses données de mesure.

La valeur du bruit est extraite de manière aléatoire Distribution de probabilités de calcul de la place, et la distribution est la même, quelle que soit la quantité de données collectées dans des rapports agrégables. Plus vous collectez de données, moins le bruit est affecté sur les résultats du rapport de synthèse. Vous pouvez multiplier le rapport agrégable les données selon un facteur de mise à l'échelle pour réduire l'impact du bruit.
Pour comprendre comment le bruit est ajouté, vos paramètres et l'impact sur votre consultez le Budget de contribution et Adaptation au budget de contribution dans Utiliser le bruit
Générer des rapports récapitulatifs
La génération d'un rapport récapitulatif dépend de votre utilisation de l'API. En savoir plus sur générer des rapports de synthèse API Private Aggregation et l'API Attribution Reporting.
Tester le service d'agrégation
Nous vous recommandons de lire le guide correspondant à chaque API que vous testez:
Pour tester le service d'agrégation, suivez nos ateliers de programmation:
Un outil de test local est également disponible pour traiter les rapports agrégables pour Attribution Reporting et l'API Private Aggregation.
Le framework de test de charge du service d'agrégation est une suggestion de framework de test.
Interagir et partager des commentaires
Le service d'agrégation est un élément clé des API de mesure de la Privacy Sandbox. Comme d'autres API de la Privacy Sandbox, ce point est documenté et discuté publiquement sur GitHub.
- Assistance pour le service d'agrégation: lisez l'explication, posez des questions, faites-nous part de vos commentaires sur l'implémentation et participez à la discussion. Pour obtenir une assistance supplémentaire, contactez notre alias d'assistance.
- Assistance pour les développeurs de la Privacy Sandbox: posez des questions et participez à des discussions dans le dépôt de l'assistance aux développeurs Privacy Sandbox.