| Date |
Summary |
| 2006-Jun-19 |
In the code charts for Unicode Version 2.0
through 4.1.0, the representative glyphs for
U+0485 and U+0486 were based on an incomplete
understanding of their typical appearance. The
previous glyphs are shown on the left, the
revised glyphs are shown on the right.


|
| 2006-May-18 |
In the code charts for Unicode Version 3.0
through 4.1.0, the representative glyphs for
U+0340 and U+0341 are shown as different from
their canonical equivalents U+0300
and U+0301. The incorrect glyphs are shown on the left, the
corrected glyphs are shown on the right.


The code charts contain an annotation stating that U+0340 and
U+0341 have special kerning behavior. That is incorrect,
instead, both these characters and their canonical equivalents
have special kerning behavior in specific language contexts. |
| 2005-October-19 |
The Unicode 4.1.0 version of the extracted data file, DerivedLineBreak.txt, has an error in the derivation of the Line_Break property listing for Hangul syllables. It incorrectly lists all Hangul syllables as having lb=H2, when instead they should have a mixture of lb=H2 or lb=H3. The correct values for Hangul syllables are listed in LineBreak.txt. |
| 2005-August-29 |
The status section of the Unicode 4.1.0 version of
UAX#14: Line Breaking Properties (date: 2005-03-29)
incorrectly reflected the status of this document . A corrected
version was placed online (date: 2005-08-29). |
| 2005-August-19 |
There are several errors in the numbers provided for the
allocation of code points in Tables D-2, D-3, and D-4 (p. 1356
of Unicode 4.0).
1. Format characters were mistakenly counted twice by
including them in the "Alphabetics, Symbols" row. The corrected
counts for "Alphabetics, Symbols" are:
Table D-2: 4,738 (1.0), 6,292 (1.1), 6,493 (2.0), 6,495
(2.1), 10,212 (3.0), 10,214 (3.1), 11,169 (3.2), 11,618 (4.0).
Table D-3: 1,586 (3.1), 1,586 (3.2), 2,360 (4.0).
2. A longstanding off-by-one error exists in the count for
Unicode 1.1. The corrected totals for Unicode 1.1 are:
Tables D-2 & D-4: Graphic characters 34,152, Code points
assigned to abstract characters 40,633, Designated code points
40,635, Undesignated code points 24,901.
3. There was an off-by-two addition error for certain totals
for Unicode 4.0. The corrected totals for Unicode 4.0 are:
Table D-2: Code points assigned to abstract characters
57,129, Designated code points 59,211, Undesignated code points
6,325. |
| 2005-August-12 |
In the code charts for Unicode Version 1.1
through 4.1.0, the representative glyph for U+0D66 resembled the
glyph for Malayalam fraction one quarter. It is being corrected
to better match current practice. The incorrect glyph is shown
on the left, the corrected glyph is shown on the right. 

|
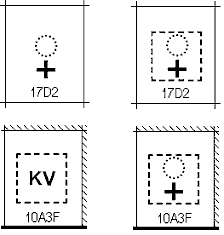
| 2005-August-11 |
In the code charts for Unicode versions 3.0
through 4.1.0, the representative glyph for U+17D2 KHMER SIGN COENG should have been shown with a dashed box to indicate the
fact that the character is ordinarily invisible. In the code
charts for Unicode 4.1.0 the representative glyph for U+10A3F
KHAROSHTHI VIRAMA should have been shown with a glyph matching
that of U+17D2 to indicate the related function of these
characters. The corrected glyphs are shown on the right.
 |
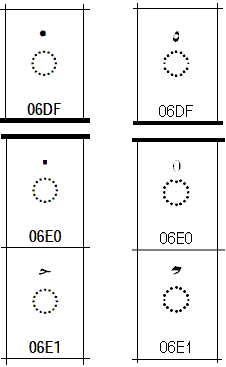
| 2005-August-09 |
In the code charts for Unicode 1.1 through 4.1.0 the
representative glyphs for several Arabic characters reflected an
incomplete understanding of their origin and use. Recent
evidence has established that these characters usually occur with
different shapes. The table below lists the incorrect glyphs on the left and the corrected glyphs on the
right.
|
| 2005-August-08 |
The middle column in figure 14-7 on p. 380 in The Unicode
Standard, Version 4.0 is incorrect. In the examples
shown the NFC form should be identical to the NFD form. |
| 2005-July-16 |
In the code charts for Versions 2.0 through 4.1.0 the glyph
shown for U+33AC SQUARE GPA was inconsistent with the
compatibility decomposition of the character into <square> 0047
G 0050 P 0061 a. The incorrect glyph is shown
at left. The corrected glyph is shown at right. The corrected
glyph also matches the appearance of the character in the source
standards from which it was derived.

 |
| 2005-June-19 |
In the code charts for Version 4.1.0, the glyph for U+1234
ETHIOPIC SYLLABLE SEE was inadvertently shown as if it was the
same as the glyph for another Ethiopic character (U+1246).
Code charts for Unicode, Version 4.0 and earlier show the
correct glyph:
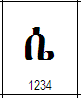 |
| 2005-June-10 |
In Section 9.6, Tamil, of The Unicode Standard, Version 4.0, p. 243, there is a ligation rule for U+0BB0
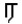 TAMIL LETTER RA. In fact this rule is not mandatory, but depends on typographical practice. The text of the standard will be corrected to indicate that various governmental bodies mandate no change to the shape of TAMIL LETTER RA in these ligatures, and to indicate that predominant usage in some countries, such as Malaysia and Singapore, is to use the unchanged form of TAMIL LETTER RA in these ligatures. TAMIL LETTER RA. In fact this rule is not mandatory, but depends on typographical practice. The text of the standard will be corrected to indicate that various governmental bodies mandate no change to the shape of TAMIL LETTER RA in these ligatures, and to indicate that predominant usage in some countries, such as Malaysia and Singapore, is to use the unchanged form of TAMIL LETTER RA in these ligatures.
|
| 2005-May-13 |
The text of version 4.1.0 of UAX#14:
Line Breaking Properties
is inconsistent with the property file
http://www.unicode.org/Public/4.1.0/ucd/LineBreak.txt. The
data file should have listed 1735 PHILIPPINE SINGLE PUNCTUATION and
1736 PHILIPPINE DOUBLE PUNCTUATION with line break class BA. The
UAX should have listed 17D8 KHMER SIGN BEYYAL and 17DA
KHMER SIGN KOOMUUT with line break class BA. |
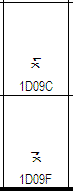
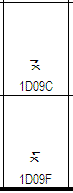
| 2005-May-12 |
The glyphs for U+10D9F BYZANTINE MUSICAL SYMBOL AGOGI GORGI
and U+10D9C BYZANTINE MUSICAL SYMBOL AGOGI ARGI have been swapped
in all versions of Unicode prior to and including 4.1.0. The
incorrect glyphs for the pair are shown on the left, the
corrected glyphs are shown on the right. The correction ensures
that the glyphs match the character identity as defined by the
character names.
 |
| 2005-April-22 |
The text of Unicode 4.1.0 at
http://www.unicode.org/versions/Unicode4.1.0/#NotableChanges
notes in the section "Significant Character Additions," subsection "Additions for Biblical Hebrew": "Five new Hebrew characters have been added in Unicode 4.1 for special usage in Biblical Hebrew text." This is incorrect. The character U+05BA HEBREW POINT HOLAM HASER FOR VAV has not been added for Version 4.1. However, it is currently proposed for addition to Version 5.0.
In the same subsection, the paragraph starting "The vowel point holam..." should be disregarded, as it refers to the holam haser for vav, which has not yet been added.
The Unicode Character Database in
http://www.unicode.org/Public/4.1.0/ucd/DerivedAge.txt, as well as the Character Code Charts at
http://www.unicode.org/charts/PDF/Unicode-4.1/U41-0590.pdf correctly show the addition of only four characters for biblical Hebrew in Version 4.1.
|
| 2005-April-18 |
On p. 239 of The Unicode Standard, Version 4.0, the first
sentence of the paragraph on Ordering in Gurmukhi is corrected to
read, "U+0A73 GURMUKHI URA and U+0A72 GURMUKHI IRI are the first
and third 'letters' of the Gurmukhi syllabary, respectively." The
first bullet below that paragraph is also corrected to reflect
this order. |
| 2005-March-21 |
On p. 113 of The Unicode Standard, Version 4.0 in the middle of the page above Table 5-2, the
UTF-16 representation for the example of Ugaritic letter delta is
incorrectly cited as <DC00 DF84>. It should be <D800 DF84>, and the
text of the sentence should thus read:
"In UTF-16, the supplementary character for Ugaritic would, of course, be represented as a surrogate pair:
<D800 DF84>. |
| 2004-November-29 |
On p. 231 of The Unicode Standard, Version 4.0 under the subheading "Other Languages," the following sentence should be deleted: "Sindhi makes use of U+0974 DEVANAGARI LETTER SHORT YA." The reference to U+0974 was to an unapproved proposal; no character is actually encoded at U+0974. |
| 2004-October-04 |
In the last row of Table 9-4 on p. 235 of Unicode 4.0, the
nominal form of DA is missing between the arrow and the text “(dya)”
and only the post-base form of YA is shown. This row should
instead look like this:
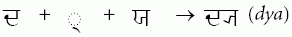 |
| 2003-November-18 |
In Table 8-11 (Dual-joining) on p. 211 of
Unicode 4.0, the following characters are missing:
U+072D SYRIAC LETTER PERSIAN BHETH
U+072E SYRIAC LETTER PERSIAN GHAMAL
U+074E SYRIAC LETTER SOGDIAN KHAPH
U+074F SYRIAC LETTER SOGDIAN FE
In Table 8-12 (Right-joining) on p. 211, the following
characters are missing:
U+072F SYRIAC LETTER PERSIAN DHALATH
U+074D SYRIAC LETTER SOGDIAN ZHAINNote: The joining types for these characters are correctly designated in ArabicShaping.txt in the Unicode Character Database. |
| 2003-November-11 |
In Figure 2-11 on p. 28 of Unicode 4.0, in the
2nd row (UTF-16), 4th cell, the sequence should read D800 DF84,
not DC00 DB84. |
| In Figure 2-12 on p. 34, in the 3rd row
(UTF-16BE), 4th cell, the sequence should read D8 00 DF 84, not
DC 00 DB 84. In the 4th row (UTF-16LE), 4th cell, the sequence
should read 00 D8 84 DF, not 00 DC 84 DB. |
| 2003-October-30 |
In The Unicode Standard, Version 4.0, the
current documentation may give the mistaken impression that all
characters with dotted-box glyphs have the General Category Cf.
To clarify this, the following text should be added to the seventh
paragraph on p. 414 ("Sometimes characters..."), so that the
second sentence begins, "Examples are the space characters, and
such characters as U+00AD". An additional sentence should also
be added at the end of that paragraph reading, "This is not
correlated with the General Category value of the character." |
| In Table 10-3, Myanmar Syllabic Structure, on p.
273, the glyph in the next to last row, dot below, is
shown incorrectly. The hollow dot should be centered under the
dotted circle. |
| In Figure 7-3 on p. 172, the glyph for the
middle tone mark (second line of the figure) is incorrect. It
should be U+0309 COMBINING HOOK ABOVE. The correct glyph can be
found in the code charts. |
| 2003-October-14 |
The alias for U+11B8 (its jamo short name) is
incorrectly listed on p. 531 of The Unicode Standard, Version
4.0 as "M". Its correct value should be "B". |
| 2003-October-3 |
On p. 179 of The Unicode Standard, Version
4.0, the name of the character U+0406 CAPITAL LETTER
BYELORUSSIAN-UKRAINIAN I is incorrectly cited as CYRILLIC
CAPITAL LETTER I. |
| 2003-October-2 |
On page 57 of The Unicode Standard, Version
4.0, under "References to the Unicode Standard," the
citation to reference version 4.0 lists Reading, MA as the place
of publication. It should instead list Boston, MA.
This change also affects the Unicode Web site pages
explaining how to reference Version 4.0. The place of
publication for 4.0 has been changed from Reading to Boston on
http://www.unicode.org/versions/Unicode4.0.0/ and
on
http://www.unicode.org/standard/versions/components-4.0.0.html |
| 2003-September-30 |
On page 353 of the Unicode Standard 4.0, at the
end of the first paragraph, PRESCRIPTION TAKE is shown with the wrong
code point. The correct code point is U+211E. |
| 2003-September 16 |
In the second row of the Hanunóo column of Table
10-11 (p. 287 of Unicode 4.0), the leftmost glyph incorrectly
shows the shape for /ya/ instead of the intended shape for /ga/. |
| 2003-September-10 |
In Unicode 4.0, p. 122, line 11, subsection
"Nonlinear Boundaries," the text should read "Use of nonlinear
boundaries" rather than "Use of linear boundaries". |
| In Table 10-1 on p. 267, the Thai code point
sequences in rows 7 and 8 are incorrect. Row 7 ku' should read
"U+0E01 U+0E36" rather than "U+0E01 U+0E35"; Row 8 ku': should
read "U+0E01 U+0E37" rather than "U+0E01 U+0E36". |
| In Table 10-2 on p. 269, the Lao code point
sequences in rows 7 and 8 are incorrect. Row 7 ku' should read
"U+0E81 U+0EB6" rather than "U+0E81 U+0EB5"; Row 8 ku': should
read "U+0E81 U+0EB7" rather than "U+0E81 U+0EB6". |
In Table
10-9 on p. 284, the Tai Le vowel sign "i" was omitted from the
row of the table displaying the unmarked (tone 1) "ti"
syllables. |
| On p. 272 the two occurrences of the Myanmar
glyphs representing the word "krwe" shown in the paragraph
beginning, "The Myanmar script..." and in the example below
should use U+1031 rather than U+1004. A gif showing the
correction will be posted here once available. |
|
In Chapter 17, Han Radical-Stroke Index,
the JIS X 0213 compatibility characters U+FA45..U+FA6A are
misplaced because of an off-by-one error. The error will be
addressed, when feasible, by regeneration of the online radical
stroke index pages. |
| 2003-August-27 |
U+180E MONGOLIAN VOWEL SEPARATOR should be added
to Table 6-2, p. 155 in Unicode 4.0. |
| 2003-August-04 |
In Unicode 4.0, Table 8-7, p. 203, the Xn column
glyph for QAF is the correct glyph, but is shown in the
wrong typeface. |
| Figure 11-8, p. 308. In example
10 in this figure, the two ideographic description
characters are reversed; they should be in the order 2FF3 2FF2.
Also, in example 4 in this figure, an incorrect glyph for U+2FF1
is shown; it should appear as for U+2FF1 in examples 5 through
8. |
