SPEC Cloud IaaS 2018 Benchmark User Guide
1.0 Introduction
The SPEC Cloud IaaS 2018 benchmark captures the performance and scalability of a cloud system under test (SUT) from the cloud service user perspective. The benchmark manipulates the “host” management services and performs a predefined set of tests and patterns until certain terminating conditions appear. The benchmark uses its own measurements along with data extracted from various log files collected from to derive a set of primary metrics plus supporting details for the cloud system under test.
The SPEC Cloud IaaS 2018 benchmark assumes that you know how to set up and manage your cloud SUT.
You need to define all aspects of the SUT. This means:
- Your SUT meets minimum functional and configuration requirements.
- Your SUT can access the Internet to retrieve updates and patches, or you can transfer any updates/patches as needed.
The cloud you intend to test needs to be up and running and fully functional in order to attempt to run a fully compliant SPEC Cloud IaaS 2018 benchmark test. While some of the benchmark authors may be able to respond to common issues or well known pitfalls of some clouds / cloud providers, we are unable to assist in installing, configuring, or making ready a new cloud for the first time. Please ensure that your cloud is ready to be used before proceeding. It is often the case that you will hit operational / scaling issues and need to troubleshoot your own cloud as this benchmark attempts to use it. You need to be ready and have the resources to triage your own cloud during the benchmarking process should issues arise in the operational maintenance of your cloud. This benchmark will not audit or make recommendations for repairing your cloud besides typical error reporting when something goes wrong.
Before trying to set up or run the SPEC Cloud IaaS 2018 benchmark, please read the introductory materials in the FAQ and Glossary and then the Design and Run Rules documents. The rest of the User Guide assumes familiarity with the various benchmark terms, names, abbreviations, and the configuration, set up, and execution requirements for a compliant run.
Cloud System Under Test
The group of computing hardware, installed operating system, storage, networks and the cloud management system is collectively known as the “System Under Test” or the SUT. The following sections describe the major components and assumptions.
Cloud System Under Test Roles
The User Guide’s examples assume that the SPEC Cloud IaaS benchmark kit runs with the following “machine” roles:
- cbarchive - repository of the downloaded kit
- cbharness - benchmark harness host that controls the whole environment
- cbnode - host(s) that will run actual workloads
These roles
typically reside on a single client system, virtual machine,
container, or cloud instance depending on whether the cloud
SUT is a white box or black box as defined in the run and
reporting rules.
Network Time Protocol (NTP)
A common NTP server must be used between the cbharness and all cloud instances created by the benchmark per the run rules. A submission will be considered Non-Compliant if produced without a working, coordinated NTP. The benchmark will mark itself non-compliant if it has detected time drifts due to a misconfigured NTP service.
Cloud Manager
A major component of the SUT is the Cloud Manager, which varies by installation and vendor. The SPEC Cloud IaaS 2018 Benchmark isolates this variable layer by using adaptors that implement specific, predefined IaaS cloud management actions. The benchmark kit already contains supported adapters for many cloud management systems.
Supported Cloud Managers
The SPEC Cloud IaaS 2018 Benchmark has been tested with the following cloud platforms and their corresponding cloud management system (cloud managers) during the development and release cycle. They are considered supported per the Run Rules
|
Amazon EC2 Digital Ocean Google Compute Engine |
OpenStack Rackspace IBM SoftLayer |
Custom Cloud Manager Adapters
SPEC Cloud IaaS benchmarks supports testing with cloud manager adapters written for specific Cloud Under Test configurations. However, you can create a custom CBTOOL Cloud Manager Adapter when
- your cloud manager is not among the ones listed above,
- versions have changed beyond minor patches, or
- white box cloud manager
enhancements require the adapter to be revised.
Each tester should understand how their cloud manager varies from its base version, and from the supported versions provided in the kit. A localized custom adapter can be created, using one of the supported versions as a base. See Appendix C for instructions on how to create adapters.
Caveat: Please have SPEC review and accept any custom adapter before uploading a submission.
Basic Cloud Host Requirements For Submission
While it is possible to run SPEC Cloud IaaS 2018 benchmark on a single machine, any submission for review must meet the following conditions.
- At least three physical machines with or without virtualization software.
- A IaaS Cloud management
system and API.
- Enough disk storage to hold at the
database files and logs on cbharness and the
workload servers. Typically, the amount of storage is
40 to 50 GB, but to retain the files from multiple and very
long running tests addition storage may be needed.
Operating System Requirements
The SPEC Cloud IaaS 2018 benchmark has these operating system dependencies.
- The sudo software is installed and configured to allow administrator level access without prompting for a password.
- A *Nix compliant operating system for instances that supports sh or bash shells.
- The same *Nix user account/password across all instances (e.g., set up cbuser as the *Nix account in instance images).
- The SSH server and client software installed, configured to allow remote access without prompting when authorized with appropriate SSH key files.
- When cloud instances are behind a firewall, then access must be set up using a jump box or a VPN to the benchmark harness machine.
Consistent User Account
The SPEC Cloud IaaS 2018 benchmark requires unfettered remote access to all SUT compute instances to manage and execute its workloads..
- Create the same test user name on all hosts. The User Guide uses cbuser in all the examples.
- Set up cbuser to use BASH (/bin/bash) or SH (/bin/sh) as the login shell.
- Set up SSH credentials such that SSH and SCP DOES NOT prompt for a password when the benchmark harness tries to move files or remotely control processes.
- Set up SUDO to allow cbuser administrator level access commands without password prompts.
The Benchmark Toolkit
Benchmark Manager: CBTOOL
SPEC Cloud IaaS 2018 benchmark uses an open source automated framework called Cloud Rapid Experimentation and Analysis Tool (CBTOOL), also known as “CloudBench” (CB) that manages cloud-scale controlled “experiments”. CBTOOL automates deploying complete application workloads, running the benchmark, and collecting data from the SUT. CBTOOL is written in Python, using only open-source dependencies, including Redis, MongoDB and Ganglia.
The SPEC Cloud IaaS 2018 benchmark is defined by the distributed CBTOOL configuration files that presets certain parameters: file locations, roles, hosts, directives, and execution sequence. The tester must enter other parameters that define the SUT hosts, network addresses, account names, and raise default minimum levels.
At the core of each experiment, there is the notion of application workloads. Each “Application Instance” (AI), workload is implemented by a group of cloud instances, with different roles, logically interconnected in order to execute different applications (typically, but not limited to, benchmarks).
Cloud Manager Adapters
Each SUT has some type of automated or manual Cloud Management System. Conceptually, all Cloud Managers perform common tasks. The SPEC Cloud IaaS 2018 Benchmark incorporates normal cloud management tasks into its workload sequence.
Cloud Management Interface and Adapters
The SPEC Cloud IaaS 2018 Benchmark manager, CBTOOL, uses a defined set of cloud and benchmark management tasks during the test sequence. Please ensure that the local Cloud Manager’s capabilities matches that of the adapter you plan to use by identifying the corresponding capabilities or command sequences that implement tasks such as:
- Provision instance - create compute instances, (optionally) install required software;
- Provision storage for instances;
- Provision application instance - distribute generated workload configuration files, start workload specific services, and determine service availability;
- Start/stop specific load driver for an application instance;
- Monitor application instance availability and responsiveness during workload runs;
- Collect workload results (log files, or command line responses);
- Stop workload servers
- Destroy application instance(s);
- Destroy instances
Variations may require creating a new adapter, which is described in Appendix C: Building a Custom Cloud Adapter. Cloud APIs are expected to change constantly. If any of the adapters we ship are not functioning properly due to recent API changes, please reach out for support and we’ll help you.
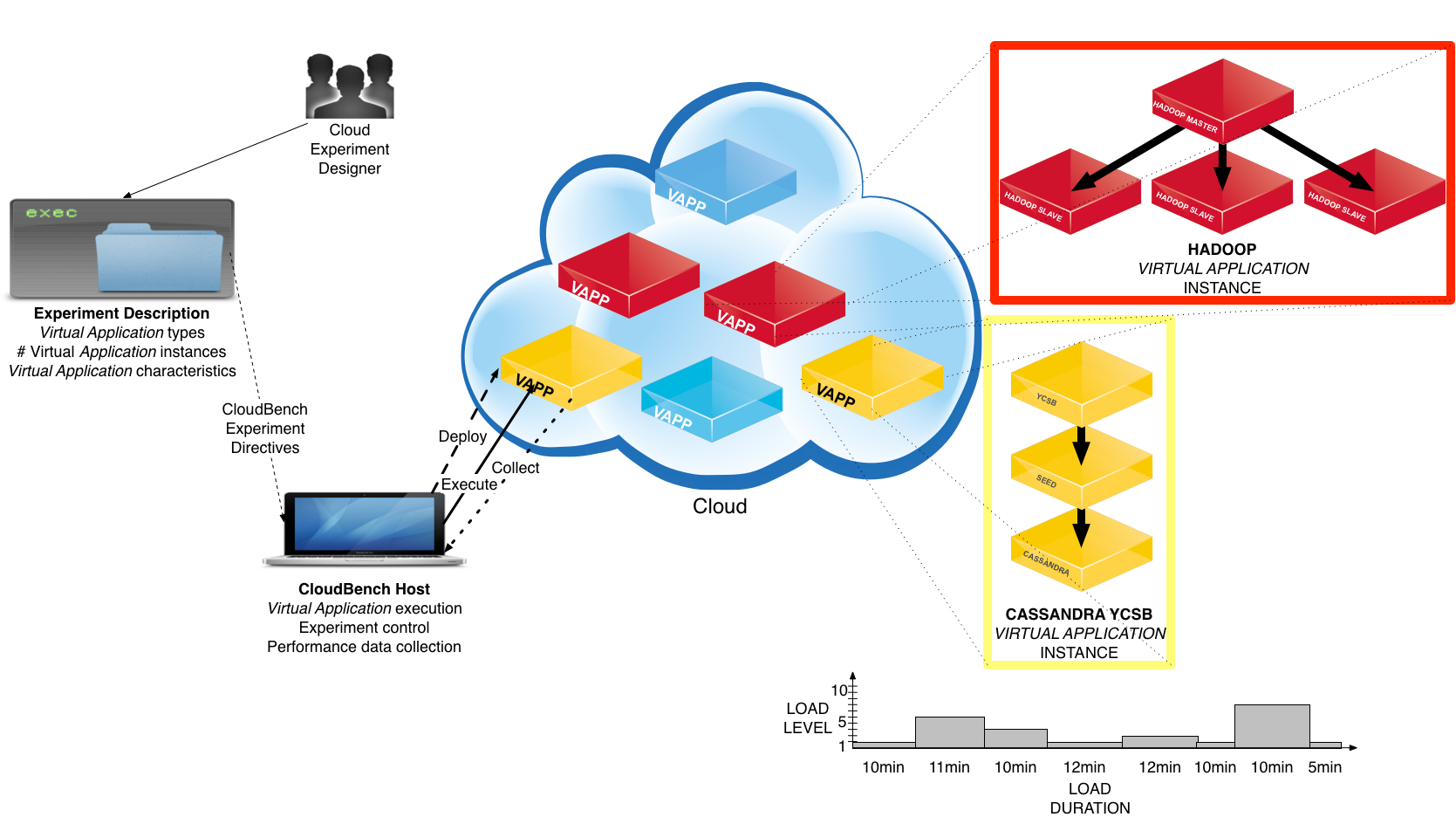
Application Instance (AI)
The benchmark workloads exist as a set of software applications that perform their assigned tasks throughout the full cycle.
Each AI has its own load behavior, with independent load profile, load level and load duration. The values for load level and load duration can be set as random distributions (exponential, uniform, gamma, normal), fixed numbers or monotonically increasing/decreasing sequences. Each Application Instance has a specific “load level” based on type.
|
Workload |
Application Instance Composition and Workload |
|
KMeans/Hadoop |
One VM is the “hadoopmaster” type and many VMs are “hadoopslave” type. The size of the sorting data set represents this workload. |
|
YCSB/Cassandra |
One VM is the “ycsb” type, and many VM(s) are Cassandra seed nodes. The size is the number of simultaneous threads represents this workload. |
The Benchmark Cycle (Summary)
This outlines the conceptual steps a tester typically takes through the full cycle.
- Install all SUT components
- Set up your cloud’s System Under Test environment: machines, virtualization (optional), network(s), operating system licenses, storage, NTP service, etc.
- Install the SPEC Cloud benchmark kit
- Assign benchmarking roles accordingly
- Setup benchmark harness,
including CBTOOL (in a virtual machine (VM) or container)
- Test run the benchmark in simulation mode (important!)
- Prepare, upload and test the workload images
- Set benchmark parameters to describe your SUT
- Running/tuning full benchmark
- Run Baseline phase
- Run Scale-out phase
- Tune SUT parameters and/or operating system settings
- Compliant run
- Submit results

2.0 Set up SUT and Install Software
2.1 Prepare Your Cloud for the Benchmark
The tester must consider the following before benchmark installation and configuration. The instructions below assume that CBTOOL runs on an instance (e.g., a VM) with Internet access at the time of kit installation. If instances cannot access the Internet, then set up local Ubuntu and python pip repositories and use these repositories instead.
Determine Where CBTOOL Runs?
CBTOOL and benchmark drivers must be set up together on the same machine - the benchmark harness (cbharness). It controls other host instances (cbnodes). For a Whitebox cloud under test, the cbharness machine must be outside of the cloud. For a Blackbox cloud under test, the cbharness machine must not share a physical machine with the cbnodes to the extent possible.
The diagram below shows a typical harness and instances setup.

NTP Server(s) For Benchmark Machines
All hosts in the SUT must use the same NTP server to synchronize to a common time base. By default, the cbharness machine will act as the NTP server for the other host instances in the SUT. It must also synchronize to a separate NTP server(s).
If you wish to have cbnodes obtain time from NTP server(s) other than the cbharness machine, then edit the ~/osgcloud/driver/osgcloud_rules.yaml configuration file. However, if the cbnodes cannot reach these other NTP server(s) or synchronize time with them, then various testing phases of the benchmark may hang. Set the timeserver parameter to a comma separated list of NTP servers:
timeserver: NTP_Server1_IP_Address,NTP_Server2_Hostname
Storage Space For Benchmark Machines
The benchmark has two workloads: KMeans (hadoop) and YCSB (cassandra). Each workload has two ‘roles’ that correspond to load/data generator (ycsb/hadoop name node) and the workload (cassandra/hadoop cluster).
The suggested storage requirements for these roles are defined below.
|
Workload Roles |
Local free space |
Usage Considerations |
|
YCSB |
40 GB |
Holds runtime log files for YCSB |
|
SEED |
40 GB |
Holds Cassandra NoSQL database |
|
HADOOP MASTER |
40 GB |
Holds runtime log files and KMeans driver |
|
HADOOP SLAVES |
40 GB |
Hold data and log files |
|
cbharness |
40 GB |
Holds collected experiment data from hosts running CBTOOL and benchmark drivers |
Block Storage Support
Most clouds support some form of block storage support, and allow additional block-based volumes to be attached to running instances in their cloud. These volumes can take many forms, such as NASes, SAN-based LUNs, or network filesystems.
When the selected cloud manager adapter implements attaching these volumes, CBTOOL will use any free volumes larger than 1 GB — but not a root, swap or cloud-init volumes — during benchmark runs. It automatically formats a filesystem on the volume, and instructs both Cassandra and HDFS to store data on these new file systems.
The benchmark supports requesting block storage volumes automatically, but it is not configured by default. This must be specifically requested by the user before CBTOOL will create and use the volume. The effects of using such a volume will appear in the reported result to SPEC at submission time.
You must disclose that you configured the benchmark to use these additional disk block storage configurations in the osgcloud_environment.yaml file when you prepare a submission that uses these volumes. The Whitebox description should provide specific hardware details others can use to order the same storage solution. The Blackbox description should provide sufficient details (such as storage product tier, or ‘default’) for others to reproduce the submission. It must be obvious during the review process that your instances are configured this way in the YAML.
2.2 Basic SPEC Cloud Benchmark Setup Steps
At this point, the basic cloud environment is ready for the benchmark software installation, and incorporation via configuration settings.
Each tester needs to build these workload images from scratch for their specific cloud and cloud management combination. By the end of this section, a host instance will have all the software and configuration settings in place. This can become the predefined system image used to instantiate all virtual machines in the cloud under test.
Select and Install Your Operating System
The SPEC Cloud IaaS benchmark assumes you have selected one *nix distribution that will run on all application and workload instances. SPEC currently supports the following distribution versions based on test runs during the development cycle.
- Ubuntu
- CentOS / RHEL
The actual steps to retrieve these installation images is beyond the scope of this user guide. You should know how to obtain the appropriate images in your cloud environment from either base distributions or pre-built images from an internal archive.
Basic Operating System Settings
At this step, establish a network assignment map of your test hosts’ assigned networks, the NTP server(s) the cbharness host will use, and the standard system settings usually used for benchmark tests. Enter the basic host IP address assignments for the assigned roles. Make sure DNS is configured correctly to work in conjunction with these host names.
Make any operating system tuning settings based on your organization’s standard practices. Please document any kernel tuning changes in the submission files.
|
Action |
Linux command/output |
|
Add your machine hostname (HOSTNAME) and IP address (IPADDR) to /etc/hosts file. |
$ sudo vi /etc/hosts |
|
If the command “ifconfig -a” lists more than one non-loopback network interface, add these IP address (IPADDR2) and hostname (HOSTNAME-2). |
$ sudo vi /etc/hosts |
|
Set up key-based ssh access to for CBTOOL by adding the UseDNS key, if it does not exist. |
$ vi /etc/ssh/sshd_config |
|
Verify DNS is configured correctly and resolves both external and internal domain names, using the above information for the internal name(s). |
$ nslookup HOSTNAME Non-authoritative answer: Name: HOSTNAME Address: IPADDR $ nslookup time.nist.gov Non-authoritative answer: Time.nist.gov canonical name = ntp1.glb.nist.gov. Name: ntp1.glb.nist.gov Address: 132.163.97.4 |
|
Generate your own ssh keys to be used with CBTOOL and instances |
$ ssh-keygen [press ENTER for all options] $ ls $HOME/.ssh |
Make storage assignments appropriate to your environment, and document these settings. Use the above Storage Space and dynamic Block Storage sections as a guide on which host roles versus storage capacity assignments.
Set up the SSH Server host key, and configure it to allow remote SSH client access without prompting for passwords or phrases.
Create and Setup cbuser User account
Create the cbuser user account. Then create the SSH client keys and install in the home directory.
|
Action |
Linux command/output |
|
Create account |
$ sudo adduser -m cbuser $ sudo passwd cbuser |
|
Change to cbuser user |
$ sudo su - cbuser |
|
Generate your own ssh keys to be used with CBTOOL and instances |
$ ssh-keygen [press ENTER for all options] $ ls $HOME/.ssh |
|
Append the id_rsa.pub content to the authorized_keys file |
$ cd ~/.ssh $ cat id_rsa.pub >> authorized_keys |
|
Allow user to bypass password when using sudo |
$ sudo visudo |
Set up SSH server configuration to allow the cbuser user to execute administrative commands without prompting.
Install Required System Packages
The SPEC Cloud benchmark kit depends on certain open source commands and libraries. Regardless if the operating system is dynamically loaded from a network boot server or instantiated from a running copy, please add certain open source packages.
The following assumes a minimal operating system has been installed on a representative instance - created as a virtual machine (VM).
|
Ubuntu Linux commands & output |
|
SSH into the VM, and get the latest package list $ ssh -i YOURKEY ubuntu@[YOURVMIPADDR] |
|
Install unzip, git and other prerequisite packages. $ sudo apt-get update $ sudo apt-get -y remove --purge unattended-upgrades $ sudo apt-get install -y git unzip libssl-dev python-pip sshpass ncftp lftp openvpn ganglia-monitor redis-server python-dev python-daemon pssh ntp python-pymongo-ext bc rrdtool python-dateutil python-rrdtool python-pillow python-jsonschema rrdtool $ update-rc.d -f redis-server remove $ update-rc.d -f mongodb remove $ update-rc.d -f ganglia-monitor remove $ if [ -e /etc/init/ganglia-monitor.conf ] ; then mv /etc/init/ganglia-monitor.conf /etc/ganglia-monitor.conf.bak ; fi |
|
Make sure the NTP service is running and works correctly. $ sudo service ntp status |
A compliant run must use the versions of CBTOOL, Cassandra, and Hadoop packages/source code shipped with the kit.
Obtain the SPEC Cloud Benchmark Kit
If you do not already have the benchmark kit, please use the order page form to obtain the SPEC Cloud IaaS 2018 Benchmark kit. Keep a copy of the distributed kit on the cbarchive host, if it is different from cbharness.
Install the SPEC Cloud Benchmark Kit
In the operating system setup sections you instantiated a virtual machine with the required supporting packages, kernel/system settings, and required user accounts. The virtual machine (VM) now needs the SPEC Cloud benchmark.
|
Action |
Linux command/output |
|
Log onto cbharness as cbuser, or go to cbuser’s home directory, unpack the kit |
$ cd ~cbuser/ $ unzip spec_cloud_iaas_2018*.zip |
|
Verify your directory contains these subdirectories and files: |
$ ls ~/ |
|
Copy SSH keys to be used and restrict access permissions |
$ cd ~/.ssh $ cp id_rsa id_rsa.pub ~/osgcloud/cbtool/credentials $ cd ~/osgcloud/cbtool $ chmod 400 cbtool/credentials/cbtool_rsa $ chmod 400 cbtool/credentials/cbtool_rsa.pub |
|
You may need to upgrade pip before running CBTOOL |
$ sudo pip install
--upgrade pip |
A compliant run must use the versions of CBTOOL, Cassandra, and Hadoop packages/source code shipped with the kit.
Install CBTOOL
Now, we are ready to install CBTOOL. Since the installation script tries to verify and explore the cloud environment, the CBTOOL installer may need multiple runs to fully work through certain dependencies.
Initial Installation
Here are the command(s) needed for the initial CBTOOL install, and a partial output from its self verification steps. The full output can be found in this Appendix section.
|
$ cd ~/osgcloud/ |
|
Installing
dependencies for Cloud Rapid Experimentation Analysis
and Toolkit (cbtool) on this node.........
|
In this initial Orchestrator setup session, some files are missing. That is expected.
Successful (Subsequent) CBTOOL Installation
Sometimes there are circular dependencies that eventually disappear. Keep rerunning the install command until there are no issues. Here is partial output of a successful installation (orchestrator) run:
|
ubuntu@cbtool-spec $ cd
~/osgcloud/cbtool
|
Tell CBTOOL About Your Cloud
Before CBTOOL can manage and manipulate the Cloud Under Test, it has to know both operating system and cloud manager specific settings.
Common Steps
If your Linux login username on the VM is ubuntu, then find the file, ubuntu_cloud_definitions.txt. If the file does not exist, rerun the CBTOOL installation.:
$ cd
/home/ubuntu/osgcloud/cbtool/configs
$ ls
cloud_definitions.txt ubuntu_cloud_definitions.txt
templates
The cloud name (STARTUP_CLOUD) configuration key must also be set in osgcloud_rules.yaml file. The distributed kit sets CBTOOL to use simulated clouds, which is useful for verifying that the basic CBTOOL installation works. If the instructions were followed, the file should be in ~/osgcloud/driver and the cloud name value will appear in the output text.
Cloud Manager: OpenStack Parameters
First. SPEC has tested various OpenStack managed clouds during the development cycle. However, the API changes frequently. Please contact SPEC for specific version guidance.
The detailed CBTOOL configuration instructions can be found in Appendix D. Set the appropriate keys in these sections in the ubuntu_cloud_definitions.txt file (assuming the user name is ubuntu).
[USER-DEFINED :
CLOUDOPTION_MYOPENSTACK]
OSK_ACCESS = http://PUBLICIP:5000/v2.0/ #
Address of controlled node (where nova-api runs)
OSK_CREDENTIALS =
admin-admin-admin #
user-tenant-password
OSK_SECURITY_GROUPS =
default # Make
sure that this group exists first
OSK_INITIAL_VMCS =
RegionOne #
Change "RegionOne" accordingly
OSK_LOGIN =
cbuser # The
username that logins on the VMs
OSK_KEY_NAME =
spec_key # SSH
key for logging into workload VMs
OSK_SSH_KEY_NAME =
spec_key # SSH
key for logging into workload VMs
OSK_NETNAME = public
and replace the section under OSK_CLOUDCONFIG with the following:
[VM_TEMPLATES :
OSK_CLOUDCONFIG]
CASSANDRA = size:m1.medium,
imageid1:cb_speccloud_cassandra_2120
YCSB = size:m1.medium, imageid1:cb_speccloud_cassandra_2120
SEED = size:m1.medium, imageid1:cb_speccloud_cassandra_2120
HADOOPMASTER = size:m1.medium,
imageid1:cb_speccloud_hadooop_275
HADOOPSLAVE = size:m1.medium, imageid1:cb_speccloud_hadoop_275
SPEC recommends using the admin_user/tenant for initial testing. Once you are familiar with the harness, you can use a different user/tenant with appropriate permissions.
Now get ready to set up CBTOOL for a experiment.
Cloud Service: Amazon EC2
Connecting to EC2 requires AWS access key id, the name of current security group, and AWS secret access key. The AWS access and the AWS secret access key can be obtained from the security dashboard on AWS.
Make changes in ubuntu_cloud_definitions.txt to configure it to talk to the Amazon EC2 cloud:
$ vi cloud_definitions.txt
and replace the section under CLOUDOPTION_MYAMAZON with the following.:
[USER-DEFINED :
CLOUDOPTION_MYAMAZON]
EC2_ACCESS =
AKIAJ36T4WERTSWEUQIA #
This is the AWS access key id
EC2_SECURITY_GROUPS =
mWeb # Make
sure that this group exists first
EC2_CREDENTIALS = GX/idfgw/GqjVeUl9PzWeIOIwpFhAyAOdq0v1C1R #
This is the AWS secret access key
EC2_KEY_NAME = YOURSSHKEY
# Make sure
that this key exists first
EC2_INITIAL_VMCS = us-west-2:sut
# Change
"us-east-1" accordingly
EC2_SSH_KEY_NAME = cbtool_rsa
# SSH key for
logging into workload VMs
EC2_LOGIN = ubuntu
# The username
that logins on the VMs
Change STARTUP_CLOUD to MYAMAZON in ubuntu_cloud_definitions.txt.
Now get ready to set up CBTOOL for a experiment.
Cloud Service: Google Compute Engine
Connecting to GCE requires you to configure authentication for the “gcloud” CLI on the CBTOOL Orchestrator node. The pieces of information required on this process are basically the ID (not project name or number) for two “projects” ( a GCE-specific term): one that contains the pre-created images for different workloads (which requires “view-only” access to the user) and one where the actual instances will be launched. Almost needless to say, they can be the same.
- Configuring gcloud CLI authentication
- All gcloud-related binaries are already present on the node, installed during the image preparation.
- Execute gcloud auth login --no-launch-browser. This command will output an URL that has to be accessed from a browser. It will produce an authentication string that has to be pasted back on the command’s prompt.
- Execute gcloud config set project YOUR-PROJECT-ID, where YOUR-PROJECT-ID is the ID of the project.
- Test the success of the configuration authentication by running a command such as gcloud compute machine-types list.
Make changes in ubuntu_cloud_definitions.txt to configure it to talk to Google Compute Engine cloud:
$ vi cloud_definitions.txt
and replace the section under CLOUDOPTION_MYGCE with the following.:
[USER-DEFINED :
CLOUDOPTION_MYGCE ]
GCE_ACCESS =
project_name_for_images,project_name_for_instances #
Obtained with "gcloud info".
GCE_SECURITY_GROUPS = cloudbench
# Currently, not used
GCE_CREDENTIALS = ABCDEFGHIJKLMNOPQRSTUVXYWZ01234567890-+* #
Currently, not used
GCE_INITIAL_VMCS = us-east1-b:sut
# Change "us-east1-b" accordingly
GCE_LOGIN = cbuser
Change STARTUP_CLOUD to MYGCE in ubuntu_cloud_definitions.txt
Now get ready to set up CBTOOL for a experiment.
Cloud Service: Digital Ocean
Connecting to DigitalOcean requires only a Bearer (access) token. If you don’t have an SSH key ID chosen already, the benchmark will attempt to upload one into your account for you (based on the configuration below). Getting an Bearer token can be done by going to https://cloud.digitalocean.com and clicking on “API”.
Make changes in ubuntu_cloud_definitions.txt to configure it to talk to the Digital Ocean cloud:
$ vi ubuntu_cloud_definitions.txt
and update the relevant section variables of the file to include these values:
[USER-DEFINED]
[USER-DEFINED : CLOUDOPTION_MYDIGITALOCEAN ]
DO_INITIAL_VMCS =
nyc3 # VMC ==
DO data center
#(we don't
have availability zones yet)
DO_CREDENTIALS =
tag:bearer_token #
(your DigitalOcean access token)
# for
http://api.digitalocean.com
# where the
tag can be arbitratry
# We support
multi-tenancy, so you can add additional
# accounts
automatically separated by semicolons.
DO_SSH_KEY_NAME =
cbtool_rsa #
Upload credentials/your_custom_private_key_rsa.pub
# to
DigitalOcean or tell us where your private
# key is via
cloud-init
DO_KEY_NAME =
ubuntu_cbtool #
If you let cbtool upload your key for you, it will
# take this
name in your DigitalOcean account
# (based on
your username)
# Otherwise,
override this with the key to match the
# one you have
already uploaded to your account
DO_LOGIN =
root # Change
this to the username used within the guest
# VMs that
will be used during the benchmark
[VM_DEFAULTS]
ABORT_AFTER_SSH_UPLOAD_FAILURE = $False # Again,
by default, we will try to upload
# your SSH key
for you.
# DigitalOcean
does not support duplicate keys, in
# case you
already have one there.
Example DigitalOcean datacenters:
|
DigitalOcean Region Names |
API Identifier |
|
Bangalore 1 San Francisco 2 Amsterdam 3 Amsterdam 2 Frankfurt 1 London 1 New York 1 New York 3 San Francisco 1 Singapore 1 Toronto 1 |
blr1 sfo2 ams3 ams2 fra1 lon1 nyc1 nyc3 sfo1 sgp1 tor1 |
# OPTIONAL: If you have
not already prepared your own images, DigitalOcean,
# maintains public images that "just work" already. However,
if you have prepared your
# images per our documentation, you would use them like this:
# These "imageids" are exactly the same names as the one in
your DigitalOcean account:
[VM_TEMPLATES : CLOUDOPTION_MYDIGITALOCEAN ]
TINYVM = size:512mb, imageids:1,
imageid1:name_of_snapshot_in_your_digitalocean_account
CASSANDRA = size:4gb, imageids:1,
imageid1:name_of_snapshot_in_your_digitalocean_account
YCSB = size:4gb, imageids:1,
imageid1:name_of_snapshot_in_your_digitalocean_account
SEED = size:4gb, imageids:1,
imageid1:name_of_snapshot_in_your_digitalocean_account
HADOOPMASTER = size:4gb, imageids:1,
imageid1:name_of_snapshot_in_your_digitalocean_account
HADOOPSLAVE = size:4gb, imageids:1,
imageid1:name_of_snapshot_in_your_digitalocean_account
# OPTIONAL: It's very likely that your laptop/server hosting
cbtool is not directly
# addressible by DigitalOcean, in which case you'll need to
use VPN support:
# With the below configuration, cbtool will automatically
bootstrap DigitalOcean virtual
# machines to join the VPN using cloud-config userdata so that
your benchmark VMs and your
# laptop/server networks are reachable to each other.
Application-specific traffic will
# remain inside the DigitalOcean cloud, not over the VPN.
# Refer to this link for more detailed information:
https://github.com/ibmcb/cbtool/wiki/HOWTO:-Use-VPN-support-with-your-benchmarks
[VPN : CLOUDOPTION_MYDIGITALOCEAN ]
SERVER_IP = xxx.xxx.xxx.xxx # Address of a public OpenVPN
server configured using the files from
cbtool/configs/generated after a first-time cbtool run
SERVER_BOOTSTRAP = 10.9.0.6 # Just a guess. The tool will
auto-correct this as your laptop's IP address changes.
NETWORK = 10.9.0.0 # the /16 or /24 network address with
respect to the SERVER_BOOTSTRAP
SERVER_PORT = 1194
[VM_DEFAULTS : CLOUDOPTION_MYDIGITALOCEAN ]
USE_VPN_IP = $True
VPN_ONLY = $True
USERDATA = $True
# Block storage. Do you want your VMs to use block storage
(externally
# attached volumes) during a test?
CLOUD_VV = 10 # attach 10GB volumes to all VMs
Multi-tenancy: Currently, DigitalOcean has an API request limit of 5000 requests / hour. If you plan to create more than a couple hundred virtual machines, you will hit this limit very quickly. Using multiple DigitalOcean accounts at the same time is the current solution to get around this limit. In multi-tenancy mode, SPEC Cloud 2018 Benchmark will automatically round-robin assign virtual machines to all the accounts in the configuration file to work around this API limit. List these additional accounts as a simple list of comma-separated values to the configuration file instead of one, like this:
[USER-DEFINED :
CLOUDOPTION_MYDIGITALOCEAN ]
DO_CREDENTIALS = tag:token1;tag2:token2;tag3:token3
where the tag can be arbitrary
SPEC also recommends setting the value of “update_attempts” to 180 in the ~/osgcloud/driver/osgcloud_rules.yaml file.
Finally, change STARTUP_CLOUD to MYDIGITALOCEAN in the ubuntu_cloud_definitions.txt file.
Now get ready to set up CBTOOL for a experiment.
2.3 Setup/Test Base SPEC Cloud Benchmark
At this point, the environment specific settings are done. Now, CBTOOL sets up the SPEC Cloud IaaS 2018 Benchmark’s base test environment. Afterwards, a quick test verifies the installed files and simpler settings.
SPEC Cloud Installation
|
$ cd
~/osgcloud/cbtool/ |
|
Cbtool
version is "7b33da7" |
Verify Servers and Services
These packages and 3rd-party software were usually installed using copies included with the benchmark distribution kit. However, a few are retrieved during the automated installation steps. These verify the correct versions are installed and works.
|
Reason |
Linux command/output |
|
Check MongoDB version installed. (Not shipped with the SPEC Cloud IaaS 2018 Benchmark kit, but installed during CBTOOL installation.) |
$ mongo --version |
|
Check redis version installed. CBTOOL and benchmark was tested this redis version. If later benchmark installs retrieves a newer redis version that causes problems, install this version from the distributed benchmark kit. |
$ redis-server -v |
|
Check (and restart?) redis server listing on external network interfaces (not 127.0.0.1). |
$ netstat -lpn | grep 6379 |
Verify Python Package Dependencies
Check that CBTOOL required pip packages were installed and resembles this list.
(Assumes a direct Internet access is available, or the Python packages are on an internal Pypl repository. This leads to the official PIP User Guide’s python package installation instructions.)
The pip packages installed on the benchmark harness machine and their version should resemble this list:
|
$ sudo pip list |
|
|
|
apache-libcloud
(0.17.0) |
oslo.config (1.11.0) |
python-novaclient
(2.25.0) |
Test Base Benchmark on a Simulated Cloud
The full benchmark run has many moving parts not yet set up at this point in the install process - no bootable images, instances, or tested connectivity between benchmark harness and cloud. However at this stage, it is possible to run a tiny test run of the minimal installation using the built-in simulation mode. The simulation mode gives a flavor of the benchmark within a few minutes, avoiding the vagaries of an actual (working) cloud. No real instances are created. Nor are the real workloads run. Instead, CBTOOL use probability distributions to create ‘fake’ instances and workload metrics.
We highly recommend performing this step, because it ensures the installation works and generates SPEC Cloud reports / submissions normally.
Running the Simulated Cloud
Each SPEC Cloud IaaS 2018 Benchmark run must specify an experiment name - here, RUN2. Each experiment’s settings and resulting data and logs will be located under the (configurable) results_dir path.
To get started, open two terminals into the cbharness machine.
|
Task |
Terminal 1 |
Terminal 2 |
|
Set results directory and do not create support data |
$ cd ~/osgcloud/driver instance_support_evidence: false |
|
|
Reset cbtool for new experiment |
$ cd ~/osgcloud/cbtool $ ./cb --soft_reset |
|
|
Start simulated experiment named RUN2 |
|
$ cd
~/osgcloud/driver |
|
Go to RUN2’s result files |
$ cd ~/results/RUN2/perf $ ls |
|
|
Overall data flow result files |
$ cd ~/results/RUN2/perf_dir |
|
More details on the simulated cloud can be found on CBTOOL external documentation
Data flow
The following picture shows how different files and directories are generated as part of the run.

2.4 Create Reference Images
The SPEC IaaS Benchmark performs best under consistent conditions. One method is to install and configure a reference operating system image that has the desired patches, software and configurations already defined and/or installed. These reference workload images simplify the deployment process during the actual benchmark run.
Creating and storing the actual reference image depends on the cloud management system. The following sections do not provide specific cloud manager commands, only generic tasks that depends on you to map to the corresponding command(s).
Workload Images
SPEC Cloud IaaS 2018 Benchmark has two workloads: YCSB and K-Means. The cleanest scenario is to run each workload in different images.
- Create a common image and install the “null” workload. Make a snapshot of this instance, we will call INSTWKBASE.
- Create a INSTWKBASE instance and install Cassandra and YCSB. Take a snapshot of this instance.
- Create a INSTWKBASE instance and install Hadoop and KMeans. Take a snapshot of this instance.
Set Up Common Ubuntu Workload Image
The CBTOOL github wiki has instructions on how to prepare a workload image for your cloud.
https://github.com/ibmcb/cbtool/wiki/HOWTO:-Preparing-a-VM-to-be-used-with-CBTOOL-on-a-real-cloud
SPEC members have created QCOW2 images for the following hardware and Ubuntu distributions.
|
Hardware |
Distribution Version |
Archive URL |
|
x86_64 |
Ubuntu |
The instructions below can be used to prepare a base QCOW2 image for Cassandra or KMeans workloads.
- Download an Ubuntu image. SPEC has tested with the versions listed above.
- Upload the image in your cloud using instructions specific to your cloud.
- Start a new VM using this Ubuntu image using instructions specific to your cloud. Note the assigned virtual IP (yourVMIP) of this new VM.
- Log into your new VM:
$ ssh -i YOURKEY.PEM ubuntu@yourVMIP - Install and set up the VM’s system files from the “Install Your Operating System” through to the “Install the SPEC Cloud Benchmark” steps.
- Test ssh connectivity to your VM from
benchmark harness machine:
$ cd ~/osgcloud/
$ ssh -i cbtool/credentials/cbtool_rsa cbuser@YOURVMIP - Install Java (example):
$ sudo apt-get install openjdk-8-jdk -y
$ java -version
java version "1.7.0_75"
OpenJDK Runtime Environment (IcedTea 2.5.4) (7u75-2.5.4-1~trusty1)
OpenJDK 64-Bit Server VM (build 24.75-b04, mixed mode) - Setup password-based ssh for the VM:
$ vi /etc/ssh/sshd_config
PasswordAuthentication yes - Upload the image in your cloud using instructions specific to your cloud.
- Install cloud-init as cbuser. But, skip this if your cloud does not support cloud-init:
$ sudo apt-get install
cloud-init
Configure cloud-init
$ sudo vi /etc/cloud/cloud.cfg
runcmd:
- [ sh, -c, cp -rf /home/ubuntu/.ssh/authorized_keys \
/home/cbuser/.ssh/authorized_keys ]
$sudo dpkg-reconfigure cloud-init
Install null workload.
This installs all CBTOOL dependencies for the workload image.
$ cd /home/cbuser/osgcloud/
$ cbtool/install -r workload --wks nullworkload
If there are any errors, rerun the command until it exits without any errors. A successful output should return the following:
“All dependencies are in place”
Snapshot Common Workload Image
Remove the hostname added in /etc/hosts and take a snapshot of this VM - previously named INSTWKBASE, above. The snapshot instructions vary per cloud.
The cloud manager should be able to instantiate a new VM using this snapshot image. When basic remote SSH access is verified, then go ahead and delete the base VM.
Use INSTWKBASE as the base when preparing specific workload images.
Setup Cassandra and YCSB Workload Image
Cassandra and YCSB are installed on the same image. These instructions assume that you start with the INSTWKBASE image created earlier, and use the respective software packages included in the SPEC IaaS 2018 Benchmark kit.
Install Cassandra
Install from the kit’s Cassandra debian package using the following commands:
$ cd
~/osgcloud/workloads/cassandra/
$ sudo dpkg -i workloads/cassandra/cassandra_2.1.20_all.deb
Instructions to install from the official Cassandra repository are in Appendix E
Verify that Cassandra version 2.1.20 is installed:
$ sudo dpkg -l | grep cassandra
Install YCSB
Install from the benchmark kit’s YCSB tar file using the following commands :
$ tar -xzvf
~/workloads/ycsb/ycsb-0.4.0.tar.gz
$ mv ycsb-0.4.0 ~/YCSB
Prepare YCSB Workload Image
- Remove the IP address and hostname added to /etc/hosts.
- configure CBTOOL to incorporate this
workload:
$ cbtool/install -r workload –wks ycsb
$ cbtool/install -r workload –wks cassandra_ycsb
Capture the VM using your cloud capture tools (snapshot etc). This workload is ready for the benchmark tests.
Setup KMeans and Hadoop Workload Image
HiBench and Mahout are installed on the same iamge. These instructions assume that you start with the INSTWKBASE image created earlier, and use the respective software packages included in the SPEC IaaS 2018 Benchmark kit. The resulting image is ready to join the configured Hadoop file system when instantiated.
Acknowledgements:
http://tecadmin.net/setup-hadoop-2-4-single-node-cluster-on-linux/
Install Hadoop
Set up the user account and group before installing the Hadoop package.
|
Reason |
Linux command/output |
|
Create hadoop group and add cbuser to it |
$ sudo addgroup hadoop
|
|
Test ssh access to localhost works without password. If not, add your public key to cbuser’s ~/.ssh/authorized_keys file: |
$ ssh localhost /bin/true $ echo $? |
|
Either use the Hadoop 2.7.5 from the benchmark’s kit |
$ cd ~cbuser |
|
|
|
|
Extract files and move Hadoop to /usr/local/hadoop directory |
$ tar -xzvf
hadoop-2.7.5.tar.gz |
Setup Hadoop Configuration
Make the changes to the following files
|
~/.bashrc environment variables |
|
|
Set JAVA_HOME and HADOOP variables |
Find the path where Java has been installed to set the JAVA_HOME environment variable using the following command: $ sudo update-alternatives --config java For example, if OpenJava JDK 1.7.0 was installed, then: $ sudo update-alternatives
--config java Add that path and the Hadoop installation to the end of ~/.bashrc:
JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.85-2.6.1.2.el7_1.x86_64
export JAVA_HOME HADOOP_INSTALL PATH HADOOP_MAPRED_HOME export HADOOP_COMMON_HOME HADOOP_HDFS_HOME YARN_HOME HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR HADOOP_OPTS |
|
/usr/local/hadoop/etc/hadoop/hadoop-env.sh |
|
|
Set JAVA_HOME |
Add JAVA_HOME in the hadoop-env.sh file so that variable is available to Hadoop whenever it runs: JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.85-2.6.1.2.el7_1.x86_64 export JAVA_HOME
|
|
/usr/local/hadoop/etc/hadoop/core-site.xml |
|
|
Hadoop startup configuration properties |
This file contains configuration properties that Hadoop uses when starting. This file can override the default settings that Hadoop starts with by setting certain the property blocks: $ sudo mkdir -p
/app/hadoop/tmp Enter the following in between the <configuration> </configuration> tags: <configuration> |
|
/usr/local/hadoop/etc/hadoop/mapred-site.xml |
|
|
Set MapReduce framework |
This file specifies the framework used for MapReduce. By default, the /usr/local/hadoop/etc/hadoop/ folder contains the mapred-site.xml.template file which has to be copied to the name mapred-site.xml: $ cd
/usr/local/hadoop/etc Enter the following content in between the <configuration> </configuration> tags: <configuration> |
|
/usr/local/hadoop/etc/hadoop/hdfs-site.xml |
|
|
Set namenode and datanode directories |
Each host in the Hadoop cluster must specify the namenode and datanode directories it will use in this file. First create two directories which will contain the namenode and the datanode for this Hadoop installation. $ cd
/usr/local/hadoop_store Next, open the file and enter the following content in between the <configuration> </configuration> tag: <configuration> |
Create New Hadoop File System
The last Hadoop setup step creates the HDFS volume structure. :
|
Reason |
Linux command/output |
|
Source the ~/.bashrc file. Make sure sure that this host’s IP address and hostname are in /etc/hosts |
$ source ~/.bashrc
|
|
Create HDFS |
$ hdfs namenode
-format |
Install HiBench Mahout Software
The HiBench software is the last piece of this workload. Install it by moving its code from the $HOME directory.
$ mv ~/osgcloud/workloads/hibench ~/HiBench
Prepare HiBench Workload Image
- Remove the IP address and hostname added to /etc/hosts.
- Instantiate Hadoop for CBTOOL:
$ cbtool/install -r workload –wks hadoop
Take a snapshot of this VM. The image is ready to be used with the benchmark. It contains CBTOOL dependencies, Hadoop 2.6.0, HiBench 2.0, and Mahout 0.7.
Upload and Test Workload Images in Your Cloud
The actual commands to store the benchmark’s workload images is specific to each cloud manager.
Next, make sure these workload images work as bootable virtual machines:
- Choose at least a VM size of at least a 40 GB root disk.
- Boot from the image that was uploaded earlier.
- SSH into the VM using your configured user credentials (i.e. cbuser)
A successful login confirms the operating system and SSH credentials are set up correctly.
Launch VM and Launch AI
The next step is verifying CBTOOL can launch these virtual machines and start the appropriate workload services - combined, known as the Application Instance (AI).
Configure CBTOOL with OpenStack Uploaded Images
These workload image information needs to be added to your user name’s cloud definition file. For this section, the user name is ubuntu, the file name is ubuntu_cloud_definitions.txt, and the cloud manager is OpenStack.
First, edit your user name’s the cloud definitions file:
|
$ vi ubuntu_cloud_definitions.txt |
Next, add the [VM_TEMPLATES : OSK_CLOUDCONFIG] below this line
|
[VM_TEMPLATES :
OSK_CLOUDCONFIG] #
setting various CBTOOL roles and images # ubuntu images CASSANDRA = size:m1.medium, imageid1:cassandra_ubuntu |
Launch a VM and Test It
In your CBTOOL CLI, type the following:
cb> cldalter vm_defaults run_generic_scripts=False
cb> vmattach cassandra
This creates a VM from Cassandra image uploaded earlier. Once the VM is created, test ping connectivity to the VM. CBTOOL will not run any generic scripts into this image. Here is a sample output:
|
(MYOPENSTACK)
vmattach cassandra |
Configure /etc/ntp.conf with the NTP server in your environment and then run:
$ sudo ntpd -gq
$ echo $?
If the echo command returns zero (0), then instance reached the intended NTP server. If NTP is not installed in your image, then recreate the image with the NTP package installed.
Next, have CBTOOL reset the SUT to the test startup condition and then create a VM.
$ cd ~/osgcloud/cbtool
$ ./cb --soft_reset -c configs/ubuntu_cloud_definitions.txt
cb> vmattach cassandra
If VM creation succeeds, CBTOOL is able to copy scripts into the VM.
Adjust the number of attempts CBTOOL makes to test if VM is running - useful during testing if the SUT requires long provisioning time. However during a Compliant run, the benchmark sets this value to the maximum of average AI provisioning time measured during the Baseline phase:
cb> cldalter vm_defaults update_attempts 100
Repeat this process for all role names:
cb> vmattach ycsb
cb> vmattach hadoopmaster
cb> vmattach hadoopslave
Launch Workload: YCSB/Cassandra AI
At this point, the SUT is ready to launch a working application instance of the YCSB workload. Launch CBTOOL and then launch the first Cassandra AI.
$ ./cb --soft_reset -c configs/ubuntu_cloud_definitions.txt
cb> aiattach cassandra_ycsb
This creates a three instance Cassandra cluster, with one instance as YCSB, and two instances as Cassandra seeds. Note that the AI size for YCSB/Cassandra for SPEC Cloud IaaS 2018 Benchmark is seven (7) instances. This step simply verifies that a YCSB/Cassandra cluster is successfully created.
You will see an output similar to:
|
(MYOPENSTACK)
aiattach cassandra_ycsb |
If the AI fails to create because the load manager will not
run, please restart CBTOOL, and type the following:
$ cd ~/osgcloud/cbtool
$ ./cb --soft_reset
cb> cldalter
ai_defaults dont_start_load_manager True
cb> aiattach cassandra_ycsb
Then, manually try to execute the scripts that are causing problems.
Verify that results are appearing in CBTOOL dashboard. Here is a screenshot.

Launch Workload: KMeans/Hadoop AI
At this point, the SUT is ready to launch the first working K-Means application instance. These instructions assume that KMeans/Hadoop image was created using the above instructions and the CBTOOL session is still active from the above session.
This CLI block manually switches the environment to the KMeans/Hadoop values.
cb> typealter hadoop hadoop_home /usr/local/hadoop
cb> typealter hadoop java_home /usr/lib/jvm/java-7-openjdk-amd64
cb> typealter hadoop dfs_name_dir
/usr/local/hadoop_store/hdfs/namenode
cb> typealter hadoop dfs_data_dir
/usr/local/hadoop_store/hdfs/datanode
cb> aiattach hadoop
After the image is launched, you will see an output similar to the following at the CBTOOL prompt:
|
(MYOPENSTACK)
aiattach hadoop |
Verify that results appear in CBTOOL dashboard. Here is a screenshot.

3.0 Run SPEC Cloud IaaS 2018 Benchmark
At this point, all the components
are in place and tested and you are ready to run the SPEC
Cloud IaaS 2018 benchmark. This can be undertaken in a series
of steps, the benchmark has two major phases: baseline and
scale-out. Each phase can be run separately for
experimental and tuning purposes. However, a fully compliant
benchmark run requires all phases be completed in a single
invocation of the all_run.sh script. This type of test
includes running baseline and scale-out using a compliant
osgcloud_rules.yaml and is followed by FDR generation,
data collection, and deprovisioning of AIs.
The following sections describe how to set up the environment for both trial/tuning runs and the final compliant benchmark run.
3.1 Benchmark Configuration Parameters
The benchmark’s runtime parameters are located in the configuration file
$HOME/osgcloud/driver/osgcloud_rules.yaml
Common Parameters |
|
|
Keys / Purpose |
Setting(s) |
|
Directory where experiment results are stored. The baseline and Scale-out drivers parse the value of HOMEDIR to the Linux user’s home directory. Each set of related results, logs, and related files is stored in a subdirectory set to the experiment’s identifier (RUNID) plus timestamp. |
|
|
results_dir: |
HOMEDIR/results |
|
Changes NTP Time Server from default to the list of comma separated IP addresses or DNS host names (no space in the list) |
|
|
.timeserver: |
time-a-b.nist.gov,time.nist.gov |
|
The time to provision an instance can vary across your cloud. These two parameters determine how long CBTOOL should wait before declaring a VM creation as “failed”. A VM is successfully provisioned if it responds to a SSH remote command. |
|
|
vm_defaults: update_frequency: |
# Control how long to verify VM creation 60 # Max attempts to
determine provisioned VM |
|
Define the list of workload logical names, and the login user name and (sub)directory where benchmark tools are installed. |
|
|
vm_templates: SEED: YCSB: HADOOPMASTER: HADOOPSLAVE: |
# Section defining Images and login info login=cbuser,
remote_dir_name=cbtool |
Supporting Evidence Parameters |
|
|
Keys / Purpose |
Setting(s) |
|
The default parameters assume that the user name in your workload images is cbuser, support evidence directory is in HOMEDIR/results/EXPID/instance_evidence_dir , and osgcloud is in HOMEDIR/osgcloud |
|
|
instance_user: instance_keypath: support_evidence_dir: support_script:
cloud_config_script_dir: |
cbuser HOMEDIR/osgcloud/cbtool/credentials/cbtool_rsa HOMEDIR/support HOMEDIR/osgcloud/driver/support_script/collect_support_data.sh HOMEDIR/osgcloud/driver/support_script/cloud_config/ |
|
These keys determine whether or not CBTOOL collects VM supporting evidence - required for a compliant run. CBTOOL collects that category’s supporting evidence when set to true. Set these to false while you test various benchmark phases. Host_support_evidence is not required for public cloud providers |
|
|
instance_support_evidence: host_support_evidence: |
true |
|
SUT Tuning Parameters |
|
|
Keys / Purpose |
Setting(s) |
|
Set the maximum AIs to be provisioned or number of AIs from which results is received to specific values. |
|
|
maximum_ais: reported_ais: |
24 |
|
During the initial Scale-out fine tuning phase, ignore the stopping conditions |
|
|
ignore_qos_when_max_is_set: |
false |
3.2 Test and Tune the SUT & SPEC Cloud
All the SPEC Cloud IaaS 2018 benchmark steps use the script
~cbuser/osgcloud/driver/all_run.sh.
Usage: ./all_run.sh -e|--experiment OSG_EXPID
[-r|--rules OSG_RULES.yaml]
[-c|--cbtool cbtool executable path]
[-s|--step all | check | kmeans_baseline | ycsb_baseline |
all_baseline | scale_out | scale_out_NC | fdr | eg
][-b|--baseline_yaml baseline yaml path]
[ -y|--yes ]
All the It
should be noted that the all_run.sh script experiment ID shown as OSG_EXPID above or SPECRUNID elsewhere in
this guide is used as the directory name for the experiment's
data in ~/results. The all_run.sh script will not
overwrite an existing directory by the same name.
Using a naming convention that enforces uniqueness can be
useful to avoid conflict or deleting directories
manually. The example below adds the date and time to a
base experiment ID:
./all_run.sh -e MyExpID`date +%m%d%H%M` -s all
First Baseline Phase Test With Your Cloud
This section assumes that CBTOOL is already started and has successfully connected with your cloud.
Set Up Workload Baseline Parameters
In Baseline phase, the benchmark harness machine creates five application instances (**AI) for the two workloads, KMeans and YCSB. Each iteration sees new instances provisioned, data generated, the load generator run, data deleted, and lastly, the instances deleted. This is controlled by the following parameters, with values set for a compliant run:
iteration_count: 5
ycsb_run_count: 5
kmeans_run_count: 5
destroy_ai_upon_completion: true
Both ycsb_run_count and kmeans_run_count must be at least 5 for a compliant run. They can be larger to generate a stable and valid Baseline data set.
A total of 35 and 30 instances are created and destroyed for each YCSB and KMeans workload, respectively.
A “run” consists of data creation, load generator instantiation, and data deletion, which is controlled by run_count parameter. If a tester knows that in their cloud, baseline results will be worse than Scale-out phase results (due to performance isolation etc), they must set the run_count to 5 or higher before starting a compliant run.
For the compliant run, iteration_count must be at least 5, and destroy_ai_upon_completion must be true.
Cloud Name
Please make sure that the cloud name in osgcloud_rules.yaml matches the cloud name in the CBTOOL configuration.:
cloud_name: MYCLOUDNAME
CBTOOL configuration file is present in
~/osgcloud/cbtool/configs/*_cloud_definitions.txt
YCSB Baseline Measurement
Start YCSB Baseline Phase
The YCSB baseline script is run as follows:
$ ./all_run.sh -e SPECRUNID -s ycsb_baseline
where SPECRUNID indicates the run id that will be used for the YCSB baseline phase.
The script logs the run to a file and the DEBUG level output is sent to the console. The results for this experiment are present in:
$ cd ~/results/SPECRUNID/perf/
If 5 iterations were run (required for a compliant run), the tester should find 5 directories starting with SPECRUNIDYCSB in the ~/results/SPECRUNID/perf directory.
The following files will be present in the directory. The date/time in file and directory names will match the run’s date/time:
baseline_SPECRUNID.yaml
osgcloud_ycsb_baseline_SPECRUNID-20180111233732UTC.log
SPECRUNIDYCSBBASELINE020180111233732UTC
SPECRUNIDYCSBBASELINE120180111233732UTC
SPECRUNIDYCSBBASELINE220180111233732UTC
SPECRUNIDYCSBBASELINE320180111233732UTC
SPECRUNIDYCSBBASELINE420180111233732UTC
K-Means Baseline Measurement
Preparation
The following parameters in osgcloud_rules.yaml describes how Hadoop is set up in the instance image. The default parameters values are shown below:
java_home: /usr/lib/jvm/java-7-openjdk-amd64
hadoop_home:
/usr/local/hadoop
dfs_name_dir:
/usr/local/hadoop_store/hdfs/namenode
dfs_data_dir:
/usr/local/hadoop_store/hdfs/datanode
Change these to match your file locations and java version.
Starting KMeans Baseline Phase
The KMeans baseline script is run as follows:
$ ./all_run.sh -e SPECRUNID -s kmeans_baseline
where SPECRUNID indicates the run id that will be used across the KMeans baseline phase.
The script logs the run to a file and the DEBUG level output is sent to the console. The results for this experiment are present in:
$ cd ~/results/SPECRUNID/perf/
If five (5) iterations are run (required for a compliant run), the tester should find five (5) directories starting with SPECRUNIDKMEANS in the ~/results/SPECRUNID/perf directory.
Following files will be present in the directory. The date/time in file and directory names will match the date/time of your run:
baseline_SPECRUNID.yaml
osgcloud_kmeans_baseline_SPECRUNID-20180111233302UTC.log
SPECRUNIDKMEANSBASELINE020180111233302UTC
SPECRUNIDKMEANSBASELINE120180111233302UTC
SPECRUNIDKMEANSBASELINE220180111233302UTC
SPECRUNIDKMEANSBASELINE320180111233302UTC
SPECRUNIDKMEANSBASELINE420180111233302UTC
Configuring Supporting Evidence Collection
Make sure that supporting evidence parameters are set correctly in the osgcloud_rules.yaml file.:
support_evidence:
instance_user: cbuser
instance_keypath:
HOMEDIR/osgcloud/cbtool/credentials/cbtool_rsa
support_script:
HOMEDIR/osgcloud/driver/support_script/collect_support_data.sh
cloud_config_script_dir:
HOMEDIR/osgcloud/driver/support_script/cloud_config/
###########################################
# START instance support evidence flag is true
# for public and private clouds. host flag
# is true only for private clouds or for
# those clouds where host information is
# available.
###########################################
instance_support_evidence: true
host_support_evidence: false
###########################################
# END
###########################################
instance_user parameter indicates the Linux user that is used to SSH into the instance. It is also set in the cloud configuration text file for CBTOOL.
instance_key_path indicates the SSH key that is used to SSH into the instance. Please make sure that the permissions of this file are set to 400 (chmod 400 KEYFILE)
support_script indicates the path of the script that is used to gather supporting evidence.
cloud_config_script_dir indicates the path where scripts relevant to gathering cloud configuration are present. These scripts differ from one cloud to the other.
instance_support_evidence indicates that whether to collect supporting evidence from instances. This flag is ignored for simulated clouds. For the baseline testing phase, set this flag to false.
Environment Parameters for Submission File
The tester must set appropriate values in osgcloud_environment.yaml file. The key/value pairs from this file are dumped into the submission file. These settings depend on the cloud type (whitebox or blackbox), the cloud manager, and accurate descriptions of all “machine” components in the cloud tested.
3.3 First Scale-out Test
Run Scale-out Phase
The first Scale-out test is run as
follows. It assumes that CBTOOL is already running and is
connected with your cloud. It is recommended that you
set reported_ais:8
in osgcloud_rules.yaml for the initial test to
start out and increase this once you see how your SUT
behaves.
$ ./all_run.sh -e
SPECRUNID_FIRST -s all
This is actually a full run,
but once this is done you should have one complete set of
baseline results and scale-out results. You'll be
able to run additional scale-out experiments using the
baseline results from this test.
The command for running just scale-out experiments is:
$
./all_run.sh -e SPECRUNID_NEW -s scale_out_NC -b \
~/results/SPECRUNID_FIRST/perf/baseline_SPECRUNID_FIRST.yaml \
--yes
The results and logs of Scale-out phase are present in the following directory, and these files are generated after a successful Scale-out phase completes, along with the FDR_SPECRUNID.html in the driver directory.:
$ ls ~/results/SPECRUNID/perf
elasticity_SPECRUNID.yaml
osgcloud_elasticity_SPECRUNID-20180111234204UTC.log
SPECRUNIDELASTICITY20180111234204UTC/
Where the timestamp in file and directory names is based on the date/time of the Scale-out phase start time.
Tips on
Running the Scale-out Phase
- Before starting Scale-out phase, it is best to restart CBTOOL if another Scale-out phase was run. There is no need to restart CBTOOL if only baseline phases were run.
- When testing the Scale-out phase, it is best to start with small number of AIs, such as 6 or 8.
- It is not necessary to run baseline phase every time before Scale-out phase. However, Scale-out phase needs the output of baseline phase (as a YAML) file to determine the stopping conditions.
- The instance provisioning time of a cloud under test may be long. Adjust the time CBTOOL waits to check for instance provisioning using the update_attempts parameter in osgcloud_rules.yaml file. It should be set to a value such that ( update_attemps x update_frequency ) never exceeds three (3) times the maximum baseline AI provisioning time of YCSB or KMeans workloads. For a compliant run, it must be set before the start of the experiment.
- Errors encountered during an Scale-out phase run can be found in CBTOOL log:
$ cd /var/log/cloudbench
$ grep ERROR *
- The tester can check for errors for specific AI by searching for an AI number.
- The errors can also occur during an AI_run for a workload. Examples of errors include:
|
Cassandra |
Create, Remove, List keyspace fail, or seeds fail to form a cluster. |
|
YCSB |
Data generation fails |
|
Hadoop |
Hadoop slaves fail to form a cluster |
|
KMeans |
Data generation fails |
- Instance names also include AI numbers. This can come handy when you are debugging Scale-out phase in your cloud.
- The tester can check for failed AIs by running the following command at the CBTOOL prompt:
cb> ailist failed
3.4 Generate a Submission File
At the tester's earliest
convenience they should document the details of their
cloud's configuration by copying osgcloud_environment_template.yaml
to osgcloud_environment.yaml. The tester should fill
out the details of its cloud environment (e.g., physical
machines for a Whitebox cloud, compute service models for a
Blackbox cloud) in osgcloud_environment.yaml. This ensures
that each test run contains the configuration details on the
SUT for future reference.
When the all_run.sh script completes a run
using -s|--step all, scale_out_NC, or fdr, a
submission file and the test's FDR html file are
automatically generated. Should the tester need to make
updates to the osgcloud_environment.yaml
file and the instructions below show how to regenerate these
files.
Create the Submission Files
Run the submission file generation step (assumes SPECRUN id was SPECRUNID):
$ cd ~/osgcloud/driver
$ ./all_run.sh --experiment
SPECRUNID --step
fdr
which updates the following files:
$ ls ~/results/EXPID/perf/
osgcloud_fdr_SPECRUNID-20190111234502UTC.log
fdr_ai_SPECRUNID.yaml
sub_file_SPECRUNID.txt
run_SPECRUNID.log
$ ls ~/osgcloud/driver/*SPECARUNID*
FDR_SPECRUNID.html
Generating HTML Report
Assuming the submission file set from the previous step, generate the HTML report with:
$ cd ~/osgcloud/driver
$ ./all_run.sh --experiment
SPECRUNID --step fdr
For Whitebox clouds, to include an architecture diagram of the cloud in PNG format in the HTML report as follows:
$ python osgcloud_fdr_html.py --exp_id SPECRUNID --networkfile cloud_schematic.png
The resulting HTML output file is named:
~/osgcloud/driver/FDR_SPECRUNID.html
Test Instance Supporting Evidence Collection
The following steps verifies that instance supporting evidence collection works properly. They assume that workload images have been created, the Linux user name is cbuser and SSH key path is ~/osgcloud/cbtool/credentials/cbtool_rsa.
Start CBTOOL and verify connections to Cloud Components
Launch an application instance of Cassandra or Hadoop:
cb> aiattach cassandra_ycsb
cb> aiattach
hadoop
Test instance supporting evidence collection
Run the supporting evidence instance script on CBTOOL machine to collect supporting evidence for an instance.
Create a directory where the results are stored and run the supporting evidence collection script:
$ mkdir /tmp/instance -p
$ cd ~/osgcloud/driver/support_script/
$ ./collect_support_data.sh remote_vm_sysinfo 10.146.5.41
cbuser \ ~/osgcloud/cbtool/credentials/cbtool_rsa
/tmp/instance/
SCRIPT INSTANCE/CASSANDA/HADOOP IPADDR IPOFINSTANCE LINUXUSER
SSHKEYPATH TARGETDIR
OUTPUT from machine running as an Application Instance:
$ tree /tmp/instance
|-----------------+-------------------------+
|-- date.txt |-- etc
|-- proc
|-- df.txt |-- fstab
|--
cmdline
|-- dpkg.txt |-- hosts
|--
cpuinfo
|-- hostname.txt |-- iproute2
|-- devices
|-- ifconfig.txt | |-- ematch_map
|-- meminfo
|-- lspci.txt | |-- group
|-- modules
|-- mount.txt | |--
rt_dsfield |-- partitions
|-- netstat.txt | |-- rt_protos
|-- swaps
|-- ntp.conf | |--
rt_realms `-- version
|-- route.txt | |--
rt_scopes
`-- var |
`-- rt_tables
`-- log |--
nsswitch.conf
`-- dmesg |--
security
| `-- limits.conf
`-- sysctl.conf
Test YCSB and Cassandra supporting evidence collection
Find the IP address of instance with YCSB role from CBTOOL (by typing vmlist on CBTOOL CLI). Then run the following commands:
$ mkdir /tmp/ycsb -p
$ ./collect_support_data.sh remote_vm_software 10.146.5.41
cbuser \ ~/osgcloud/cbtool/credentials/cbtool_rsa
/tmp/cassandra cassandra_ycsb
OUTPUT from machine with YCSB role:
$ tree /tmp/ycsb
/tmp/ycsb/
|-- javaVersion.out
|-- role
`-- YCSB
|-- custom_workload.dat
`-- workloads
|-- workloada
|-- workloadb
|-- workloadc
|-- workloadd
|-- workloade
|-- workloadf
`-- workload_template
Find the IP address of an instance with SEED role from CBTOOL (by typing vmlist on CBTOOL CLI). Then run these commands:
$ mkdir /tmp/seed -p
$ ./collect_support_data.sh remote_vm_software 10.146.5.41
cbuser \ ~/osgcloud/cbtool/credentials/cbtool_rsa /tmp/seed
cassandra_ycsb
OUTPUT from machine with Cassandra SEED role:
$ tree /tmp/cassandra
/tmp/
+-----------------------------------+
|-- cassandra
|-- cassandra_conf
| |-- du_datadir
|-- cassandra-env.sh
| |-- du_datadir_cassandra
|-- cassandra-rackdc.properties
| |-- du_datadir_cassandra_usertable |--
cassandra-topology.properties
| |-- nodetool_cfstats
|-- cassandra-topology.yaml
| `-- nodetool_status
|-- cassandra.yaml
|-- javaVersion.out
|-- commitlog_archiving.properties
`-- role
|-- logback-tools.xml
|-- logback.xml
`-- triggers
`-- README.txt
Test Hadoop Supporting Evidence Collection
Find the IP address of instance with HADOOPMASTER role from CBTOOL (by typing vmlist on CBTOOL CLI). Then run the following commands:
$ mkdir /tmp/hadoop -p
$ ./collect_support_data.sh remote_vm_software 10.146.5.41
cbuser \ ~/osgcloud/cbtool/credentials/cbtool_rsa /tmp/hadoop
hadoop
OUTPUT from machine with HADOOPMASTER role:
$ tree /tmp/hadoop/
/tmp/hadoop/
+--------------------------+
|-- hadoop
|-- hadoop_conf
| |-- datahdfs
|-- capacity-scheduler.xml
| |-- dfsadmin_report |--
configuration.xsl
| |-- du_datanodedir |--
container-executor.cfg
| |-- du_namenodedir |--
core-site.xml
| |-- input_hdfs_size |--
hadoop-env.cmd
| |-- output_hdfs_size |--
hadoop-env.sh
| `-- version
|-- hadoop-metrics2.properties
|-- javaVersion.out
|-- hadoop-metrics.properties
`-- role
|-- hadoop-policy.xml
|-- hdfs-site.xml
|-- httpfs-env.sh
|--
httpfs-log4j.properties
|--
httpfs-signature.secret
|-- httpfs-site.xml
|-- kms-acls.xml
|-- kms-env.sh
|--
kms-log4j.properties
|-- kms-site.xml
|-- log4j.properties
|-- mapred-env.cmd
|-- mapred-env.sh
|--
mapred-queues.xml.template
|-- mapred-site.xml
|--
mapred-site.xml.template
|-- masters
|-- slaves
|--
ssl-client.xml.example
|--
ssl-server.xml.example
|-- yarn-env.cmd
|-- yarn-env.sh
‘-- yarn-site.xml
4.0 Compliant Run For Result Submission
What is a Compliant Run?
A Compliant Run is a test run where the all the components of the Cloud SUT and Benchmark harness satisfies all SPECIaaS2018 Run and Reporting Rules. All hardware and software configuration details needed to reproduce the test should be collected using cloud and instance configuration gathering scripts referenced below. Sample scripts have been included with the kit to use as examples. The tester is responsible for writing or revising these scripts to ensure that data for their test environment is collected and a copy of their configuration gathering scripts are included in the submission. Configuration data that can not be collected by scripts but are required for the full disclosure report can be collected manually and included in the submission package.
4.1 Set Up Parameters
Please make sure that the following parameters are correctly set in the osgcloud_rules.yaml file.
Set the results directory. The recommendation is to keep the default results directory and use and appropriate SPECRUN id for a compliant run. In case the result directory needs to be set, change the following parameter:
results_dir: HOMEDIR/results
Instance support evidence flag must be set to true:
instance_support_evidence: true
Linux user id for instances and SSH keys that are used must be correctly set:
instance_user: cbuser
instance_keypath: HOMEDIR/osgcloud/spec_ssh_keys/spec_ssh
Cloud config supporting evidence flag must be set to true:
cloud_config_support_evidence: true
Ensure that appropriate cloud configuration scripts that invoke cloud APIs have been written and tested. The OpenStack scripts are provided in the following directory. The details of these scripts are present in Cloud Config Scripts from a Cloud Consumer Perspective:
HOMEDIR/osgcloud/driver/support_script/cloud_config/openstack/
Iteration count for baseline phase must be set to five:
iteration_count: 5
Timeserver field, if uncommented, must be the same as NTP servers used for benchmark harness machine. Please ensure that the NTP server is running on the machine specified in the parameter, NTP server is reachable from both the benchmark harness and test instance machines. All benchmark harness and test instance machines can resolve the hostname of NTP server (if specified):
#timeserver: 0.ubuntu.pool.ntp.org
QoS must not be ignored for a compliant run:
ignore_qos_when_max_is_set: false
Set limits on how many AIs, with maximum_ais (maximum ais that can be provisioned with success or error) and reported_ais (maximum AIs that can report results from one or more AI runs) should be set to a reasonable value for your cloud. Typically, reported_ais is set to a value that is smaller than maximum_ais. A good rule of thumb is to set it to half of maximum_ais:
maximum_ais: 24
reported_ais:
12
CBTOOL use the update_attempts and update_frequency values to determine when a provisioning attempt has failed. Set them to smaller values to force provisioning failures for testing. Your tests should find reasonable values for your cloud:
vm_defaults:
update_attempts: 60
update_frequency: 5
During a Compliant run, the benchmark computes the value for update_attempts based on the maximum of the average YCSB and KMeans AI provisioning times during Baseline phase.
Pre-run Checklist
Please make sure that you have done the following:
- Verify CBTOOL successfully creates an application instance (AI) by executing the commands in Launch a VM and Test It
- Verify that instance support evidence collection works. Follow the instructions in Testing Instance Supporting Evidence Collection to confirm successful gathering of instance supporting evidence prior to a run.
- Implement and successfully tested your scripts for gathering cloud configuration in HOMEDIR/osgcloud/driver/support_script/cloud_config directory. See section Cloud Configuration Gathering Scripts Through Cloud APIs for details.
- Measured baseline provisioning time and set the update_attempts to a value such that update_attempts times update_frequency is unlikely to exceed the maximum AI provisioning time measured during a compliant run.
- Set the instance_support_evidence and cloud_config_support_evidence flags to true in osgcloud_rules.yaml
- Ensure that other parameters are set up correctly as described in the earlier section.
4.2 Execute a Compliant Test
Begin at Quiescent State
Please have CBTOOL reset the SUT to a quiescent state before running the benchmark:
$ cd ~/osgcloud/cbtool
$ ./cb --soft_reset
Start Benchmark
Next in another terminal, run the entire benchmark as follows:
$ cd ~/osgcloud/driver
$ ./all_run.sh -e SPECRUNID
The all_run.sh script creates the directory named SPECRUNID, and then starts the run. If CBTOOL encounters an unexpected error during the Baseline or Scale-out phases, it terminates the benchmark The tester has to rerun the entire benchmark for a compliant run.
Once CBTOOL detects one of the pre-defined stopping conditions, it ends the benchmark run. The all_run.sh script automatically collects the supporting evidence from all baseline phase instances created and terminated after each run. During the Scale-out phase, the all-run.sh script only collects Supporting evidence once from created AI’s. The large number of AI’s during a Scale-out run (e.g., > 100) makes retrieving and storing the complete data set inadvisable.
4.3 Check Completed Compliant Run
As soon as the all_run.sh script ends, please verify the following:
- Results look reasonable, and meets expectations from prior test runs.
- Instance supporting evidence has been automatically collected from all instances. This information includes standard machine details as well as Hadoop and Cassandra specific configuration.
It takes 1-2 minutes to gather supporting evidence from all instances within an application instance. Depending on how many application instances were present, the supporting evidence gathering may take more or less time.
Describe Submission’s Cloud Under Test Environment
The tester can update the osgcloud_environment.yaml at the end of a compliant run to add more information or make corrections. Please take the following under consideration when updating this file:
- The contact information section will be used in the FDR and should be viable
- Preserve indentations or it will fail
- Do not delete semicolons
- Do not change or add keys except where explicitly directed
- Comments have a #, if the hash is removed the entry must be valid.
- “Notes:” sections are free format but MUST have a matching “End_Notes:” key.
- No tabs are allowed. Use spaces to do all indents.
- SUT_type: must either be blackbox or whitebox.
Afterwards, regenerate a new submission file:
$ ./all_run.sh -s fdr --exp_id SPECRUNID
Make sure the Cloud Under Test environment information is accurate in the revised submission file by generating the HTML report:
$ ./all_run.sh -s fdr --exp_id SPECRUNID --networkfile arch.png
where arch.png contains the instance configuration diagram (for Whitebox and Blackbox clouds) as well as the whitebox architecture diagram. See sample FDR for reference.
Automatically Collected Results by Scripts
If the results directory is not changed in osgcloud_rules.yaml, the entire benchmark results will have a directory structure located in:
$ ls ~/results/SPECRUNID/
+----------------------------------+
|-- cloud_config
|--
code
| |-- blackbox
| |-- cloud_config_scripts
| |-- image_instructions |
|-- harness_scripts
| |-- instance_arch_diag |
`-- white_box_sup_evid_scripts
| `-- whitebox
|-- harness
| |-- arch_diagram
| |-- config_files
| |-- cloud_mgmt_software |
|-- machine_info
| |-- compute_nodes
| `-- software
| `-- controller_nodes
`-- instance_evidence_dir
`-- perf
|--
baseline
|-- baseline_pre
|-- elasticity
|-- elasticity_post
|-- kmeans_baseline_post
`-- ycsb_baseline_post
The following files will exist in the perf directory after a successful run:
baseline_SPECRUNID.yaml
elasticity_SPECRUNID.yaml
fdr_ai_SPECRUNID.yaml
osgcloud_elasticity_SPECRUNID-20180111234204UTC.log
osgcloud_fdr_SPECRUNID-20180111234502UTC.log
osgcloud_kmeans_baseline_SPECRUNID-20180111233302UTC.log
osgcloud_rules.yaml
osgcloud_ycsb_baseline_SPECRUNID-20180111233732UTC.log
SPECRUNIDELASTICITY20180111234204UTC
SPECRUNIDKMEANSBASELINE020180111233302UTC
SPECRUNIDKMEANSBASELINE120180111233302UTC
SPECRUNIDKMEANSBASELINE220180111233302UTC
SPECRUNIDKMEANSBASELINE320180111233302UTC
SPECRUNIDKMEANSBASELINE420180111233302UTC
SPECRUNIDYCSBBASELINE020180111233732UTC
SPECRUNIDYCSBBASELINE120180111233732UTC
SPECRUNIDYCSBBASELINE220180111233732UTC
SPECRUNIDYCSBBASELINE320180111233732UTC
SPECRUNIDYCSBBASELINE420180111233732UTC
run_SPECRUNID.log
sub_file_SPECRUNID.txt
The baseline supporting evidence will be collected in the following directory with a subdirectory structure reflecting each AI:
$ ls ~/results/SPECRUNID/instance_perf_dir/baseline
|instance_evidence_dir/baseline/
|-- SPECRUNIDKMEANSBASELINE020180116002546UTC
| `-- ai_1
| |--
cb-root-CLOUDUNDERTEST-vm1-hadoopmaster-ai-1
| | |-- INSTANCE
| | `-- SW
| |--
cb-root-CLOUDUNDERTEST-vm2-hadoopslave-ai-1
| | |-- INSTANCE
| | `-- SW
| |-- [Repeat
for KMEANS SLAVES 2 to 5]
| ` …
|-- [Repeat for KMEANS BASELINE AI’s
2 to 5]
| …
|-- SPECRUNIDYCSBBASELINE020180116014230UTC
| `-- ai_6
| |--
cb-root-CLOUDUNDERTEST-vm31-ycsb-ai-6
| | |-- INSTANCE
| | `-- SW
| |--
cb-root-CLOUDUNDERTEST-vm32-seed-ai-6
| | |-- INSTANCE
| | `-- SW
| |-- [Repeat
for YCSB SEED Nodes 2 to 6]
| ` …
|-- [Repeat for YCSB BASELINE AI’s
2-5
| …
The INSTANCE directory contains files similar to:
INSTANCE/
+----------------------+----------------------+
|-- date.txt |--
ifconfig.txt |-- lspci.txt
|-- df.txt |--
netstat.txt |-- mount.txt
|-- dpkg.txt |-- ntp.conf
|-- route.txt
|-- etc
|-- proc
`-- var
|-- hostname.txt
For a Hadoop AI, the SW directory contains files similar to:
SW
|---------------------+
|-- hadoop |--
hadoop_conf
| |-- datahdfs
|------------------------------+
| |-- dfsadmin_report |-- capacity-scheduler.xml
|-- mapred-env.cmd
| |-- du_datanodedir |-- configuration.xsl
|-- mapred-env.sh
| |-- du_namenodedir |-- container-executor.cfg
|-- mapred-site.xml
| |-- input_hdfs_size |-- core-site.xml
|-- masters
| |-- output_hdfs_size |-- hadoop-env.cmd
|-- slaves
| `-- version |--
hadoop-env.sh
|-- yarn-env.cmd
|-- javaVersion.out |--
hadoop-metrics2.properties |-- yarn-env.sh
`-- role
|-- hadoop-metrics.properties ‘-- yarn-site.xml
|-- hadoop-policy.xml
|-- hdfs-site.xml
|-- httpfs-env.sh
|-- httpfs-log4j.properties
|-- httpfs-signature.secret
|-- httpfs-site.xml
|-- kms-acls.xml
|-- kms-env.sh
|-- kms-log4j.properties
|-- kms-site.xml
|-- log4j.properties
|-- mapred-queues.xml.template
|-- mapred-site.xml.template
|-- ssl-client.xml.example
|-- ssl-server.xml.example
For a Cassandra seed node, the SW directory contains files similar to:
SW/cassandra
+-----------------------------------+
|-- cassandra
|-- cassandra_conf
| |-- du_datadir
|-- cassandra-env.sh
| |-- du_datadir_cassandra
|-- cassandra-rackdc.properties
| |-- du_datadir_cassandra_usertable |--
cassandra-topology.properties
| |-- nodetool_cfstats
|-- cassandra-topology.yaml
| `-- nodetool_status
|-- cassandra.yaml
|-- javaVersion.out
|-- commitlog_archiving.properties
`-- role
|-- logback-tools.xml
|-- logback.xml
`-- triggers
`-- README.txt
The supporting evidence from instances in Scale-out phase is present at:
SPECRUNID/instance_evidence_dir/elasticity
In the example below, the supporting evidence for AI 11-19 is present:
`--
SPECRUNIDELASTICITY20180101061549UTC
|-- ai_11
| |-- cb-root-MYCLOUD-vm66-seed-ai-11
| |-- cb-root-MYCLOUD-vm67-ycsb-ai-11
| |-- cb-root-MYCLOUD-vm68-seed-ai-11
| |-- cb-root-MYCLOUD-vm69-seed-ai-11
| |-- cb-root-MYCLOUD-vm70-seed-ai-11
| |-- cb-root-MYCLOUD-vm71-seed-ai-11
| `-- cb-root-MYCLOUD-vm72-seed-ai-11
|-- ai_12
| |-- cb-root-MYCLOUD-vm73-hadoopmaster-ai-12
| |-- cb-root-MYCLOUD-vm74-hadoopslave-ai-12
| |-- cb-root-MYCLOUD-vm75-hadoopslave-ai-12
| |-- cb-root-MYCLOUD-vm76-hadoopslave-ai-12
| |-- cb-root-MYCLOUD-vm77-hadoopslave-ai-12
| `-- cb-root-MYCLOUD-vm78-hadoopslave-ai-12
|-- ai_13
| |-- [Similar to ai_12 Hadoop
structure]
| |-- …
|-- ai_14
| |-- [Similar to ai_11 YCSB
structure]
| |-- …
|-- ai_15
| |-- [Similar to ai_11 YCSB
structure]
| |-- …
|-- ai_16
| |-- [Similar to ai_12 Hadoop
structure]
| |-- …
|-- ai_17
| |-- [Similar to ai_11 YCSB
structure]
| |-- …
|-- ai_18
| |-- [Similar to ai_12 Hadoop
structure]
| |-- …
`-- ai_19
|-- [Similar to ai_11
YCSB structure]
|-- …
The instance and cloud configuration gathered using Cloud API/CLIs is present in the following files:
SPECRUNID/instance_evidence_dir/baseline_pre
SPECRUNID/instance_evidence_dir/kmeans_baseline_post
SPECRUNID/instance_evidence_dir/ycsb_baseline_post
SPECRUNID/instance_evidence_dir/elasticity_post
The configuration parameters for CBTOOL for a compliant run are written into:
SPECRUNID/harness/harness_config.yaml
Log Paths for Cassandra, YCSB, and Hadoop
If Cassandra is configured as specified in the "Setup Cassandra and YCSB" section above, the logs are available at:
/var/log/cassandra
YCSB logs are located in /tmp. Every data and generation run produces two log files, which CBTOOL automatically collects. The file names resemble:
tmp.CiM8PN2CUL
tmp.CiM8PN2CUL.run
Hadoop logs are available at:
/usr/local/hadoop/logs
Manually Added Information
In each run’s automatically created directory structure, the tester needs to manually collect some information. This information is described in the Run Rules document and available as a sample FDR for a Whitebox cloud. The information to be collected is listed below:
|-- cloud_config (to be
manually collected by the tester)
| |-- blackbox (remove for whitebox submission)
| |-- image_instructions
| |-- instance_arch_diag
| `-- whitebox (remove for blackbox submission)
| |-- arch_diagram
| |-- cloud_mgmt_software
| |-- compute_nodes
| `-- controller_nodes
|-- code (to be manually collected by the tester)
| |-- cloud_config_scripts
| |-- harness_scripts
| `-- white_box_sup_evid_scripts
|-- harness (to be manually collected by the tester)
| |-- config_files
| |-- machine_info
| `-- software
|-- instance_evidence_dir (automatically collected)
| |-- baseline
| |-- baseline_pre
| |-- elasticity
| |-- elasticity_post
| |-- kmeans_baseline_post
| `-- ycsb_baseline_post
`-- perf (automatically collected)
In particular, cloud_config for Whitebox needs to include scripts or other documentation used to configure the physical infrastructure for the cloud under test.
4.4 Submit Results
Submitting your SPEC Cloud IaaS 2018 Benchmark results means SPEC will publish accepted results on SPEC’s website and your organization and officially use them in publications. See the Run Rules for exact conditions.
Submissions come in two parts - the official results data file used to generate the Full Disclosure Report (FDR) on the SPEC website, and the supporting evidence files that verifies the submitted data matches the runtime measurements.
- Create a zipfile containing the result_submission.txt file (under perf directory) and the cloud architecture diagram in PNG format.
- Email that zipfile to subcloudiaas2018@spec.org.
- An email confirmation will be sent back to you, along with the assigned results identifier (i.e. cloudiaas2018-20180107-00016)
- To upload supporting documents, create a package (.tgz, .zip, whichever format you have standardized on) with the documents, and name it using your assigned result identifier, i.e. cloudiaas2018-20180107-00016.tgz.
- Instructions on how to upload the supporting evidence archive file will be emailed to you using the contact information. Members of SPEC will follow different instructions than non-members. See the Run Rule’s section 4.0 Submission Requirements for more information.
Appendix A: Troubleshooting FAQ
CBTOOL fails to start.
- Check if the hostname and IP address of CBTOOL Orchestrator node have been added in the /etc/hosts. CBTOOL needs to be able to resolve its own IP address into a name (any name will do). An error message indicating name resolution failure will be printed out
- Check if the default ports used by CBTOOL - 7070 for the API, 8080 for the GUI and 5114 for logging - are not already taken. An error message indicating that was impossible to bind to the any of these ports will be printed out
CBTOOL fails to communicate with its own API.
- By default the attribute MANAGER_IP, on the CBTOOL’s cloud configuration file (~/osgcloud/cbtool/configs/LINUXUSERNAME_cloud_definitions.txt) is set to $IP_AUTO. When it finds this special value, CBTOOL attempts to auto-discover the IP address on the Orchestrator. However, if your CBTOOL Orchestrator node has more than one network interface card (or even multiple IPs on a single interface), CBTOOL is unable to automatically decide on which one should be used
In that case, set an actual IP address (selected by the tester among the many found on the Orchestrator node) on the cloud configuration file
$ vi
~/osgcloud/cbtool/configs/ubuntu_cloud_definitions.txt
MANAGER_IP = IPADDRESS_OF_INTERFACE_FOR_ORCHESTRATOR_NODE
- The snippet above assumes that CBTOOL is running as the ubuntu Linux user. If Linux user has a different name, the configuration file will have a different starting name (s/ubuntu/LINUXUSERNAME)
- If cloud under test is an OpenStack cloud, the tester must set the host name of cloud controller (nova API) in the /etc/hosts file of the cbharness machine.
Attempting to attach a single VM/Container instance through CBTOOL’s CLI - for testing purposes - results in an error message. How can I debug?
- Restart CBTOOL in debug mode:
$ ~/osgcloud/cbtool/cb --soft_reset -v 10
- Instruct CBTOOL to deploy the single VMs (or Containers) without attempting to establishing contact to these, by running the following command on the CLI
cb> vmdev
- After that, start the failed workload(s)
cb> vmattach cassandra
# or
cb> vmattach hadoopmaster
- CBTOOL will output each command that would have been executed against the VM/Containers. At this point, you can just execute the commands yourself and check for error messages.
- NOTE: When running the script cb_post_boot.sh directly on the VM/Container, it should complete successfully and promptly (e.g., within 90 seconds). If the script hangs, the VM/Container is probably having trouble reaching either the Orchestrator node (specifically on TCP ports 6379,27107 and UDP port 5114) or the NTP server.
- Once done, do not forget to disable the debug mode by issuing the command CLI
cb> vmundev
- NOTE: There is a small utility, called “cbssh”, that could be used to directly connect to the VMs. To try it, just run the following on a bash prompt and you should be able to login on the node.
cd ~/cbtool
~/cbtool/cbssh vm_1
Attempt to attach a single Application Instance (AI) through CBTOOL’s CLI - for testing purposes - results in an error message. How can I debug?
$ ~/osgcloud/cbtool/cb --soft_reset -v 10
cb> appdev
cb> aiattach cassandra_ycsb
cb> aiattach
hadoop
cb> appundev
Baseline Application Instances are deployed successfully, but fail to produce any application metric samples.
|
Purpose |
Command/Results |
|
Restart CBTOOL in debug mode |
$ ~/osgcloud/cbtool/cb –soft_reset -v 10 |
|
Have CBTOOL fully deploy the Virtual Application instance, but do not start the actual load generation by running the following command on the CLI |
cb> appnoload |
|
Attach to the desired AI - using one or both |
cb> aiattach cassandra_ycsb cb> aiattach hadoop |
|
At the very end, CBTOOL will output a message such as “Load Manager will NOT be automatically started on VM NAME during the deployment of VAPP NAME…”. |
|
|
Obtain the list of VMs |
cb> vmlist |
|
Log into ycsb or hadoopmaster AI’s using CBTOOL’s helper utility, and try running the load generation script directly. |
$ cd ~/cbtool; $ ~/osgcloud/cbtool/cbssh vm_4 $ ~/cbtool/cb_ycsb.sh workloadd 1 1 1 $ ~/cbtool/cb_hadoop_job.sh kmeans 1 1 1 |
|
If the load generation script(s) runs successfully, then try starting the Load Manager daemon in debug mode. |
$ /usr/local/bin/cbloadman |
|
Watch for errors in the Load Manager process, displayed directly on the terminal. |
|
|
Once done, disable the debug mode in the CBTOOL CLI |
cb> appload |
Baseline phase hangs. What is happening?
There are couple of reasons why Baseline phase might hang:
- NTP server is not running, or NTP server is misconfigured in osgcloud_rules.yaml
- The configured image is unable to run CBTOOL post-boot scripts (check previous question on this faq)
- CBTOOL is unable to reach instances because instances do not have direct network connectivity with the CBTOOL machine. In this case, setup a jump box, and configure CBTOOL to use jump box.
How can I check if CBTOOL scripts are failing?
CBTOOL logs are stored in /var/log/cloudbench . Search for errors as follows:
$ cd /var/log/cloudbench/
$ tail -f /var/logs/cloudbench/LINUXUSERNAME_remotescripts.log
Search for the AI or the instance name for which there are errors.
Supporting evidence collection is not working for baseline.
Please make sure that the following parameters are set correctly:
instance_user: cbuser
instance_keypath: HOMEDIR/osgcloud/cbtool/credentials/id_rsa
Also make sure that the permissions of the private key are set to private, read-only:
$ chmod 400 id_rsa
When using CBTOOL with the OpenStack Cloud Adapter, can I instruct it to create each new Application Instance on its own tenant/network/subnet/router?
CBTOOL has the ability to execute generic scripts at specific points during the VM/Container attachment (e.g., before the provision request is issued to the cloud, after the VM is reported as “started” by the cloud). A small example script which creates a new keystone tenant, a new pubkey pair, a new security group and a neutron network, subnet and router was made available under the “scenarios/util” directory.
To use it with Application Instances (i.e., ALL VMs/Containers belonging to an AI on its own tenant/network/subnet/router) issue the following command on the CLI
cb> cldalter ai_defaults
execute_script_name=/home/cbuser/cloudbench/scenarios/scripts/openstack_multitenant.sh
After this each new AI that is attached will execute the aforementioned script. You can test it out with the following command
cb> aiattach nullworkload default default none none execute_provision_originated
Please note that the commands listed on the script will be executed from the Orchestrator node, and thus require the existence of all relevant OpenStack CLI clients (e.g., openstack, nova and neutron) present there.
What is the difference between maximum_ais and reported_ais in the benchmark’s configuration file osgcloud_rules.yaml ?
This benchmark is designed to stress your cloud’s control plane as much as the data plane. When applications are being submitted to your cloud, during a compliant run, they are required to arrive at the cloud during a random interval between 5 and 10 minutes. If your cloud’s AI empirical provisioning time (including all the VMs participating with that AI / application) is less than or equal to the average arrival times from that interval, then the benchmark will likely always be able to collect data in a timely manner from the vast majority of the AIs sent to your cloud.
Basically, VMs won’t get backed up and will get services as fast as the benchmark is throwing them at your cloud. This is (currently) hard to achieve — every VM would likely need to be provisioned well under a minute, and be provisioned in parallel for this to happen – and given that, on average, the two types of AIs that SPEC Cloud uses contain as many as 7 virtual machines in each type of AI.
On the other hand, if your cloud’s AI provisioning time (and all participating VMs) are slower than that interval, you will always have an ever-increasing backlog of virtual machines waiting to complete their deployment against your cloud. In this situation, the benchmark will still have a compliant run, but will terminate early without collecting application performance results from all of the AIs.
This behavior is normal, expected and compliant. So, don’t be surprised in the later scenario that the computed score doesn’t match the AI limit you set out to achieve. As long is the score is stable and doesn’t fluctuate much (within 10%), the benchmark is doing what it is supposed to be doing.
In either of the aforementioned scenarios, the variables maximum_ais and reported_ais are designed to create consistency in the results computed by SPEC Cloud. Thus, when choosing to prepare a SPEC Cloud submission report, you have a choice between:
Scenario a) Your cloud’s AI provisioning time is faster than the arrival rate (less than or equal to the 5/10 minute interval) ===> The benchmark will likely terminate by reaching reported_ais first.
Scenario b) Your cloud’s AI provisioning time is slower than the arrival rate (greater than the 5/10 minute interval) ===> The benchmark will terminate by reaching maximum_ais first.
In scenario a, you will likely want to set reported_ais to a lower number than maximum_ais, so that SPEC Cloud only calculates a final score based on a consistent number of AIs created by the benchmark. SPEC Cloud does not (and does not pretend to) calculate this number for you —- only the submitter can really choose this number from empirical experience.
In scenario b, you will likely want to set reported_ais equal to maximum_ais so that as many AIs as possible count towards the final score calculated by SPEC Cloud. Public clouds with limits on their API request rates or that throttle the number of simultaneous VMs that can complete at the same time due to DDoS mitigation or load balancing techniques will likely fall into this category.
What does daemon_parallelism and attach_parallelism in osgcloud_rules.yaml mean?
Some clouds, in particular public clouds, enforce artificial limits on to protect abuse or denial of service. In such situations, users need the ability to control how fast the benchmark hits the cloud’s API.
- daemon_parallelism: This controls the maximum simultaneous outstanding number of AIs that are actively being provisioned at the same time (not the number that have been issued.) For a compliant run, the benchmark deploys AIs between 5 and 10 minutes, but if the cloud has customer limits and cannot absorb this load, setting this value can help.
- attach_parallelism: This controls the maximum simultaneous outstanding number of VMs in a single AI that are actively being provisioned (not the number that the AI is ‘expecting’ to provision). This value can be changed if the cloud needs to be further protected due to abuse or denial of service limits imposed by the cloud, which otherwise cannot be changed for any user.
Lowering the limits set for these parameters may cause CBTOOL to hold issuing request for new application instances if the number of in flight application instances equals the parameter set in daemon_parallelism. If this happens, the interarrival time between application instances may exceed the limit prescribed by the benchmark, that is, 600s. Such a result is considered non-compliant.
Verify rules indicate an ‘ERROR’ in rules. Shall I proceed with the experiment?
If a run is started with the existing values in osgcloud_rules.yaml, you may see an error like this:
2018-08-16 15:53:46,270 INFO
process ERROR:
results->support_evidence->instance_support_evidence is
False. Result will be non-compliant.
2018-08-16 15:53:46,270 INFO process ERROR:
results->support_evidence->cloud_config_support_evidence
is False. Result will be non-compliant.
In SPEC Cloud kit, supporting evidence collection for instances and cloud is set to FALSE. It must be TRUE for a compliant run.
If the run is for internal results, there is no need to update the value for these parameters.
I am running baseline phase for testing and do not want the instances created during baseline phase to be destroyed.
A compliant run requires that instances created during every iteration of baseline are deleted immediately after the iteration. This is already implemented in the benchmark all_run script.
For testing, to disable instance deletion after each iteration of baseline phase, set the following flag in osgcloud_rules.yaml:
baseline:
destroy_ai_upon_completion: false
How do I check the detailed timeline for deployment of a given Application Instance (AI)?
A very detailed timeline for the deployment of each AI can be found on ~/results/EXPID/perf/EXPIDELASTICITY/<USERNAME>_operations.log
The following is an example for a 2-VM Application Instance (using the “iperf” workload, not part of SPECCloud) follows:
$ grep ai_1
/var/log/cloudbench/cbuser_operations.log
Aug 16 14:16:03 cborch.public [2018-08-16 14:16:03,865]
[DEBUG]
active_operations.py/ActiveObjectOperations.pre_attach_ai
TEST_cbuser - Starting the attachment of ai_1
(66E19008-7FEF-5BF4-94E8-9F366918E0A9)...
Aug 16 14:16:04 cborch.public [2018-08-16 14:16:04,302]
[DEBUG]
active_operations.py/ActiveObjectOperations.pre_attach_vm
TEST_cbuser - Starting the attachment of vm_1 (VMID-1), part
of ai_1 (66E19008-7FEF-5BF4-94E8-9F366918E0A9)...
Aug 16 14:16:04 cborch.public [2018-08-16 14:16:04,312]
[DEBUG]
base_operations.py/ActiveObjectOperations.admission_control
TEST_cbuser - Reservation for vm_1 (VMID-1), part of ai_1
(66E19008-7FEF-5BF4-94E8-9F366918E0A9) was successfully
obtained..
…
[MANY. MANY MESSAGES DETAILING START, PROBE, FILE COPYING, REMOTE COMMANDS, ATTACHING TO WORKLOAD SERVICE]
...
Aug 16 14:16:24 cborch.public [2018-08-16 14:16:24,045]
[DEBUG]
base_operations.py/ActiveObjectOperations.parallel_vm_config_for_ai
TEST_cbuser - Parallel VM configuration for ai_1
(66E19008-7FEF-5BF4-94E8-9F366918E0A9) success.
Aug 16 14:16:24 cborch.public [2018-08-16 14:16:24,132]
[DEBUG] active_operations.py/ActiveObjectOperations.objattach
TEST_cbuser - AI object 66E19008-7FEF-5BF4-94E8-9F366918E0A9 (named "ai_1") sucessfully attached to this
experiment. It is ssh-accessible at the IP address 10.0.0.3
(cb-cbuser-TESTPDM-vm1-iperfclient-ai-1).
The provisioning SLA for a given Application Instance was violated (run code = 5). How do I check which component in the creation of application instance took the most time?
The total provisioning time has 7 components, being the first an epoch timestamp and the subsequent 6 deltas (in seconds):
mgt_001_provisioning_request_originated_abs
mgt_002_provisioning_request_sent
mgt_003_provisioning_request_completed
mgt_004_network_acessible
mgt_005_file_transfer
mgt_006_instance_preparation
mgt_007_application_start
These values are all stored on the file “VM_management_*.csv”, present on the directory ~/results/<EXPID>/perf/<EXPID><AI TYPE>[BASELINE, ELASTICITY]<TIMESTAMP>.
Additionally, the detailed timeline described on the previous question also outputs the specific reason for a provisioning qos violation on a given Application Instance.
Which OpenStack releases are supported by SPEC Cloud IaaS 2018?
CBTOOL uses OpenStack APIs. If there are no changes in OpenStack APIs, new releases should continue to be supported. SPEC Cloud has been tested up to Ocata release of OpenStack, but that should by no means be a limiting factor. If you have a compatibility issue, please notify us and we’ll get it fixed.
Appendix B: Cloudbench Commands
To see a list of available instance roles, use the command “rolelist” on the CLI. To see a list of AI types use the command “typelist”. To see a description of a particular AI, use the command “typeshow (vapp type)”.
Each AI has its own load behavior, with independent load profile, load level and load duration. The values for load level and load duration can be set as random distributions (exponential, uniform, gamma, normal), fixed numbers or monotonically increasing/decreasing sequences. The load level, has a meaning that is specific to each AI type. For instance, for a Cassandra YCSB AI, it represents the number of simultaneous threads on the YCSB load generator, while for Hadoop it represents the size of dataset to be sorted.
During an experiment, relevant metrics are automatically collected such as provisioning latency and throughput, and application runtime performance. Instance CPU, disk, memory, and network performance data can also be collected, although such collection is disabled for a compliant run.
Lastly, the experiment is terminated after the conditions specified in the experiment plan are met (e.g., a certain amount of time has passed, or a number of parameter variations have happened). CBTOOL’s workflow through its main components is represented in the following diagram.
AI can be deployed explicitly by the experimenter (using either the CLI or GUI) or implicitly through one (or more) AI Submitter(s). An AI Submitter deploys Application Instances with a given pattern, represented by a certain inter-arrival time and a lifetime (also fixed, distributions or sequences).
To see a list of available patterns, use the command “patternlist” on the CLI. To see a description of a particular pattern, use the command “patternshow (vapp submitter pattern)”.
The tool was written in Python (about 35K lines of code), and has only open-source dependencies. The main ones are Redis, MongoDB and Ganglia.
CBTOOL has a layered architecture, designed to be extendable and reusable. All interactions with external elements (cloud environments and applications) are performed through plug-in components. The ability to interact with different cloud environments is added through new cloud adapters. While the ability to automatically deploy and collect performance specific data from new applications (i.e., AI types) is added through workload automation scripts. These plug-in components are self-contained, and requiring no changes in the source code. This characteristic enables cloud environment and application experts to expand CBTOOL’s scope directly and incrementally.
Appendix C: Building a Custom Cloud Manager Adapter
Add a New Cloud Adapter (native method)
CBTOOL’s layered architecture allows the framework to be incrementally expanded in a non-intrusive (i.e., minimal to no changes to the existing “core” code) and incremental manner.
While multiple Cloud Adapters are available, new adapters are constantly added. These adapters are divided in two broad classes, following the Cloud’s classification, Whitebox and Blackbox (i.e., public). When adding a new cloud adapter, consider using either the OpenStack or EC2 Cloud Adapters as respective white-box or black-box examples.
Assuming that a “New Public Cloud” (npc) an adapter needs to be written and using EC2 as a template, here is a summary of the required steps.
Create the New Adapter
|
Action |
Linux command/output |
|
Use existing EC2 template to create one for NPC |
$ cd ~/osgcloud/cbtool/configs/templates/ $ cp _ec2.txt _npc.txt |
|
Use existing EC2 adapter to create one for NPC |
$ cd ~/cbtool/lib/clouds/ $ cp ec2_cloud_ops.py npc_cloud_ops.py |
|
Edit NPC adapter |
$ vi npc_cloud_ops.py |
|
Change lines 37-38 to import NPC’s native python client |
|
|
Change line 40 to rename class name Ec2Cmds to NpcCmds and save the changes. |
:40s/Ec2Cmds/NpcCmds/ :wq |
Mapping Native to CBTOOL’s Abstract Operations
CBTOOL’s abstract operations are mapped to five mandatory methods in the (newly created by the implementer) class NpcCmds:
- vmccleanup
- vmcregister
- vmcunregister
- vmcreate
- vmdestory
In addition to mapping the required methods, the following methods are also part of each Cloud adapter:
- test_vmc_connection
- is_vm_running
- is_vm_ready
From a cloud native python client standpoint, determine how to:
- connect to the cloud
- list images
- list SSH keys
- list security groups (if applicable)
- list networks (if applicable)
- list instances
- get all relevant information about instances (e.g., state, IP addresses)
In addition to the “mandatory” methods (see the above table of existing Cloud Adapters), consider implementing “optional” operations, such as “vmcapture” and “vmrunstate” (both additional methods in the same class).
- Modifying the methods “vvcreate” and “vvdestroy” adds the ability to attach and detach persistent storage (i.e., “virtual volumes”).
These optional methods requires the cloud native python client to understand how to:
- create an “image” from an “instance”
- alter the instance power state (e.g., suspend, resume, power on/off) and list
- get information and attach/detach volumes from instances
Adjust Adapter Parameters
Change the parameters in _npc.txt, taking into account specific features on this cloud.
Finally. Remember that the parameters in _npc.txt need to be changed to account for specific features on this cloud.
Test the New Adapter
In CBTOOL’s CLI, test the new adapter by starting with a simple
- cb> cldattach npc TESTNPCCLOUD
- cb> vmcattach all
These 2 operations ensure that vmccleanup and vmcregister methods are properly implemented.
At this point, the implementer should prepare an image on the New Public Cloud with the new NPC adapter installed. After that, the implementer can continue by issuing vmattach and vmdetach directives on the CLI.
Add a libcloud Cloud Adapter (simplified method)
CBTOOL provides a simplified method of getting up and running with your favorite cloud via Apache libcloud. The distributed kit contains an easy-to-use class hierarchy written in python. A little bit of new code can easily bring a new cloud into the benchmark by following the libcloud-support interface definitions. The number of libcloud-supported clouds is vast. A complete list can be found at
https://libcloud.readthedocs.io/en/latest/supported_providers.html
The SPECIaas benchmark uses simplified libcloud-based methods in support of the following libcloud-based functions: 1. create/destroy VMs 2. multi-tenancy (using multiple accounts at the same time) 3. create/destroy block storage volumes 4. multi-region support 5. cloud-init support for both SSH-keys and OpenVPN.
The benchmark CAN NOT do these simplified libcloud-support features: 1. floating IP addresses 2. image snapshot management 3. block storage snapshot management 4. other esoteric functions provided by individual libcloud-based cloud providers.
For example, if you have a non-standard “special” feature supported by your cloud manager - docker-based cloud manager commands, or automatically configured secret features of your cloud, then you cannot use the simplified libcloud-approach. You should use the ‘native’ approach above.
As long as you’re in the first list, you can use this simplified approach.
Create the New Adapter
|
Action |
Linux command/output |
|
Use existing EC2 template to create one for NPC |
$ cd ~/osgcloud/cbtool/configs/templates/ $ cp _digitalocean.txt _npc.txt |
|
Use existing EC2 adapter to create one for NPC |
$ cd ~/cbtool/lib/clouds/ $ cp do_cloud_ops.py npc_cloud_ops.py |
|
Edit NPC adapter |
$ vi npc_cloud_ops.py |
|
Change lines 37-38 to import NPC’s native python client |
|
|
Change line 40 to rename class name Ec2Cmds to NpcCmds and save the changes. |
:40s/Ec2Cmds/NpcCmds/ :wq |
Setting libcloud Features and Parameters
The SPEC Cloud benchmark kit contains a libcloud adapter that allows you to define which features and operations exists in your cloud manager.
Reference file: ~/osgcloud/cbtool/lib/clouds/libcloud_common.py
Read the documentation in the __init__ function at the beginning of this file.
New adapter: ~/osgcloud/cbtool/lib/clouds/npc_cloud_ops.py
Modify the options to the __init__ function to match the features supported by your libcloud-based cloud.
For example, if you don’t need SSH keys via cloud-init, or you don’t support cloud-init at all, then set those respective options to False. Most options are optional. While the DigitalOcean adapter makes more complete use of all the libcloud features, your cloud may not need them all.
In the pre_create_vm method, add any additional overrides to the method which actually launches VMs into your cloud. Many clouds provide special python keyword arguments to the libcloud create_node() function which are special to your individual cloud. If this is true, then add the respective keyword arguments to the pre_create_vm function. The DigitalOcean adapter has such an override in ~/osgcloud/cbtool/lib/clouds/do_cloud_ops.py
When finished, you should have a very short cloud adapter. If you have trouble adding the new adapter, we can help you via the CBTOOL mailing lists. Join the lists and let us know how it goes.
Appendix D: CBTOOL Installation Outputs
First Installation Output
|
$~/osgcloud/cbtool$
./install -r orchestrator |
Successful Installation Output
This is what a successful output looks like:
|
$~/osgcloud/cbtool$ ./install -r orchestrator ubuntu@cbtool-spec:~/osgcloud/cbtool$
sudo ./install -r orchestrator |
Appendix E: OpenStack example
The instructions below describe how to configure CBTOOL running on benchmark harness machine for your OpenStack cloud. These instructions assume that CBTOOL image has been created with Ubuntu Trusty distribution.
This example assumes that
- The Linux username is ubuntu.
- The ubuntu user has successfully installed the CBTOOL software
- The ubuntu_cloud_definitions.txt file exists (as a result of the CBTOOL software install)
- The ubuntu user has successfully generated SSH credentials and propagated the files to the base CBTOOL image
- All network and virtual routers have been configured in the OpenStack cloud.
- The cbharness machine can directly reach all instances using the floating IP addresses automatically assigned when VMs are created.
- An easily set up ‘Flat’ OpenStack cloud network will be used for initial testing, to simplify any network diagnosis.
|
Get the spec_key file from kit into cbtool credentials directory. |
$ cp /home/ubuntu/osgcloud/spec_ssh_keys/* /home/ubuntu/osgcloud/cbtool/credentials/ |
|
Add hostname of OpenStack controller in your /etc/hosts file |
$ sudo vi /etc/hosts |
OpenStack Related Configuration Keys
Edit the /home/ubuntu/osgcloud/cbtool/configs/ubuntu_cloud_definitions.txt file and replace the section under [CLOUDOPTION_MYOPENSTACK] with the following, and set the following keys according to your environment:
|
STARTUP_CLOUD |
Set to MYOPENSTACK |
|
OSK_ACCESS |
The IP address of your OpenStack controller (public endpoint) |
|
OSK_INITIAL_VMCS |
Replace RegionOne with appropriate name for region configured in OpenStack cloud |
|
OSK_NETNAME |
Replace public with the network name to which instances in your cloud will be configured with. Preconfigure the network and virtual routers (if any) in the OpenStack cloud |
|
OSK_KEY_NAME |
The name of the (public) key to be “injected” on an image before it is booted. For example in OpenStack, the key is injected into /root/.ssh/authorized_keys, allowing a root user to login on a VM after the boot. This attribute refers to a directly managed OpenStack cloud key . OSK_SSH_KEY_NAME is also the name of the key used to login on a VM as the user (non-root) specified by OSK_LOGIN. This key will not (necessarily) be injected on the image. The key and username specified by OSK_SSH_KEY_NAME and OSK_LOGIN must be pre-defined on the VM. These attributes are not managed (or known) by the OpenStack cloud. |
|
OSK_ACCESS |
If your cloud supports HTTPS, enter as: OSK_ACCESS = https://PUBLICIP/v2.0/ or the keystone URL |
|
USE_FLOATING_IP |
If your cloud needs floating IP addresses, change the the key to $True. |
|
STARTUP_CLOUD |
Set to either MYSIMCLOUD or MYOPENSTACK once the simulated cloud testing step is completed. |
|
MANAGER_IP |
If your cbtool has more than one interface (ifconfig -a | grep eth), then enter the IP address of appropriate interface. HINT: set the IP address from which you can access the cbtool UI |
Example Openstack Configuration Settings
The Openstack configuration section should resemble the following:
[USER-DEFINED :
CLOUDOPTION_MYOPENSTACK]
OSK_ACCESS = http://PUBLICIP:5000/v2.0/ # Address of node
where nova-api runs
OSK_CREDENTIALS = admin-admin-admin #
user-tenant-password
OSK_SECURITY_GROUPS = default
# This group must exist first
OSK_INITIAL_VMCS = RegionOne
# Change "RegionOne" accordingly
OSK_LOGIN = cbuser
# The username that logins
on the VMs
OSK_KEY_NAME = spec_key #
SSH key for logging into workload VMs
OSK_SSH_KEY_NAME = spec_key # SSH key for
logging into workload VMs
OSK_NETNAME = public
Set image names and types. If the image names listed below does not match the image names in your OpenStack cloud, then update the image names appropriately:
[VM_TEMPLATES :
OSK_CLOUDCONFIG]
CASSANDRA = size:m1.medium,
imageid1:cb_speccloud_cassandra_2120
YCSB = size:m1.medium, imageid1:cb_speccloud_cassandra_2120
SEED = size:m1.medium, imageid1:cb_speccloud_cassandra_2120
HADOOPMASTER = size:m1.medium,
imageid1:cb_speccloud_hadooop_275
HADOOPSLAVE = size:m1.medium, imageid1:cb_speccloud_hadoop_275
For initial testing, please use admin user/tenant. Once familiar with the harness, you can use a different user/tenant with appropriate permissions.
Appendix F: Additional Information
Multiple Network Interfaces on Benchmark Harness Machine
If the benchmark harness machine has more than one network interfaces, configure CBTOOL with the network interface that is used to communicate with the cloud API.
Set the following configuration in the configuration file of cbtool, assuming it was set up on an Ubuntu machine with ubuntu as the Linux user:
$ vi
~/osgcloud/cbtool/configs/ubuntu_cloud_definitions.txt
MANAGER_IP = IPADDRESS_OF_INTERFACE_FOR_CLOUDAPI
Provisioning Scripts Execution Steps
CBTOOL decides which (and how many) instances to create, based on the “Application Instance” (AI) template. For a “Hadoop” AI, there are five hadoopslave instances and one as the hadoopmaster. For a “Cassandra YCSB” AI, there are five seed (all seed nodes) instances and one instance as the ycsb role.
The CBTOOL orchestrator node converts the list of instance creation requests into cloud-specific API calls (or commands), and then issues these to the cloud under test. It waits for the instances to completely boot, and collects all relevant IP addresses.
After the instances boot, and following the AI template, the Orchestrator node ssh’s to each instance, and runs the AI role specific configuration scripts.
Using Cassandra YCSB as an example, it runs (in parallel) scripts to form a Cassandra cluster on all five instances with the seed role, and a different script to configure the instance that generates the YCSB workload.
After the AI is fully deployed (i.e., Cassandra or Hadoop clusters fully formed, and load generating application clients configured) the Orchestrator node starts the process designated Load Manager (LM) in one of the instances of the AI.
The activities described above are depicted in the following picture.

Once the LM starts, the whole Application Instance becomes self-sufficient, i.e., the Orchestrator node no longer needs to connect to any of the instances that comprise the AI for the rest of the experiment. The LM contacts the Object Store (typically on the Orchestrator node) to retrieve all relevant information about the load profile, load duration, load level (intensity), and executes a load generating process through a script also specified on the AI template.
The LM waits until the process ends, then collects all information from either the process’ standard output or an output file. It processes the results and submits a new sample containing application performance results. These results are written in CBTOOL’s Metric Store as a set of time-series with multiple key-value pairs (some applications report multiple metrics such as read and write throughput, read and write latency, etc.). While the layered architecture of CBTOOL can use multiple datastores for this purpose, the current implementation uses MongoDB.
The continuous execution/results collection is depicted in the figure below.

Cloud Configuration Retrieval Scripts via Cloud APIs
A cloud provides APIs to retrieve information instances, images, users, networks, instance storage, apiendpoints, quotas, and hypervisors. This information must be collected as part of instance and cloud configuration during different phases of the benchmark.
The kit ships with a reference set of scripts that have been tested with OpenStack. It is the cloud provider’s responsibility to customize and test these scripts to the extent possible, ensuring that they are executed during a compliant run, and include the source code of the customized scripts with the FDR report.
The reference implementation for OpenStack is located in the following directory:
$ cd ~/osgcloud/driver/support_script/cloud_config/openstack
These scripts are executed when the cloud_config_support_evidence flag is set to true. For testing, these scripts are not needed.
|
Script |
Purpose |
|
getinstances.sh |
List all instances running in the cloud. The following information must be included: instance name, instance id, instance type or details (flavor), image id from which instance is provisioned, network id to which instance is connected to, state of the instance, time at which instance was started, ssh key used, id of the user who launched the instance, tenant id to which a user belongs (if applicable) For black box, add the region/data center name as well as any availability zone information for the instances. |
|
getinstancetypes.sh |
List the types of various instances available for provisioning in the cloud. |
|
getimages.sh |
List the image names and image ids from which instances can be provisioned |
|
getapiendpoint.sh |
List the API endpoints called by CBTOOL to provision instances and other cloud resources. |
|
getusers.sh |
List the users configured for this cloud. |
|
gettenant.sh |
List the tenants configured for this cloud. Blackbox clouds do not necessarily need to have a separate tenant list. |
|
getnetworks.sh |
List the networks (virtual) and routers (virtual) configured for this cloud. The following information must be included: network id, network name, IP address range, router information |
|
getquotas.sh |
List the quota for the user or tenant. The following information must be included. instance quota, storage quota |
|
getblockstorage.sh |
List the block storage devices and the instances they are attached to |
|
gethypervisors.sh |
[WHITEBOX ONLY] list the hypervisors that are used in the cloud. |
© Copyright 2018, SPEC