AlloyDB Omni で膨大な NeuroPace 脳データセットの可能性を引き出す
Sharanya Arcot Desai
Director of AI and Technical Fellow, NeuroPace
Kurtis Van Gent
Staff Software Engineer, Google Cloud Databases
※この投稿は米国時間 2024 年 7 月 3 日に、Google Cloud blog に投稿されたものの抄訳です。
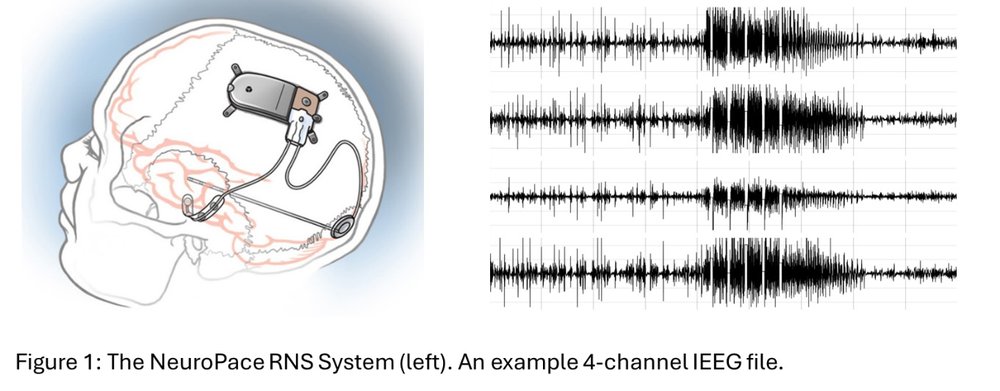
NeuroPace, Inc.1 は、カリフォルニア州マウンテンビューに本社を置く医療機器メーカーで、成人の難治性焦点性てんかんの治療用として FDA の承認を受けている応答性神経刺激装置である RNS® システム2を製造しています。神経刺激装置は、それぞれ 4 つの電極接点を持つ最大 2 つのリード線に接続できます。医師がプログラムした患者固有の異常パターンを検出し、同じく医師によりプログラム可能な電気パルスを発生させます。この装置は脳の記録(頭蓋内 EEG または iEEG)をキャプチャします。通常は、それぞれ 250 Hz でサンプリングされる 4 つのチャネルから約 90 秒間のデータを取得して保持します。これまでに 5,000 人以上の患者から約 1,600 万件の iEEG ファイルが収集されました。
NeuroPace の主要な研究目標は、発作の軽減に効果的な刺激パターンを特定することです。一つの仮説として、類似した iEEG 活動を示す患者どうしでは、効果のある治療設定も共通するのではないかと考えられています。従来の方法では、新規患者や現在の刺激設定に調整が必要な患者に適した刺激プログラムの設定は試行錯誤を繰り返しながら特定する必要がありますが、仮説が正しければ、この方法の改善を期待できます。
このようなデータドリブンなアプローチを取るためには、大規模な iEEG データから類似した脳活動パターンを検索し、選択した iEEG ファイルに基づいて医師が同様の患者プロファイルを迅速に見つけられるように、スケーラビリティとスピードの両方を必要とします。以前は、複数の患者間で類似した iEEG ファイルを見つけるには、患者内の iEEG データをクラスタリングし、クラスタの中心を特定して、PCA や t-SNE などの次元削減手法を使って他の患者から近似最近傍(ANN)を見つけるという複雑な処理パイプラインが必要でした。近似最近傍は、限られた新規患者の iEEG ファイルを使用して周期的に(数か月に 1 回)計算されていたため、この手法の柔軟性と実用性は今一つでした。
良いニュースとして、最近のベクトル データベースの進歩により、類似したベクトル エンベディングについてデータベースに直接クエリできる可能性が出てきました。このイノベーションにより、医師は事前にクラスタリングの手順を踏まなくても、患者からキャプチャした任意の iEEG ファイルを選択して、類似する iEEG の記録を他の患者の中から見つけられるようになります。唯一の要件は、新しい iEEG ファイルが利用可能になった都度に、ベクトル データベースを更新しておくことです。この簡素化により、患者が数千人、記録が数百万件という規模での類似 iEEG ファイルのクエリが大幅に容易になり、スケーラビリティの向上を実現できます。
NeuroPace AI チームは、Google Cloud のエンジニアと共同で、iEEG データをエンベディング モデルによってベクトルに変換し、ベクトル データベースである AlloyDB for PostgresQL に保存するという概念実証研究を実施しました。AlloyDB は、要求の厳しいトランザクション ワークロードに対応する、フルマネージドの PostgreSQL 互換データベースであり、pgvector 拡張機能に基づくベクトル類似性検索をサポートしています。AlloyDB Omni という AlloyDB のダウンロード版もあります。どこでも実行できるため、データベースをオンプレミスでホストでき、データをオンプレミスの HIPAA 準拠環境の境界内に維持できます。さらに、データベースをオンプレミスに維持することで、外部ネットワーク接続への依存度が軽減され、アプリケーションの残りの部分をオンプレミスに残したままデータベースを外部にホストした場合に懸念されるアプリケーションのダウンタイムのリスクを軽減できます。
この概念実証研究では、414 人の臨床試験患者から取得した約 120 万件の iEEG ファイルを処理しました3。394 人の患者のデータが AlloyDB クラウド サービスに追加され、残りの 20 人がテストに使用されました。各 iEEG ファイルはスペクトログラム画像に変換され、次に NeuroPace の AI チームが開発したカスタム エンベディング モデルを介してベクトルに変換されました。その後、これらのベクトルが AlloyDB ベクトル データベースに挿入され、テストコホートからランダムに選択された 50 件の iEEG ファイルがこのデータベースのクエリに使用されました(図 2)。
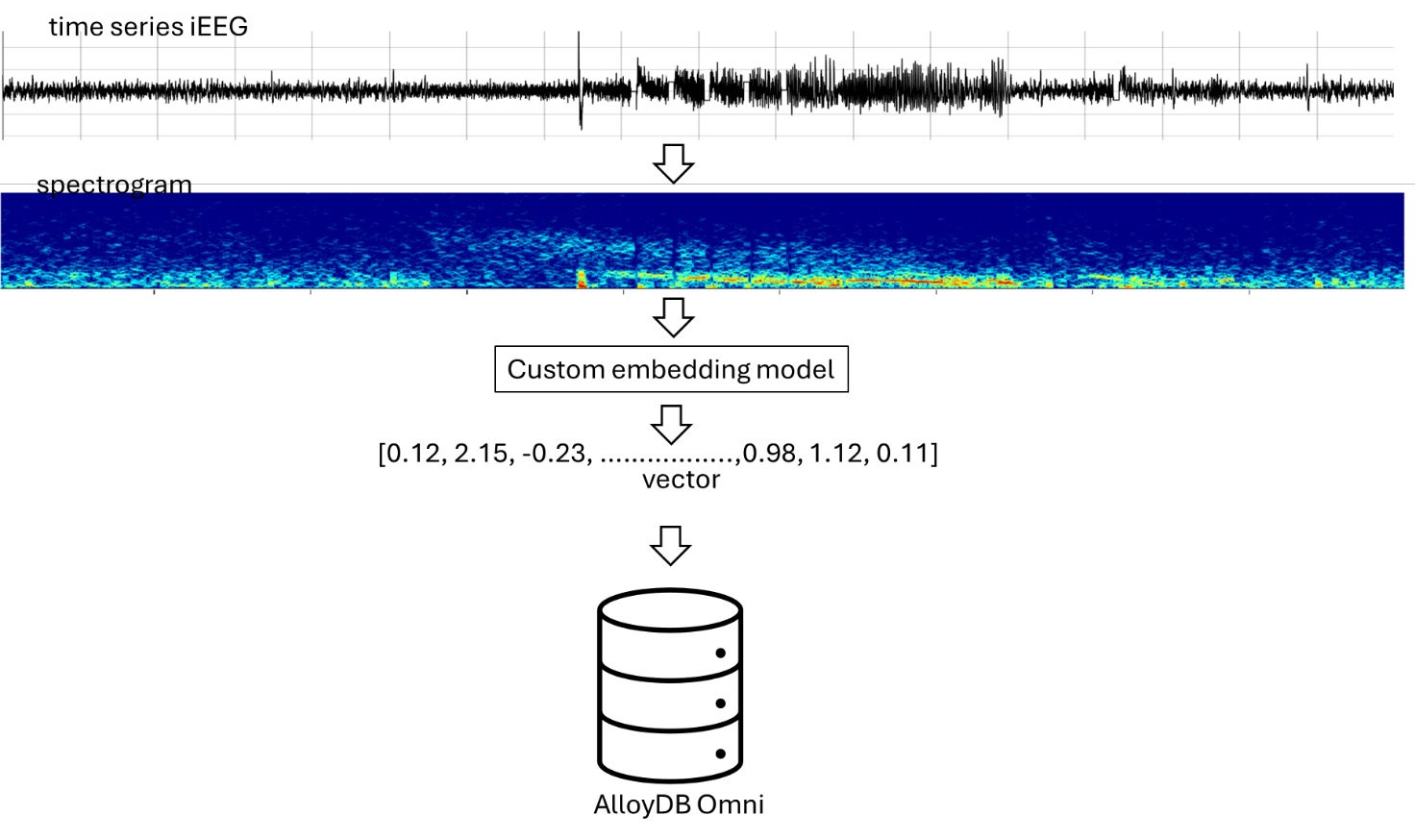
図 2. データ処理と AlloyDB Omni への挿入
類似性検索を実行する場合、PGvector を使用した AlloyDB には、ブルート フォース検索と比較してレイテンシを改善できる 3 つの異なるインデックス タイプ(Hierarchical Navigable Small World(HNSW)、IVFFLAT、IVF)があります。
-
HNSW は、大規模なデータセットであっても、接続されたノードの複数のレイヤを構築するグラフベースの方式を使用し、より効率的な検索経路を確保します。
-
「IVFFLAT」インデックスは、ツリーベースのクラスタリング手法を利用し、ベクトルを大まかなグループに編成してから、類似性がとりわけ高いクラスタ内でより詳細な検索を実行します。これにより、精度と検索速度の両方のバランスを取ることができます。
-
最近の AlloyDB AI の改良の一環として導入された新しい「IVF」インデックスは、Google の量子化技術を活用し、AlloyDB のクエリ処理とより緊密に統合することで、クエリ時間を大幅に短縮し、ベクトルごとにサポートされる次元の総数を引き上げます。
実際、インデックス(およびそれぞれのアルゴリズム)が異なれば、ユースケースも大きく異なり、パフォーマンスにも大きな違いが出る可能性があります。患者間で類似する iEEG を見つける NeuroPace のユースケースでは、IVF インデックスと HNSW インデックスの間で広範なベンチマークを実施しました。レイテンシ(クエリが完了するまでの時間)と再現率(ブルート フォース クエリで何パーセントの結果が存在したか)の両方が測定されました。これら 2 つの近似最近傍(ANN)アルゴリズムのパフォーマンスを比較すると、IVF はクエリ レイテンシの中央値が約 60 ミリ秒で高い再現率(~0.9)を示したのに対し、HNSW インデックス作成では再現率が 0.8 とわずかに悪く、またスピードも遅いことがわかります(IVF と比較した場合、クエリ レイテンシの中央値は 160 ミリ秒)。どちらのインデックスも、レイテンシと速度のバランスを取るために多数の変数を提供します。
それにもかかわらず、どちらの方法もクエリにかかる時間でブルート フォースを大幅に上回りました。ブルート フォースでは類似した iEEG データを見つけるのに 14.7 秒近くかかりました。ブルート フォースと比較した 2 つの異なるインデックス作成方法のクエリ レイテンシと再現率のヒストグラムを図 3 に示します。図 4 は、あるテスト患者のサンプル iEEG クエリファイルに対するクエリの結果を示しています。
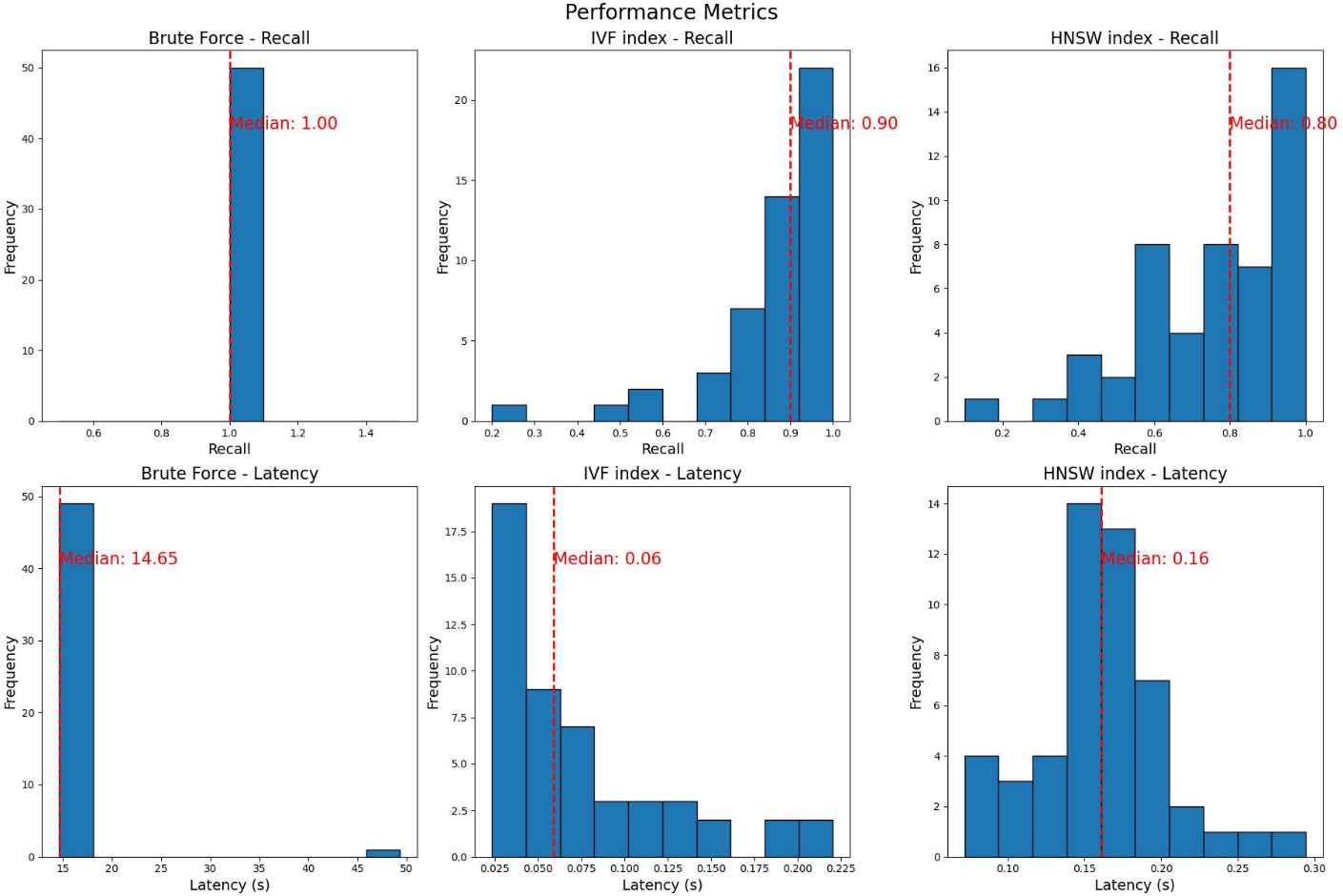
図 3. ブルート フォースの再現率とレイテンシのヒストグラム、および 2 種類のインデックス方式(IVF および HNSW ANN)。
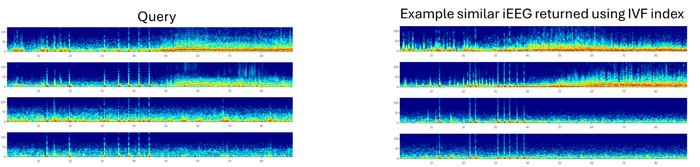
図 4. 上位 2 つのチャネルで脳波上発作を起こした 20 人のテスト患者のうちの 1 人から取得した iEEG と、IVF インデックス方式によって返された検索データセット内の 394 人の患者のうちの 1 人から取得した類似 iEEG のクエリ例。
NeuroPace は、これらの検出結果4が膨大な iEEG データを効率的に活用する研究を前進させる可能性を秘めているため、強い関心を寄せています。うまくいけば、その前進が、RNS システムの最適なプログラム設定を特定するのに効果的なアルゴリズム開発の足掛かりとなるでしょう。また、AlloyDB の新しい ScaNN インデックスをついに試してみることができます。これにより、パフォーマンスとユーザビリティをさらに向上させられる可能性があります。
信頼性が高い Postgres に組み込まれた超高速のベクトル検索機能を備え、すべてがオフクラウド環境で安全に実行される AlloyDB Omni は、NeuroPace の研究を促進しています。NeuroPace と Google Cloud の連携に関する詳細、ご自身で AlloyDB Omni をインストールする方法、Google Cloud で今すぐ AlloyDB のマネージド サービスを利用開始する方法についてもご確認ください。また、こちらの Codelab を使用して AlloyDB AI でベクトルを使い始めることもできます。
2. Rx のみ。RNS® System は、てんかん病巣が 2 つ以下の難治性部分てんかん発作の成人患者に対する補助療法です。安全性に関する重要な情報については、http://www.neuropace.com/safety/ を参照してください。
3. 研究目的での患者データの使用に関して、患者の同意を得ています。
4. RNS System には現在、AI をベースにした機能や AI を利用する機能は組み込まれていません。
-NeuroPace、AI 担当ディレクター兼テクニカル フェロー、Sharanya Arcot Desai 氏
-Google Cloud データベース、スタッフ ソフトウェア エンジニア、Kurtis Van Gent