| talk1-abstract = Community norm violations can impair constructive communication and collaboration online. As a defense mechanism, community moderators often address such transgressions by temporarily blocking the perpetrator. Such actions, however, come with the cost of potentially alienating community members. Given this tradeoff, it is essential to understand to what extent, and in which situations, this common moderation practice is effective in reinforcing community rules. In this work, we introduce a computational framework for studying the future behavior of blocked users on Wikipedia. After their block expires, they can take several distinct paths: they can reform and adhere to the rules, but they can also recidivate, or straight-out abandon the community. We reveal that these trajectories are tied to factors rooted both in the characteristics of the blocked individual and in whether they perceived the block to be fair and justified. Based on these insights, we formulate a series of prediction tasks aiming to determine which of these paths a user is likely to take after being blocked for their first offense, and demonstrate the feasibility of these new tasks. Overall, this work builds towards a more nuanced approach to moderation by highlighting the tradeoffs that are in play.
| talk1-abstract = Community norm violations can impair constructive communication and collaboration online. As a defense mechanism, community moderators often address such transgressions by temporarily blocking the perpetrator. Such actions, however, come with the cost of potentially alienating community members. Given this tradeoff, it is essential to understand to what extent, and in which situations, this common moderation practice is effective in reinforcing community rules. In this work, we introduce a computational framework for studying the future behavior of blocked users on Wikipedia. After their block expires, they can take several distinct paths: they can reform and adhere to the rules, but they can also recidivate, or straight-out abandon the community. We reveal that these trajectories are tied to factors rooted both in the characteristics of the blocked individual and in whether they perceived the block to be fair and justified. Based on these insights, we formulate a series of prediction tasks aiming to determine which of these paths a user is likely to take after being blocked for their first offense, and demonstrate the feasibility of these new tasks. Overall, this work builds towards a more nuanced approach to moderation by highlighting the tradeoffs that are in play.
| talk2-title = Automatic Detection of Online Abuse in Wikipedia
| talk2-title = [[:meta:Automatic Detection of Online Abuse in Wikipedia]] <-- see project page
| talk2-presenter = Lane Rasberry, University of Virginia
| talk2-presenter = Lane Rasberry, University of Virginia
| talk2-slides = File:Automatic Detection of Online Abuse in Wikipedia.pdf
| talk2-slides = File:Automatic Detection of Online Abuse in Wikipedia.pdf
Revision as of 21:00, 20 June 2019
The Monthly Wikimedia Research Showcase is a public showcase of recent research by the Wikimedia Foundation's Research Team and guest presenters from the academic community. The showcase is hosted at the Wikimedia Foundation every 3rd Wednesday of the month at 11.30 Pacific Time and is live-streamed on YouTube. The schedule may change, see the calendar below for a list of confirmed showcases.
How to attend
We live stream our research showcase every month on YouTube. The link will be in each showcase's details below and is also announced in advance via wiki-research-l, analytics-l and @WikiResearch. You can join the conversation and participate in Q&A after each presentation by connecting to our IRC channel on freenode: #wikimedia-researchconnect
Upcoming Events
June 2019
June 26, 2019 Video: [to come YouTube]
Trajectories of Blocked Community Members
Redemption, Recidivism and Departure
By Jonathan Chang, Cornell University
Community norm violations can impair constructive communication and collaboration online. As a defense mechanism, community moderators often address such transgressions by temporarily blocking the perpetrator. Such actions, however, come with the cost of potentially alienating community members. Given this tradeoff, it is essential to understand to what extent, and in which situations, this common moderation practice is effective in reinforcing community rules. In this work, we introduce a computational framework for studying the future behavior of blocked users on Wikipedia. After their block expires, they can take several distinct paths: they can reform and adhere to the rules, but they can also recidivate, or straight-out abandon the community. We reveal that these trajectories are tied to factors rooted both in the characteristics of the blocked individual and in whether they perceived the block to be fair and justified. Based on these insights, we formulate a series of prediction tasks aiming to determine which of these paths a user is likely to take after being blocked for their first offense, and demonstrate the feasibility of these new tasks. Overall, this work builds towards a more nuanced approach to moderation by highlighting the tradeoffs that are in play.
Researchers analyzed all English Wikipedia blocks prior to 2018 using machine learning. With insights gained, the researchers examined all English Wikipedia users who are not blocked against the identified characteristics of blocked users. The results were a ranked set of predictions of users who are not blocked, but who have a history of conduct similar to that of blocked users. This research and process models a system for the use of computing to aid human moderators in identifying conduct on English Wikipedia which merits a block.
First Insights from Partial Blocks in Wikimedia Wikis
By Morten Warncke-Wang, Wikimedia Foundation
The Anti-Harassment Tools team at the Wikimedia Foundation released the partial block feature in early 2019. Where previously blocks on Wikimedia wikis were sitewide (users were blocked from editing an entire wiki), partial blocks makes it possible to block users from editing specific pages and/or namespaces. The Italian Wikipedia was the first wiki to start using this feature, and it has since been rolled out to other wikis as well. In this presentation, we will look at how this feature has been used in the first few months since release.
Group Membership and Contributions to Public Information Goods
The Case of WikiProject
By Ark Fangzhou Zhang
We investigate the effects of group identity on contribution behavior on the English Wikipedia, the largest online encyclopedia that gives free access to the public. Using an instrumental variable approach that exploits the variations in one’s exposure to WikiProject, we find that joining a WikiProject has a significant impact on one’s level of contribution, with an average increase of 79 revisions or 8,672 character per month. To uncover the potential mechanism underlying the treatment effect, we use the size of home page for WikiProject as a proxy for the number of recommendations from a project. The results show that the users who join a WikiProject with more recommendations significantly increase their contribution to articles under the joined project, but not to articles under other projects.
Thanks for Stopping By
A Study of “Thanks” Usage on Wikimedia
By Swati Goel
The Thanks feature on Wikipedia, also known as "Thanks," is a tool with which editors can quickly and easily send one other positive feedback. The aim of this project is to better understand this feature: its scope, the characteristics of a typical "Thanks" interaction, and the effects of receiving a thank on individual editors. We study the motivational impacts of "Thanks" because maintaining editor engagement is a central problem for crowdsourced repositories of knowledge such as Wikimedia. Our main findings are that most editors have not been exposed to the Thanks feature (meaning they have never given nor received a thank), thanks are typically sent upwards (from less experienced to more experienced editors), and receiving a thank is correlated with having high levels of editor engagement. Though the prevalence of "Thanks" usage varies by editor experience, the impact of receiving a thank seems mostly consistent for all users. We empirically demonstrate that receiving a thank has a strong positive effect on short-term editor activity across the board and provide preliminary evidence that thanks could compound to have long-term effects as well. More information is available on the research project page.
The curation of Wikidata (and other knowledge bases) is crucial to keep the data consistent, to fight vandalism and to correct good faith mistakes. However, manual curation of the data is costly. In this work, we propose to take advantage of the edit history of the knowledge base in order to learn how to correct constraint violations automatically. Our method is based on rule mining, and uses the edits that solved violations in the past to infer how to solve similar violations in the present. For example, our system is able to learn that the value of the sex or gender property woman should be replaced by female. We provide a Wikidata game that suggests our corrections to the users in order to improve Wikidata. Both the evaluation of our method on past corrections, and the Wikidata game statistics show significant improvements over baselines.
TableNet
An Approach for Determining Fine-grained Relations for Wikipedia Tables
slides
By Besnik Fetahu
Wikipedia tables represent an important resource, where information is organized w.r.t table schemas consisting of columns. In turn each column, may contain instance values that point to other Wikipedia articles or primitive values (e.g. numbers, strings etc.). In this work, we focus on the problem of interlinking Wikipedia tables for two types of table relations: equivalent and subPartOf. Through such relations, we can further harness semantically related information by accessing related tables or facts therein. Determining the relation type of a table pair is not trivial, as it is dependent on the schemas, the values therein, and the semantic overlap of the cell values in the corresponding tables. We propose TableNet, an approach that constructs a knowledge graph of interlinked tables with subPartOf and equivalent relations. TableNet consists of two main steps: (i) for any source table we provide an efficient algorithm to find all candidate related tables with high coverage, and (ii) a neural based approach, which takes into account the table schemas, and the corresponding table data, we determine with high accuracy the table relation for a table pair. We perform an extensive experimental evaluation on the entire Wikipedia with more than 3.2 million tables. We show that with more than 88% we retain relevant candidate tables pairs for alignment. Consequentially, with an accuracy of 90% we are able to align tables with subPartOf or equivalent relations. Comparisons with existing competitors show that TableNet has superior performance in terms of coverage and alignment accuracy.
Diversity of Visual Encyclopedic Knowledge Across Wikipedia Language Editions
By Shiqing He (presenting, University of Michigan), Brent Hecht (presenting, Northwestern University), Allen Yilun Lin (Northwestern University), Eytan Adar (University of Michigan), ICWSM'18.
Across all Wikipedia language editions, millions of images augment text in critical ways. This visual encyclopedic knowledge is an important form of wikiwork for editors, a critical part of reader experience, an emerging resource for machine learning, and a lens into cultural differences. However, Wikipedia research--and cross-language edition Wikipedia research in particular--has thus far been limited to text. In this paper, we assess the diversity of visual encyclopedic knowledge across 25 language editions and compare our findings to those reported for textual content. Unlike text, translation in images is largely unnecessary. Additionally, the Wikimedia Foundation, through the Wikipedia Commons, has taken steps to simplify cross-language image sharing. While we may expect that these factors would reduce image diversity, we find that cross-language image diversity rivals, and often exceeds, that found in text. We find that diversity varies between language pairs and content types, but that many images are unique to different language editions. Our findings have implications for readers (in what imagery they see), for editors (in deciding what images to use), for researchers (who study cultural variations), and for machine learning developers (who use Wikipedia for training models).
A Warm Welcome, Not a Cold Start
Eliciting New Editors' Interests via Questionnaires
By Ramtin Yazdanian (presenting, Ecole Polytechnique Federale de Lausanne)
Every day, thousands of users sign up as new Wikipedia contributors. Once joined, these users have to decide which articles to contribute to, which users to reach out to and learn from or collaborate with, etc. Any such task is a hard and potentially frustrating one given the sheer size of Wikipedia. Supporting newcomers in their first steps by recommending articles they would enjoy editing or editors they would enjoy collaborating with is thus a promising route toward converting them into long-term contributors. Standard recommender systems, however, rely on users' histories of previous interactions with the platform. As such, these systems cannot make high-quality recommendations to newcomers without any previous interactions -- the so-called cold-start problem. Our aim is to address the cold-start problem on Wikipedia by developing a method for automatically building short questionnaires that, when completed by a newly registered Wikipedia user, can be used for a variety of purposes, including article recommendations that can help new editors get started. Our questionnaires are constructed based on the text of Wikipedia articles as well as the history of contributions by the already onboarded Wikipedia editors. We have assessed the quality of our questionnaire-based recommendations in an offline evaluation using historical data, as well as an online evaluation with hundreds of real Wikipedia newcomers, concluding that our method provides cohesive, human-readable questions that perform well against several baselines. By addressing the cold-start problem, this work can help with the sustainable growth and maintenance of Wikipedia's diverse editor community. Slides
Studies on the relationship between new editors’ motivations and activity
By Martina Balestra, New York University
Peer production communities like Wikipedia often struggle to retain contributors beyond their initial engagement. Theory suggests this may be related to their levels of motivation, though prior studies either center on contributors’ activity or use cross-sectional survey methods, and overlook accompanied changes in motivation. In this talk, I will present a series of studies aimed at filling this gap. We begin by looking at how Wikipedia editors’ early motivations influence the activities that they come to engage in, and how these motivations change over the first three months of participation in Wikipedia. We then look at the relationship between editing activity and intrinsic motivation specifically over time. We find that new editors’ early motivations are predictive of their future activity, but that these motivations tend to change with time. Moreover, newcomers’ intrinsic motivation is reinforced by the amount of activity they engage in over time: editors who had a high level of intrinsic motivation entered a virtuous cycle where the more they edited the more motivated they became, whereas those who initially had low intrinsic motivation entered a vicious cycle. Our findings shed new light on the importance of early experiences and reveal that the relationship between motivation and activity is more complex than previously understood.
Geography and knowledge. Reviving an old relationship with Wiki Atlas
By Anastasios Noulas, New York University
Wiki Atlas is an interactive cartography tool. The tool renders Wikipedia content in a 3-dimensional, web-based cartographic environment. The map acts as a medium that enables the discovery and exploration of articles in a manner that explicitly associates geography and information. At its current prototype form, a Wikipedia article is represented on the map as a 3D element whose height property is proportional to the number of views the article has on the website. This property enables the discovery of relevant content, in a manner that reflects the significance of the target element by means of collective attention by the site’s audience.
By Florian Lemmerich, RWTH Aachen University; Diego Sáez-Trumper, Wikimedia Foundation; Robert West, EPFL; and Leila Zia, Wikimedia Foundation
So far, little is known about why users across the world read Wikipedia's various language editions. To bridge this gap, we conducted a comparative study by combining a large-scale survey of Wikipedia readers across 14 language editions with a log-based analysis of user activity. For analysis, we proceeded in three steps: First, we analyzed the survey results to compare the prevalence of Wikipedia use cases across languages, discovering commonalities, but also substantial differences, among Wikipedia languages with respect to their usage. Second, we matched survey responses to the respondents' traces in Wikipedia's server logs to characterize behavioral patterns associated with specific use cases, finding that distinctive patterns consistently mark certain use cases across language editions. Third, we could show that certain Wikipedia use cases are more common in countries with certain socio-economic characteristics; e.g., in-depth reading of Wikipedia articles is substantially more common in countries with a low Human Development Index. The outcomes of this study provide a deeper understanding of Wikipedia readership in a wide range of languages, which is important for Wikipedia editors, developers, and the reusers of Wikipedia content.
November 2018
There was no showcase in November due to US holidays.
"Welcome" Changes? Descriptive and Injunctive Norms in a Wikipedia Sub-Community
By Jonathan T. Morgan, Wikimedia Foundation and Anna Filippova, GitHub
Open online communities rely on social norms for behavior regulation, group cohesion, and sustainability. Research on the role of social norms online has mainly focused on one source of influence at a time, making it difficult to separate different normative influences and understand their interactions. In this study, we use the Focus Theory to examine interactions between several sources of normative influence in a Wikipedia sub-community: local descriptive norms, local injunctive norms, and norms imported from similar sub- communities. We find that exposure to injunctive norms has a stronger effect than descriptive norms, that the likelihood of performing a behavior is higher when both injunctive and descriptive norms are congruent, and that conflicting social norms may negatively impact pro-normative behavior. We contextualize these findings through member interviews, and discuss their implications for both future research on normative influence in online groups and the design of systems that support open collaboration.(research paper, slides with notes)
The pipeline of online participation inequalities - The case of Wikipedia Editing
By Aaron Shaw, Northwestern University and Eszter Hargittai, University of Zurich
Participatory platforms like the Wikimedia projects have unique potential to facilitate more equitable knowledge production. However, digital inequalities such as the Wikipedia gender gap undermine this democratizing potential. In this talk, I present new research in which Eszter Hargittai and I conceptualize a "pipeline" of online participation and model distinct levels of awareness and behaviors necessary to become a contributor to the participatory web. We test the theory in the case of Wikipedia editing, using new survey data from a diverse, national sample of adult internet users in the U.S.
The results show that Wikipedia participation consistently reflects inequalities of education and internet experiences and skills. We find that the gender gap only emerges later in the pipeline whereas gaps along racial and socioeconomic lines explain variations earlier in the pipeline. Our findings underscore the multidimensionality of digital inequalities and suggest new pathways toward closing knowledge gaps by highlighting the importance of education and Internet skills.
We conclude that future research and interventions to overcome digital participation gaps should not focus exclusively on gender or class differences in content creation, but expand to address multiple aspects of digital inequality across pipelines of participation. In particular, when it comes to overcoming gender gaps in the case of Wikipedia, our results suggest that continued emphasis on recruiting female editors should include efforts to disseminate the knowledge that Wikipedia can be edited. Our findings support broader efforts to overcome knowledge- and skill-based barriers to entry among potential contributors to the open web.
The impact of news exposure on collective attention in the United States during the 2016 Zika epidemic
By Michele Tizzoni, André Panisson, Daniela Paolotti, Ciro Cattuto
In recent years, many studies have drawn attention to the important role of collective awareness and human behaviour during epidemic outbreaks. A number of modelling efforts have investigated the interaction between the disease transmission dynamics and human behaviour change mediated by news coverage and by information spreading in the population. Yet, given the scarcity of data on public awareness during an epidemic, few studies have relied on empirical data. Here, we use fine-grained, geo-referenced data from three online sources - Wikipedia, the GDELT Project and the Internet Archive - to quantify population-scale information seeking about the 2016 Zika virus epidemic in the U.S., explicitly linking such behavioural signal to epidemiological data. Geo-localized Wikipedia pageview data reveal that visiting patterns of Zika-related pages in Wikipedia were highly synchronized across the United States and largely explained by exposure to national television broadcast. Contrary to the assumption of some theoretical models, news volume and Wikipedia visiting patterns were not significantly correlated with the magnitude or the extent of the epidemic. Attention to Zika, in terms of Zika-related Wikipedia pageviews, was high at the beginning of the outbreak, when public health agencies raised an international alert and triggered media coverage, but subsequently exhibited an activity profile that suggests nonlinear dependencies and memory effects in the relationship between information seeking, media pressure, and disease dynamics. This calls for a new and more general modelling framework to describe the interaction between media exposure, public awareness, and disease dynamics during epidemic outbreaks.
Deliberation and resolution on Wikipedia: A case study of requests for comments
By Jane Im (University of Michigan) and Amy X. Zhang (MIT)
Resolving disputes in a timely manner is crucial for any online production group. We present an analysis of Requests for Comments (RfCs), one of the main vehicles on Wikipedia for formally resolving a policy or content dispute. We collected an exhaustive dataset of 7,316 RfCs on English Wikipedia over the course of 7 years and conducted a qualitative and quantitative analysis into what issues affect the RfC process. Our analysis was informed by 10 interviews with frequent RfC closers. We found that a major issue affecting the RfC process is the prevalence of RfCs that could have benefited from formal closure but that linger indefinitely without one, with factors including participants' interest and expertise impacting the likelihood of resolution. From these findings, we developed a model that predicts whether an RfC will go stale with 75.3% accuracy, a level that is approached as early as one week after dispute initiation. (RfC Dataset, CSCW paper)
The automatic generation and updating of Wikipedia articles is usually approached as a multi-document summarization task: Given a set of source documents containing information about an entity, summarize the entity. Purely sequence-to-sequence neural models can pull that off, but getting enough data to train them is a challenge. Wikipedia articles and their reference documents can be used for training, as was recently done by a team at Google AI. But how do you find new source documents for new entities? And besides having humans read all of the source documents, how do you fact-check the output? What is needed is a self-updating knowledge base that learns jointly with a summarization model, keeping track of data provenance. Lucky for us, the world’s most comprehensive public encyclopedia is tightly coupled with Wikidata, the world’s most comprehensive public knowledge base. We have built a system called Quicksilver uses them both.
Mind the (Language) Gap. Neural Generation of Multilingual Wikipedia Summaries from Wikidata for ArticlePlaceholders
slides
By Lucie-Aimée Kaffee, Hady Elsahar, Pavlos Vougiouklis
While Wikipedia exists in 287 languages, its content is unevenly distributed among them. It is therefore of the utmost social and cultural interests to address languages for which native speakers have only access to an impoverished Wikipedia. In this work, we investigate the generation of summaries for Wikipedia articles in underserved languages, given structured data as an input. In order to address the information bias towards widely spoken languages, we focus on an important support for such summaries: ArticlePlaceholders, which are dynamically generated content pages in underserved Wikipedia versions. They enable native speakers to access existing information in Wikidata, a structured Knowledge Base (KB). Our system provides a generative neural network architecture, which processes the triples of the KB as they are dynamically provided by the ArticlePlaceholder, and generate a comprehensible textual summary. This data-driven approach is tested with the goal of understanding how well it matches the communities' needs on two underserved languages on the Web: Arabic, a language with a big community with disproportionate access to knowledge online, and Esperanto. With the help of the Arabic and Esperanto Wikipedians, we conduct an extended evaluation which exhibits not only the quality of the generated text but also the applicability of our end-system to any underserved Wikipedia version.
Token-level change tracking. Data, tools and insights
slides
By Fabian Flöck
This talk first gives an overview of the WikiWho infrastructure, which provides tracking of changes to single tokens (~words) in articles of different Wikipedia language versions. It exposes APIs for accessing this data in near-real time, and is complemented by a published static dataset. Several insights are presented regarding provenance, partial reverts, token-level conflict and other metrics that only become available with such data. Lastly, the talk will cover several tools and scripts that are already using the API and will discuss their application scenarios, such as investigation of authorship, conflicted content and editor productivity.
Conversations Gone Awry. Detecting Early Signs of Conversational Failure
slides
By Justine Zhang and Jonathan Chang, Cornell University
One of the main challenges online social systems face is the prevalence of antisocial behavior, such as harassment and personal attacks. In this work, we introduce the task of predicting from the very start of a conversation whether it will get out of hand. As opposed to detecting undesirable behavior after the fact, this task aims to enable early, actionable prediction at a time when the conversation might still be salvaged. To this end, we develop a framework for capturing pragmatic devices—such as politeness strategies and rhetorical prompts—used to start a conversation, and analyze their relation to its future trajectory. Applying this framework in a controlled setting, we demonstrate the feasibility of detecting early warning signs of antisocial behavior in online discussions.
Building a rich conversation corpus from Wikipedia Talk pages
By TBA
We present a corpus of conversations that encompasses the complete history of interactions between contributors to English Wikipedia's Talk Pages. This captures a new view of these interactions by containing not only the final form of each conversation but also detailed information on all the actions that led to it: new comments, as well as modifications, deletions and restorations. This level of detail supports new research questions pertaining to the process (and challenges) of large-scale online collaboration. As an example, we present a small study of removed comments highlighting that contributors successfully take action on more toxic behavior than was previously estimated.
ORES is an open, transparent, and auditable machine prediction platform for Wikipedians to help them do their work. It's currently used in 33 different Wikimedia projects to measure the quality of content, detect vandalism, recommend changes to articles, and to identify good-faith newcomers. The primary way that Wikipedians use ORES' predictions is through the tools developed by volunteers. These javascript gadgets, MediaWiki extensions, and web-based tools make up a complex ecosystem of Wikipedian processes -- encoded into software. In this presentation, Aaron will walk through a three key tools that Wikipedians have developed that make use of ORES, and he'll discuss how these novel process support technologies and the discussions around them have prompted Wikipedians to reflect on their work processes.
Every year, the Wikimedia Foundation relies on fundraising campaigns to help maintain the services it provides to millions of people worldwide. However, despite a large number of individuals who donate through these campaigns, these donors represent only a small percentage of Wikimedia users. In this work, we seek to advance our understanding of donors and their donation behaviors. Our findings offer insights to improve fundraising campaigns and to limit the burden of these campaigns on Wikipedia visitors.
The Critical Relationship of Volunteer-Created Wikipedia Content to Large-Scale Online Communities
By Nicholas Vincent, Northwestern University
The extensive Wikipedia literature has largely considered Wikipedia in isolation, outside of the context of its broader Internet ecosystem. Very recent research has demonstrated the significance of this limitation, identifying critical relationships between Google and Wikipedia that are highly relevant to many areas of Wikipedia-based research and practice. In this talk, I will present a study which extends this recent research beyond search engines to examine Wikipedia’s relationships with large-scale online communities, Stack Overflow and Reddit in particular. I will discuss evidence of consequential, albeit unidirectional relationships. Wikipedia provides substantial value to both communities, with Wikipedia content increasing visitation, engagement, and revenue, but we find little evidence that these websites contribute to Wikipedia in return. Overall, these findings highlight important connections between Wikipedia and its broader ecosystem that should be considered by researchers studying Wikipedia. Overall, this talk will emphasize the key role that volunteer-created Wikipedia content plays in improving other websites, even contributing to revenue generation.
The Rise and Decline of an Open Collaboration System, a Closer Look
By Nate TeBlunthuis, University of Washington
Do patterns of growth and stabilization found in large peer production systems such as Wikipedia occur in other communities? This study assesses the generalizability of Halfaker etal.’s influential 2013 paper on “The Rise and Decline of an Open Collaboration System.” We replicate its tests of several theories related to newcomer retention and norm entrenchment using a dataset of hundreds of active peer production wikis from Wikia. We reproduce the subset of the findings from Halfaker and colleagues that we are able to test, comparing both the estimated signs and magnitudes of our models. Our results support the external validity of Halfaker et al.’s claims that quality control systems may limit the growth of peer production communities by deterring new contributors and that norms tend to become entrenched over time.
Using Wikipedia categories for research: opportunities, challenges, and solutions
slides
By Tiziano Piccardi, EPFL
The category network in Wikipedia is used by editors as a way to label articles and organize them in a hierarchical structure. This manually created and curated network of 1.6 million nodes in English Wikipedia generated by arranging the categories in a child-parent relation (i.e., Scientists-People, Cities-Human Settlement) allows researchers to infer valuable relations between concepts. A clean structure in this format would be a valuable resource for a variety of tools and application including automatic reasoning tools. Unfortunately, Wikipedia category network contains some "noise" since in many cases the association as subcategory does not define an is-a relation (Scientists is-a People vs. Billionaires is-a Wealth). Inspired to develop a model for recommending sections to be added to the already existing Wikipedia articles, we developed a method to clean this network and to keep only the categories that have a high chance to be associated with their children by an is-a relation. The strategy is based on the concept of "pure" categories, and the algorithm uses the types of the attached articles to determine how homogenous the category is. The approach does not rely on any linguistic feature and therefore is suitable for all Wikipedia languages. In this talk, we will discuss the high-level overview of the algorithm and some of the possible applications for the generated network beyond article section recommendations.
Beyond Automatic Translation: Aligning Wikipedia sections across multiple languages
slides
By Diego Saez-Trumper
Sections are the building blocks of Wikipedia articles. For editors, they can be used as an entry point for creating and expanding articles. For readers, they enhance readability of Wikipedia content. In this talk, we present an ongoing research to align article sections across Wikipedia languages. We show how the available technology for automatic translations are not good enough for translating section titles. We then show a complementary approach for section alignment, using Wikidata and cross-lingual word embeddings. We will present some of the use-cases of a methodology for aligning sections across languages, including improved section recommendation, especially in medium to smaller size languages where the language itself may not contain enough signal about the structure of the articles and signals can be inferred from other larger Wikipedia languages.
Images allow us to explain, enrich and complement knowledge without language barriers.[1] They can help illustrate the content of an item in a language-agnostic way to external data consumers. Images can be extremely helpful in multilingual collaborative knowledge bases such as Wikidata.
However, a large proportion of Wikidata items lack images. More than 3.6M Wikidata items are about humans (Q5), but only 17% of them have an image associated with them. Only 2.2M of 40 Million Wikidata items have an image. A wider presence of images in such a rich, cross-lingual repository could enable a more complete representation of human knowledge.
In this talk, we will discuss challenges and opportunities faced when using machine learning and computer vision tools for the visual enrichment of collaborative knowledge bases. We will share research to help Wikidata contributors make Wikidata more “visual” by recommending high-quality Commons images to Wikidata items. We will show the first results on free-licence image quality scoring and recommendation and discuss future work in this direction.
Backlogs—backlogs everywhere
Using machine classification to clean up the new page backlog
If there's one insight that I've had about the functioning of Wikipedia and other wiki-based online communities, it's that eventually self-directed work breaks down and some form of organization becomes important for task routing. In Wikipedia specifically, the notion of "backlogs" has become dominant. There's backlogs of articles to create, articles to clean up, articles to assess, new editor contributions to review, manual of style rules to apply, etc. To a community of people working on a backlog, the state of that backlog has deep effects on their emotional well being. A backlog that only grows is frustrating and exhausting.
Backlogs aren't inevitable though and there are many shapes that backlogs can take. In my presentation, I'll tell a story about where English Wikipedia editors defined a process and set of roles that formed a backlog around new page creations. I'll make the argument that this formalization of quality control practices has created a choke point and that alternatives exist. Finally I'll present a vision for such an alternative using models that we have developed for ORES, the open machine prediction service my team maintains.
What motivates experts to contribute to public information goods? A field experiment at Wikipedia
By Yan Chen, University of Michigan
Wikipedia is among the most important information sources for the general public. Motivating domain experts to contribute to Wikipedia can improve the accuracy and completeness of its content. In a field experiment, we examine the incentives which might motivate scholars to contribute their expertise to Wikipedia. We vary the mentioning of likely citation, public acknowledgement and the number of views an article receives. We find that experts are significantly more interested in contributing when citation benefit is mentioned. Furthermore, cosine similarity between a Wikipedia article and the expert's paper abstract is the most significant factor leading to more and higher-quality contributions, indicating that better matching is a crucial factor in motivating contributions to public information goods. Other factors correlated with contribution include social distance and researcher reputation.
Wikihounding on Wikipedia
By Caroline Sinders, WMF
Wikihounding (a form of digital stalking on Wikipedia) is incredibly qualitative and quantitive. What makes wikihounding different then mentoring? It's the context of the action or the intention. However, all interactions inside of a digital space has a quantitive aspect to it, every comment, revert, etc is a data point. By analyzing data points comparatively inside of wikihounding cases and reading some of the cases, we can create a baseline for what are the actual overlapping similarities inside of wikihounding to study what makes up wikihounding. Wikihounding currently has a fairly loose definition. Wikihounding, as defined by the Harassment policy on en:wp, is: “the singling out of one or more editors, joining discussions on multiple pages or topics they may edit or multiple debates where they contribute, to repeatedly confront or inhibit their work. This is with an apparent aim of creating irritation, annoyance or distress to the other editor. Wikihounding usually involves following the target from place to place on Wikipedia.” This definition doesn't outline parameters around cases such as frequency of interaction, duration, or minimum reverts, nor is there a lot known about what a standard or canonical case of wikihounding looks like. What is the average wikihounding case? This talk will cover the approaches myself and members of the research team: Diego Saez-Trumper, Aaron Halfaker and Jonathan Morgan are taking on starting this research project.
Only 1% of English Wikipedia articles are labeled with quality class Good or better, and 37% of the articles are stubs. We are building an article expansion recommendation system to change this in Wikipedia, across many languages. In this presentation, I will talk with you about our current thinking of the vision and direction of the research that can help us build such a recommendation system, and share more about one specific area of research we have heavily focused on in the past months: building a recommendation system that can help editors identify what sections to add to an already existing article. I present some of the challenges we faced, the methods we devised or used to overcome them, and the result of the first line of experiments on the quality of such recommendations (teaser: the results are really promising. The precision and recall at 10 is 80%.)
Conversation Corpora, Emotional Robots, and Battles with Bias
By Lucas Dixon (Google/Jigsaw)
I'll talk about interesting experimental setups for doing large-scale analysis of conversations in Wikipedia, and what it even means to grapple with the concept of conversation when one is talking about revisions on talk pages. I'll also describe challenges with having good conversations at scale, some of the dreams one might have for AI in the space, and I'll dig into measuring unintended bias in machine learning and what one can do to make ML more inclusive. This talk will cover work from the WikiDetox project as well as ongoing research on the nature and impact of harassment in Wikipedia discussion spaces – part of a collaboration between Jigsaw, Cornell University, and the Wikimedia Foundation. The ML model training code, datasets, and the supporting tooling developed as part of this project are openly available. (slides)
October 2017
There was no showcase in October 2017. We attended WikidataCon in Berlin. We'll be back in November.
Multilinguality is an important topic for knowledge bases, especially Wikidata, that was build to serve the multilingual requirements of an international community. Its labels are the way for humans to interact with the data. In this talk, we explore the state of languages in Wikidata as of now, especially in regard to its ontology, and the relationship to Wikipedia. Furthermore, we set the multilinguality of Wikidata in the context of the real world by comparing it to the distribution of native speakers. We find an existing language maldistribution, which is less urgent in the ontology, and promising results for future improvements. An outlook on how users interact with languages on Wikidata will be given.
As the largest encyclopedia in the world, it is not surprising that Wikipedia reflects the state of scientific knowledge. However, Wikipedia is also one of the most accessed websites in the world, including by scientists, which suggests that it also has the potential to shape science. This paper shows that it does. Incorporating ideas into a Wikipedia article leads to those ideas being used more in the scientific literature. This paper documents this in two ways: correlationally across thousands of articles in Wikipedia and causally through a randomized experiment where we added new scientific content to Wikipedia. We find that fully a third of the correlational relationship is causal, implying that Wikipedia has a strong shaping effect on science. Our findings speak not only to the influence of Wikipedia, but more broadly to the influence of repositories of scientific knowledge. The results suggest that increased provision of information in accessible repositories is a very cost-effective way to advance science. We also find that such gains are equity-improving, disproportionately benefitting those without traditional access to scientific information.
Field Evaluation of an Interactive Tutorial for New Users
By Sneha Narayan
Integrating new users into a community with complex norms presents a challenge for peer production projects like Wikipedia. We present The Wikipedia Adventure (TWA): an interactive tutorial that offers a structured and gamified introduction to Wikipedia. In addition to describing the design of the system, we present two empirical evaluations. First, we report on a survey of users, who responded very positively to the tutorial. Second, we report results from a large-scale invitation-based field experiment that tests whether using TWA increased newcomers' subsequent contributions to Wikipedia. We find no effect of either using the tutorial or of being invited to do so over a period of 180 days. We conclude that TWA produces a positive socialization experience for those who choose to use it, but that it does not alter patterns of newcomer activity. We reflect on the implications of these mixed results for the evaluation of similar social computing systems.
Using Wikipedia and Wikidata to organize biomedical knowledge
By Andrew Su
The Gene Wiki project began in 2007 with the goal of creating a collaboratively-written, community-reviewed, and continuously-updated review article for every human gene within Wikipedia. In 2013, shortly after the creation of the Wikidata project, the project expanded to include the organization and integration of structured biomedical data. This talk will focus on our current and future work, including efforts to encourage contributions from biomedical domain experts, to build custom applications that use Wikidata as the back-end knowledge base, and to promote CC0-licensing among biomedical knowledge resources.
Freedom versus Standardization: Structured Data Generation in a Peer Production Community
By Andrew Hall
In addition to encyclopedia articles and software, peer production communities produce structured data, e.g., Wikidata and OpenStreetMap’s metadata. Structured data from peer production communities has become increasingly important due to its use by computational applications, such as CartoCSS, MapBox, and Wikipedia infoboxes. However, this structured data is usable by applications only if it follows standards. We did an interview study focused on OpenStreetMap’s knowledge production processes to investigate how – and how successfully – this community creates and applies its data standards. Our study revealed a fundamental tension between the need to produce structured data in a standardized way and OpenStreetMap’s tradition of contributor freedom. We extracted six themes that manifested this tension and three overarching concepts, correctness, community, and code, which help make sense of and synthesize the themes. We also offer suggestions for improving OpenStreetMap’s knowledge production processes, including new data models, sociotechnical tools, and community practices.
Problematizing and Addressing the Article-as-Concept Assumption in Wikipedia
slides
By Allen Yilun Lin
Wikipedia-based studies and systems frequently assume that each article describes a separate concept. However, in this paper, we show that this article-as-concept assumption is problematic due to editors’ tendency to split articles into parent articles and sub-articles when articles get too long for readers (e.g. “United States” and “American literature” in the English Wikipedia). In this paper, we present evidence that this issue can have significant impacts on Wikipedia-based studies and systems and introduce the subarticle matching problem. The goal of the sub-article matching problem is to automatically connect sub-articles to parent articles to help Wikipedia-based studies and systems retrieve complete information about a concept. We then describe the first system to address the sub-article matching problem. We show that, using a diverse feature set and standard machine learning techniques, our system can achieve good performance on most of our ground truth datasets, significantly outperforming baseline approaches.
Wikimedia provides a public service that lets anyone answer complex questions over the sum of all knowledge stored in Wikidata. These questions are expressed in the query language SPARQL and range from the most simple fact retrievals ("What is the birthday of Douglas Adams?") to complex analytical queries ("Average lifespan of people by occupation"). The talk presents ongoing efforts to analyse the server logs of the millions of queries that are answered each month. It is an important but difficult challenge to draw meaningful conclusions from this dataset. One might hope to learn relevant information about the usage of the service and Wikidata in general, but at the same time one has to be careful not to be misled by the data. Indeed, the dataset turned out to be highly heterogeneous and unpredictable, with strongly varying usage patterns that make it difficult to draw conclusions about "normal" usage. The talk will give a status report, present preliminary results, and discuss possible next steps. (Project page on meta)
While Wikipedia serves as the world's most widely reference for humans, it also represents the most widely use body of knowledge for algorithms that must reason about the world. I will provide an overview of WikiBrain, a software project that serves as a platform for Wikipedia-based algorithms. I will also demo a brand new system built on WikiBrain that visualizes any dataset as a topographic map whose neighborhoods correspond to related Wikipedia articles. I hope to get feedback about which directions for these tools are most useful to the Wikipedia research community.
By Isaac Johnson (GroupLens/University of Minnesota)
Wikipedia articles about places, OpenStreetMap features, and other forms of peer-produced content have become critical sources of geographic knowledge for humans and intelligent technologies. We explore the effectiveness of the peer production model across the rural/urban divide, a divide that has been shown to be an important factor in many online social systems. We find that in Wikipedia (as well as OpenStreetMap), peer-produced content about rural areas is of systematically lower quality, less likely to have been produced by contributors who focus on the local area, and more likely to have been generated by automated software agents (i.e. “bots”). We continue to explore and codify the systemic challenges inherent to characterizing rural phenomena through peer production as well as discuss potential solutions. (read more in this paper)
In this project, we learned embeddings for Wikipedia articles and Wikidata items by applying Word2vec models to a corpus of reading sessions. Although Word2vec models were developed to learn word embeddings from a corpus of sentences, they can be applied to any kind of sequential data. The learned embeddings have the property that items with similar neighbors in the training corpus have similar representations (as measured by the cosine similarity, for example). Consequently, applying Wor2vec to reading sessions results in article embeddings, where articles that tend to be read in close succession have similar representations. Since people usually generate sequences of semantically related articles while reading, these embeddings also capture semantic similarity between articles. (read more...)
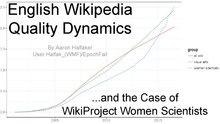
With every productive edit, Wikipedia is steadily progressing towards higher and higher quality. In order to track quality improvements, Wikipedians have developed an article quality assessment rating scale that ranges from "Stub" at the bottom to "Featured Articles" at the top. While this quality scale has the promise of giving us insights into the dynamics of quality improvements in Wikipedia, it is hard to use due to the sporadic nature of manual re-assessments. By developing a highly accurate prediction model (based on work by Warncke-Wang et al.), we've developed a method to assess an articles quality at any point in history. Using this model, we explore general trends in quality in Wikipedia and compare these trends to those of an interesting cross-section: Articles tagged by WikiProject Women Scientists. Results suggest that articles about women scientists were lower quality than the rest of the wiki until mid-2013, after which a dramatic shift occurred towards higher quality. This shift may correlate with (and even be caused by) this WikiProjects initiatives.
Privacy, Anonymity, and Perceived Risk in Open Collaboration. A Study of Tor Users and Wikipedians
In a recent qualitative study to be published at CSCW 2017, collaborators Rachel Greenstadt, Naz Andalibi, and I examined privacy practices and concerns among contributors to open collaboration projects. We collected interview data from people who use the anonymity network Tor who also contribute to online projects and from Wikipedia editors who are concerned about their privacy to better understand how privacy concerns impact participation in open collaboration projects. We found that risks perceived by contributors to open collaboration projects include threats of surveillance, violence, harassment, opportunity loss, reputation loss, and fear for loved ones. We explain participants’ operational and technical strategies for mitigating these risks and how these strategies affect their contributions. Finally, we discuss chilling effects associated with privacy loss, the need for open collaboration projects to go beyond attracting and educating participants to consider their privacy, and some of the social and technical approaches that could be explored to mitigate risk at a project or community level.
Every day, millions of readers come to Wikipedia to satisfy a broad range of information needs, however, little is known about what these needs are. In this presentation, I share the result of a research that sets to help us understand Wikipedia readers better. Based on an initial user study on English, Persian, and Spanish Wikipedia, we build a taxonomy of Wikipedia use-cases along several dimensions, capturing users’ motivations to visit Wikipedia, the depth of knowledge they are seeking, and their knowledge of the topic of interest prior to visiting Wikipedia. Then, we quantify the prevalence of these use-cases via a large-scale user survey conducted on English Wikipedia. Our analyses highlight the variety of factors driving users to Wikipedia, such as current events, media coverage of a topic, personal curiosity, work or school assignments, or boredom. Finally, we match survey responses to the respondents’ digital traces in Wikipedia’s server logs, enabling the discovery of behavioral patterns associated with specific use-cases. Our findings advance our understanding of reader motivations and behavior on Wikipedia and have potential implications for developers aiming to improve Wikipedia’s user experience, editors striving to cater to (a subset of) their readers’ needs, third-party services (such as search engines) providing access to Wikipedia content, and researchers aiming to build tools such as article recommendation engines.
Wikidata is a Wikimedia project which stores structured data to be used by other Wikimedia projects like Wikipedia. Currently, integrating its data in Wikipedia is difficult for users, since there’s no predefined way to do so and requires some technical knowledge. To tackle these issues, human-centered design methods were applied to find needs from which solutions were generated and evaluated with the help of the community. The concept may serve as a basis which may be implemented into various Wiki projects in the future to make editing Wikidata from within another Wikimedia project more user-friendly and improve the project’s acceptance in the community.
Online production communities present an exciting opportunity for investigating novel organizational forms. Extant theoretical accounts of knowledge co-production point to organizational policies, norms, and communication as key mechanisms enabling the coordination of work. Yet, in practice participants in initiatives such as Wikipedia are often occasional contributors who are unaware of community policies and do not communicate with other members. How then is work coordinated and how does the organization maintain stability in the face of dynamics in individuals’ task enactment? In this study we develop a conceptualization of emergent roles - the prototypical activity patterns that organically emerge from individuals’ spontaneous actions – and investigate the temporal dynamics of emergent role behaviors. Conducing a multi-level large-scale empirical study stretching over a decade, we tracked co-production of a thousand Wikipedia articles, logging two hundred thousand distinct participants and seven hundred thousand co-production activities. Using a combination of manual tagging and machine learning, we annotated each activity type, and then clustered participants’ activity profiles to arrive at seven prototypical emergent roles. Our analysis shows that participants’ behavior is turbulent, with substantial flow in and out of co-production work and across roles. Our findings at the organizational level, however, show that work is organized around a highly stable set of emergent roles, despite the absence of traditional stabilizing mechanisms such as pre-defined work procedures or role expectations. We conceptualize this dualism in emergent work as “Turbulent Stability”. Further analyses suggest that co-production is artifact-centric, where contributors mutually adjust according to the artifact’s changing needs. Our study advances the theoretical understandings of self-organizing knowledge co-production and particularly the nature of emergent roles.
Slides: [1] An important editing policy in Wikipedia is to provide citations for added statements in Wikipedia pages, where statements can be arbitrary pieces of text, ranging from a sentence to a paragraph. In many cases citations are either outdated or missing altogether. In this work we address the problem of finding and updating news citations for statements in entity pages. We propose a two- stage supervised approach for this problem. In the first step, we construct a classifier to find out whether statements need a news citation or other kinds of citations (web, book, journal, etc.). In the second step, we develop a news citation algorithm for Wikipedia statements, which recommends appropriate citations from a given news collection. Apart from IR techniques that use the statement to query the news collection, we also formalize three properties of an appropriate citation, namely: (i) the citation should entail the Wikipedia statement, (ii) the statement should be central to the citation, and (iii) the citation should be from an authoritative source. We perform an extensive evaluation of both steps, using 20 million articles from a real-world news collection. Our results are quite promising, and show that we can perform this task with high precision and at scale.
Today, conversations are everywhere on the Internet and come in many different forms. However, there are still many problems with discussion interfaces today. In my talk, I will first give an overview of some of the problems with discussion systems, including difficulty dealing with large scales, which exacerbates additional problems with navigating deep threads containing lots of back-and-forth and getting an overall summary of a discussion. Other problems include dealing with moderation and harassment in discussion systems and gaining control over filtering, customization, and means of access. Then I will focus on a few projects I am working on in this space now. The first is Wikum, a system I developed to allow users to collaboratively generate a wiki-like summary from threaded discussion. The second, which I have just begun, is exploring the design space of presentation and navigation of threaded discussion. I will next discuss Murmur, a mailing list hybrid system we have built to implement and test ideas around filtering, customization, and flexibility of access, as well as combating harassment. Finally, I'll wrap up with what I am working on at Google Research this summer: developing a taxonomy to describe online forum discussion and using this information to extract meaningful content useful for search, summarization of discussions, and characterization of communities.
Traditional fact checking by expert journalists cannot keep up with the enormous volume of information that is now generated online. Fact checking is often a tedious and repetitive task and even simple automation opportunities may result in significant improvements to human fact checkers. In this talk I will describe how we are trying to approximate the complexities of human fact checking by exploring a knowledge graph under a properly defined proximity measure. Framed as a network traversal problem, this approach is feasible with efficient computational techniques. We evaluate this approach by examining tens of thousands of claims related to history, entertainment, geography, and biographical information using the public knowledge graph extracted from Wikipedia by the DBPedia project, showing that the method does indeed assign higher confidence to true statements than to false ones. One advantage of this approach is that, together with a numerical evaluation, it also provides a sequence of statements that can be easily inspected by a human fact checker.
Deploying and maintaining AI in a socio-technical system. Lessons learned
We should exercise great caution when deploying AI into our social spaces. The algorithms that make counter-vandalism in Wikipedia orders of magnitude more efficient also have the potential to perpetuate biases and silence whole classes of contributors. This presentation will describe the system efficiency characteristics that make AI so attractive for supporting quality control activities in Wikipedia. Then, Aaron will tell two stories of how the algorithms brought new, problematic biases to quality control processes in Wikipedia and how the Revision Scoring team learned about and addressed these issues in ORES, a production-level AI service for Wikimedia Wikis. He'll also make an overdue call to action toward leveraging human-review of AIs biases in the practice of AI development.
Ellery Wulczyn (WMF) and Nithum Thain (Jigsaw) will be speaking about their recent work on Project Detox, a research project to develop tools to detect and understand online personal attacks and harassment on Wikipedia. Their talk will cover the whole research pipeline to date, including data acquisition, machine learning model building, and some analytical insights as to the nature of personal attacks on Wikipedia talk pages.
Wikipedia.org Portal Research
Search behaviors and New Language by article count Dropdown
What part do the Wikipedia.org portal and on-wiki search mechanisms play in users' experiences finding information online? These findings reflect research participants' responses to a combination of generative and evaluative questions about their general online search behaviors, on-wiki search behaviors, interactions with the Wikipedia.org portal, and their thoughts about a partial re-design of the portal page, the new language by article count dropdown.
The cumulative effect of collective online participation has an important and adverse impact on individual privacy. As an online system evolves over time, new digital traces of individual behavior may uncover previously hidden statistical links between an individual’s past actions and her private traits. To quantify this effect, we analyze the evolution of individual privacy loss by studying the edit history of Wikipedia over 13 years, including more than 117,523 different users performing 188,805,088 edits. We trace each Wikipedia’s contributor using apparently harmless features, such as the number of edits performed on predefined broad categories in a given time period (e.g. Mathematics, Culture or Nature). We show that even at this unspecific level of behavior description, it is possible to use off-the-shelf machine learning algorithms to uncover usually undisclosed personal traits, such as gender, religion or education. We provide empirical evidence that the prediction accuracy for almost all private traits consistently improves over time. Surprisingly, the prediction performance for users who stopped editing after a given time still improves. The activities performed by new users seem to have contributed more to this effect than additional activities from existing (but still active) users. Insights from this work should help users, system designers, and policy makers understand and make long-term design choices in online content creation systems.
Building from a call to action around measuring value-adding behavior in Wikipedia from Wikimania 2014, I'll show preliminary results of measuring editor productivity in English Wikipedia. From this analysis some surprising results have emerged: (1) IP editors contribute about 20% of good new content to Wikipedia articles, (2) the overall productivity of registered editors has been holding constant since 2007 -- despite declines in the community and labor hours invested in editing. (1) suggests that we should consider better supporting editing without an account and (2) suggests that Wikipedians are somehow contributing more efficiently than they used to.
Relying on the behavior of Wikipedia contributors in a (game-theoretic) social experiment, I will seek to engage the community in a reflection about ways to create a more inclusive Wikipedia. First, I will identify the underlying demographic and social determinants of anti-social behavior within Wikipedia -- an often cited driver of its declining retention rates. Second, I will study the relationship between Wikipedia administrators' trust in anonymous strangers and their policing activity patterns, asking the question of the optimal level of trust that admins should exhibit in order to efficiently protect Wikipedia from malicious users while avoiding to drive well-intentioned ones away from the project.
False information on Wikipedia raises concerns about its credibility. One way in which false information may be presented on Wikipedia is in the form of hoax articles, i.e. articles containing fabricated facts about nonexistent entities or events. In this talk, we study false information on Wikipedia by focusing on the hoax articles that have been created throughout its history. First, we assess the real-world impact of hoax articles by measuring how long they survive before being debunked, how many pageviews they receive, and how heavily they are referred to by documents on the Web. We find that, while most hoaxes are detected quickly and have little impact on Wikipedia, a small number of hoaxes survive long and are well cited across the Web. Second, we characterize the nature of successful hoaxes by comparing them to legitimate articles and to failed hoaxes that were discovered shortly after being created. We find characteristic differences in terms of article structure and content, embeddedness into the rest of Wikipedia, and features of the editor who created the hoax. Third, we successfully apply our findings to address a series of classification tasks, most notably to determine whether a given article is a hoax. And finally, we describe and evaluate a task involving humans distinguishing hoaxes from non-hoaxes. We find that humans are not particularly good at the task and that our automated classifier outperforms them by a big margin.
New Wikipedia editors face a variety of social and technical barriers to participation. These barriers have been shown to cause even promising, highly-motivated newcomers to give up and leave Wikipedia shortly after joining.[9] The Wikipedia Teahouse was launched in 2012 to provide new editors with a space on Wikipedia where they could ask questions, introduce themselves, and learn the ropes of editing in a friendly and supportive environment, with the goal of increasing the percentage of good-faith newcomers who go on to become productive Wikipedians. Research has shown[10][11] that the Teahouse provided a positive experience for participants, and suggested[12] that participating in the Teahouse led to more editing activity and longer survival for new editors who participated. The current study[13] examines the impact of Teahouse invitations on new editors survival over a longer period of time (2-6 months), and presents findings related to contextual factors within editors' first few sessions that are associated with overall survival rate and editing patterns associated with increased likelihood of visiting the Teahouse.
In peer production communities like Wikipedia, individual community members typically decide for themselves where to make contributions, often driven by factors such as “fun” or a belief that “information should be free”. However, the extent to which this bottom-up, interest-driven content production paradigm meets the need of consumers of this content is unclear. In this talk, I analyse four large Wikipedia language editions, finding extensive misalignment between production and consumption of quality content in all of them, and I show how this greatly impacts Wikipedia’s readers. I also examine misalignment in more detail by studying how it relates to specific topics, and to what extent high popularity is related to sudden changes in demand (i.e. “breaking news”). Finally, I discuss technologies and community practices that can help reduce misalignment in Wikipedia. See the paper[14].
Automated News Suggestions for Populating Wikipedia Entity Pages
Wikipedia entity pages are a valuable source of information for direct consumption and for knowledge-base construction, update and maintenance. Facts in these entity pages are typically supported by references. Recent studies show that as much as 20% of the references are from online news sources. However, many entity pages are incomplete even if relevant information is already available in existing news articles. Even for the already present references, there is often a delay between the news article publication time and the reference time. In this work, we therefore look at Wikipedia through the lens of news and propose a novel news-article suggestion task to improve news coverage in Wikipedia, and reduce the lag of newsworthy references. Our work finds direct application, as a precursor, to Wikipedia page generation and knowledge-base acceleration tasks that rely on relevant and high quality input sources. We propose a two-stage supervised approach for suggesting news articles to entity pages for a given state of Wikipedia. First, we suggest news articles to Wikipedia entities (article-entity placement) relying on a rich set of features which take into account the salience and relative authority of entities, and the novelty of news articles to entity pages. Second, we determine the exact section in the entity page for the input article (article-section placement) guided by class-based section templates. We perform an extensive evaluation of our approach based on ground-truth data that is extracted from external references in Wikipedia. We achieve a high precision value of up to 93% in the article-entity suggestion stage and upto 84% for the article-section placement. Finally, we compare our approach against competitive baselines and show significant improvements.
August 2015
The August showcase was canceled due to scheduling conflicts.
It's been nearly two years since we ran an initial study of VisualEditor's effect on newly registered editors. While most of the results of this study were positive (e.g. workload on Wikipedians did not increase), we still saw a significant decrease in the newcomer productivity. In the meantime, the Editing team has made substantial improvements to performance and functionality. In this presentation, I'll report on the results of a new experiment designed to test the effects of enabling this improved VisualEditor software for newly registered users by default. I'll show what we learned from the experiment and discuss some results have opened larger questions about what, exactly, is difficult about being a newcomer to English Wikipedia.
Wikipedia knowledge graph with DeepDive
slides
By Juhana Kangaspunta and Thomas Palomares
Despite the tremendous amount of information present on Wikipedia, only a very little amount is structured. Most of the information is embedded in text and extracting it is a non-trivial challenge. In this project, we try to populate Wikidata, a structured component of Wikipedia, using Deepdive tool to extract relations embedded in the text. We finally extracted more than 140,000 relations with more than 90% average precision.This report is structured as follows: first we present DeepDive and the data that we use for this project. Second, we clarify the relations we focused on so far and explain the implementation and pipeline, including our model, features and extractors. Finally, we detail our results with a thorough precision and recall analysis.
June 2015
The June showcase was canceled due to scheduling conflicts.
Recent research has implicated that Wikipedia's algorithmic infrastructure is perpetuating social issues. However, these same algorithmic tools are critical to maintaining efficiency of open projects like Wikipedia at scale. But rather than simply critiquing algorithmic wiki-tools and calling for less algorithmic infrastructure, I'll propose a different strategy -- an open approach to building this algorithmic infrastructure. In this presentation, I'll demo a set of services that are designed to open a critical part Wikipedia's quality control infrastructure -- machine classifiers. I'll also discuss how this strategy unites critical/feminist HCI with more dominant narratives about efficiency and productivity.
An emerging Internet trend is greater social transparency, such as the use of real names in social networking sites, feeds of friends' activities, traces of others' re-use of content, and visualizations of team interactions. There is a potential for this transparency to radically improve coordination, particularly in open collaboration settings like Wikipedia. In this talk, we will describe some of our research identifying how transparency influences collaborative performance in online work environments. First, we have been studying professional social networking communities. Social media allows individuals in these communities to create an interest network of people and digital artifacts, and get moment-by-moment updates about actions by those people or changes to those artifacts. It affords and unprecedented level of transparency about the actions of others over time. We will describe qualitative work examining how members of these communities use transparency to accomplish their goals. Second, we have been looking at the impact of making workflows transparent. In a series of field experiments we are investigating how socially transparent interfaces, and activity trace information in particular, influence perceptions and behavior towards others and evaluations of their work.
Paradoxically, users in remixing communities don’t remix very much. But an analysis of one remix community, Thingiverse, shows that those who actively remix end up producing work that is in turn more likely to remixed. What does this suggest about Wikipedia editing? Wikipedia allows more types of contribution, because creating and editing pages are done in a planning context: plans are discussed on particular loci, including project talk pages. Plans on project talk pages lead to both creation and editing; some editors specialize in making article changes and others, who tend to have more experience, focus on planning rather than acting. Contributions can happen at the level of the article and also at a series of meta levels. Some patterns of behavior – with respect to creating versus editing and acting versus planning – are likely to lead to more sustained engagement and to higher quality work. Experiments are proposed to test these conjectures.
Authority, power and culture on Wikipedia: The oral citations debate
In 2011, Wikimedia Foundation Advisory Board member, Achal Prabhala was funded by the WMF to run a project called 'People are knowledge' or the Oral citations project. The goal of the project was to respond to the dearth of published material about topics of relevance to communities in the developing world and, although the majority of articles in languages other than English remain intact, the English editions of these articles have had their oral citations removed. I ask why this happened, what the policy implications are for oral citations generally, and what steps can be taken in the future to respond to the problem that this project (and more recent versions of it) set out to solve. This talk comes out of an ethnographic project in which I have interviewed some of the actors involved in the original oral citations project, including the majority of editors of the surr article that I trace in a chapter of my PhD [2].
Session identification is a common strategy used to develop metrics for web analytics and behavioral analyses of user-facing systems. Past work has argued that session identification strategies based on an inactivity threshold is inherently arbitrary or advocated that thresholds be set at about 30 minutes. In this work, we demonstrate a strong regularity in the temporal rhythms of user initiated events across several different domains of online activity (incl. video gaming, search, page views and volunteer contributions). We describe a methodology for identifying clusters of user activity and argue that regularity with which these activity clusters appear implies a good rule-of-thumb inactivity threshold of about 1 hour. We conclude with implications that these temporal rhythms may have for system design based on our observations and theories of goal-directed human activity.
Mining Missing Hyperlinks from Human Navigation Traces
Wikipedia relies crucially on the links between articles, but important links are often missing. In most prior work, the problem of detecting missing links is addressed by constructing a model of the existing link structure and then predicting the missing links based on this model. In this work we propose a novel method that does not rely on such a model of the static structure of existing links, but rather starts from data capturing how these links are used by people. The approach is guided by the intuition that the ultimate purpose of hyperlinks is to aid navigation, so we argue that the objective should be to suggest links that are likely to be clicked by users. In a nutshell, our algorithm suggests an as yet non-existent link from S to T for addition if users who open S are much more likely than random to later also open T. We show that this simple algorithm yields good link suggestions when run on data from the human-computation game Wikispeedia.net. Finally, we show preliminary results that show the method also works "in the wild", i.e., on navigation data mined directly from Wikipedia's server logs.
Users' trends in the Global South have significantly changed over the past two years, and given the increase in interest in Global South communities and their activities, we wanted this survey to focus on understanding the statistics and needs of our users (both readers, and editors) in the regions listed in the WMF's New Global South Strategy. This survey aims to provide a better understanding of the specific needs of local user communities in the Global South, as well as provide data that supports product and program development decision making process.
Presentation slides.
Ingesting Open Geodata: Observations from OpenStreetMap
As Wikidata grapples with the challenges of ingesting external data sources such as Freebase, what lessons can we learn from other open knowledge projects that have had similar experiences? OpenStreetMap, often called "The Wikipedia of Maps", is a crowdsourced geospatial data project covering the entire world. Since the earliest years of the project, OSM has combined user contributions with existing data imported from external sources. Within the OSM community, these imports have been controversial; some core OSM contributors complain that imported data is lower quality than user-contributed data, or that it discourages the growth of local mapping communities. In this talk, I'll review the history of data imports in OSM, and describe how OSM's best-practices have evolved over time in response to these critiques.
An understanding of participation dynamics within online production communities requires an examination of the roles assumed by participants. Recent studies have established that the organizational structure of such communities is not flat; rather, participants can take on a variety of well-defined functional roles. What is the nature of functional roles? How have they evolved? And how do participants assume these functions? Prior studies focused primarily on participants' activities, rather than functional roles. Further, extant conceptualizations of role transitions in production communities, such as the Reader to Leader framework, emphasize a single dimension: organizational power, overlooking distinctions between functions. In contrast, in this paper we empirically study the nature and structure of functional roles within Wikipedia, seeking to validate existing theoretical frameworks. The analysis sheds new light on the nature of functional roles, revealing the intricate "career paths" resulting from participants' role transitions.
In some of my research with Leah Buechley, I've explored the way that increasing engagement and diversity in technology communities often means not just attacking systematic barriers to participation but also designing for new genres and types of engagement. I hope to facilitate a conversation about how WMF might engage new readers by supporting more non-encyclopedic production. I'd like to call out some examples from the new Wikimedia project proposals list, encourage folks to share entirely new ideas, and ask for ideas about how we could dramatically better support Wikipedia's sister projects.
A dive into the data we have around readership that investigates the rising popularity of the mobile web, countries and projects that are racing ahead of the pack, and what changes in user behaviour we can expect to see as mobile grows.
Global Disease Monitoring and Forecasting with Wikipedia
Infectious disease is a leading threat to public health, economic stability, and other key social structures. Efforts to mitigate these impacts depend on accurate and timely monitoring to measure the risk and progress of disease. Traditional, biologically-focused monitoring techniques are accurate but costly and slow; in response, new techniques based on social internet data, such as social media and search queries, are emerging. These efforts are promising, but important challenges in the areas of scientific peer review, breadth of diseases and countries, and forecasting hamper their operational usefulness. We examine a freely available, open data source for this use: access logs from the online encyclopedia Wikipedia. Using linear models, language as a proxy for location, and a systematic yet simple article selection procedure, we tested 14 location-disease combinations and demonstrate that these data feasibly support an approach that overcomes these challenges. Specifically, our proof-of-concept yields models with r² up to 0.92, forecasting value up to the 28 days tested, and several pairs of models similar enough to suggest that transferring models from one location to another without re-training is feasible. Based on these preliminary results, we close with a research agenda designed to overcome these challenges and produce a disease monitoring and forecasting system that is significantly more effective, robust, and globally comprehensive than the current state of the art.
In the first half of the talk, I will present our empirical analysis of the effects of team competition on pro-social lending activity on Kiva.org, the first microlending website to match lenders with entrepreneurs in developing countries. Using naturally occurring field data, we find that lenders who join teams contribute 1.2 more loans per month than those who do not. Furthermore, teams differ in activity levels. To investigate this heterogeneity, we run a field experiment by posting forum messages. Compared to the control, we find that lenders from inactive teams make significantly more loans when exposed to a goal-setting message and that team coordination increases the magnitude of this effect.
In the second part of the talk, I will discuss a randomized field experiment we did in May 2014, when we recommend teams to lenders on Kiva. We find that lenders are more likely to join teams in their local area. However, after joining teams, those who join popular teams (on the leaderboard) are more active in lending.
Emotions under Discussion: Gender, Status and Communication in Wikipedia
By David Laniado: I will present a large-scale analysis of emotional expression and communication style of editors in Wikipedia discussions. The talk will focus especially on how emotion and dialogue differ depending on the status, gender, and the communication network of the about 12000 editors who have written at least 100 comments on the English Wikipedia's article talk pages. The analysis is based on three different predefined lexicon-based methods for quantifying emotions: ANEW, LIWC and SentiStrength. The results unveil significant differences in the emotional expression and communication style of editors according to their status and gender, and can help to address issues such as gender gap and editor stagnation.
Wikipedia as a socio-technical system
slides
By Aaron Halfaker: Wikipedia is a socio-technical system. In this presentation, I'll explain how the integration of human collective behavior ("social") and information technology ("technical") has lead to phenomena that, while being massively productive, is poorly understood due to lack of precedence. Based on my work in this area, I'll describe five critical functions that healthy, Wikipedia-like socio-technical systems must serve in order to continue to function: allocation, regulation, quality control, community management and reflection. Finally, I'll conclude with an overview of three classes of new projects that should provide critical opportunities to both practically and academically understand the maintenance of Wikipedia's socio-technical fitness.
September 2014
September 17, 2014The September showcase was canceled because of a conflict with other events scheduled by WMF. We will resume showcases in October.
Everything You Know About Mobile Is WrW^Right: Editing and Reading Pattern Variation Between User Types
slides
By Oliver Keyes: Using new geolocation tools, we look at reader and editor behaviour to understand how and when people access and contribute to our content. This is largely exploratory research, but has potential implications for our A/B testing and how we understand both cultural divides between reader and editor groups from different countries, and how we understand the differences between types of edit and the editors who make them.
Wikipedia Article Curation: Understanding Quality, Recommending Tasks
slides
By Morten Warncke-Wang: In this talk we look at article curation in Wikipedia through the lens of task suggestions and article quality. The first part of the talk presents SuggestBot, the Wikipedia article recommender. SuggestBot connects contributors with articles similar to those they previously edited. In the second part of the talk, we discuss Wikipedia article quality using “actionable” features, features that contributors can easily act upon to improve article quality. We will first discuss these features’ ability to predict article quality, before coming back to SuggestBot and show how these predictions and actionable features can be used to improve the suggestions.
By Aaron Halfaker: Along with quantitative research comes data and analysis code. In this presentation, Aaron will introduce you to 4 python libraries that capture code he uses on a regular basis to get his wiki research done. MediaWiki Utilities is a general data processing library that includes connectors for the API and MySQL databases as well as an XML dump parser and revert detection. Wiki-Class is a machine learning library that is designed to train, test and deploy automatic quality assessment class detection for Wikipedia articles. MediaWiki-OAuth provides a simple interface for performing an OAuth handshake with a MediaWiki installation (e.g. Wikipedia). Deltas is an experimental text difference detection library that implements cutting-edge research to track changes to Wikipedia articles and attribute authorship of content.
Using Open Data and Stories to Broaden Crowd Content
By Nathan Matias: Nathan will share a series of research on gender diversity online and designs for collaborative content creation that foster learning and community. He will also demo a prototype for a system that could leverage open data to attract and support new Wikipedia contributors.
by Giovanni Luca Ciampaglia -- I will talk about MoodBar, an experimental feature deployed on the English Wikipedia from 2011 to 2013 to streamline the socialization of newcomers. I will present results from a natural experiment that measured the effect of Moodbar on the short-term engagement and long-term retention of newly registered users attempting to edit for the first time Wikipedia. Our results indicate that a mechanism to elicit lightweight feedback and to provide early mentoring to newcomers significantly improves their chances of becoming long-term contributors.
Slides.Active Editors' Survival Models
by Leila Zia -- I will talk about first results in building prediction models for active editors' survival. A sample of such prediction models, their performance, and the important variables in predicting survival will be presented.
by Dario Taraborelli -- In this talk I will give a high-level overview of data on new editor activation, presenting longitudinal data from the largest Wikipedias, a comparison between desktop and mobile registrations and the relative activation rates of different cohorts of newbies.
Collaboration patterns in Articles for Creation
slides
by Aaron Halfaker -- Wikipedia needs to attract and retain newcomers while also increasing the quality of its content. Yet new Wikipedia users are disproportionately affected by the quality assurance mechanisms designed to thwart spammers and promoters. English Wikipedia’s en:WP:Articles for Creation provides a protected space for newcomers to draft articles, which are reviewed against minimum quality guidelines before they are published. In this presentation, describe and a study of how this drafting process has affected the productivity of newcomers in Wikipedia. Using a mixed qualitative and quantitative approach, I'll show the process's pre-publication review, which is intended to improve the success of newcomers, in fact decreases newcomer productivity in English Wikipedia and offer recommendations for system designers.
slides (presenter notes)by Jonathan Morgan -- in this talk I'll give an overview of some research[3][4] on English Wikipedia Wikiprojects: what kind of work they do, how they do it, and how they have changed over time.
Visualizing Wikipedia Communities using Gephi
by Haitham Shammaa -- I will introduce Gephi as a tool for generating a visualized representation of Wikimedia projects communities. Gephi is an open-source network analysis and visualization software, and is utilized to generate graphs that represent users and the interaction among them based on the frequency they send messages to each other on their talk pages.
by Aaron Halfaker -- In Halfaker et al. (2013) we present data that show that several changes the Wikipedia community made to manage quality and consistency in the face of a massive growth in participation have ironically crippled the very growth they were designed to manage. Specifically, the restrictiveness of the encyclopedia's primary quality control mechanism and the algorithmic tools used to reject contributions are implicated as key causes of decreased newcomer retention.
by Oliver Keyes -- A prerequisite to many pieces of interesting reader research is being able to accurately identify the length of users' 'sessions'. I will explain one potential way of doing it, how I've applied it to mobile readers, and what research this opens up. (slides, read more)
Wikipedia article creation research
by Aaron Halfaker -- A brief overview of research examining trends in newcomer article creation across 10 languages with a focus on English and German Wikipedias. In wikis where anonymous users can create articles, their articles are less likely to be deleted than articles created by newly registered editors. An in-depth analysis of Articles for Creation (AfC) suggests that while AfC's process seems to result in the publication of high quality articles, it also dramatically reduces the rate at which good new articles are published. (slides, read more)
January 2014
January 15, 2014
IP reliability tracking
by Oliver Keyes
The Wikipedia Adventure, quantitative and qualitative results from the pilot
by Jake Orlowitz (User:Ocaasi) We made a 7 mission gamified interactive onboarding tutorial to teach people how to edit Wikipedia in 1 hour. The journey involves badges, barnstars, challenges, and simulated interaction throughout a realistic quest to edit the article Earth. Game dynamics were used to create a sense of understanding, belonging, deep value identification, and technical proficiency. The use of games in open source and free culture online communities has great potential to drive participation. This talk will share the inspiration for taking a gamified approach, a review of the design highlights, and a discussion of quantitative and qualitative data and survey analysis. (slides, read more)
by Aaron Halfaker -- A brief discussion & critique of the use of the term "anonymous" to refer to IP editors and a presentation of research results that suggest that newly registered users who edit anonymous right before registering their account are highly productive. (slides, read more)
by Jaime Anstee -- A brief overview of the first round reporting for programs including summary of the target measures along with strategies and challenges in metric standardization. Overview outline
↑Thompson, Neil and Hanley, Douglas, Science Is Shaped by Wikipedia: Evidence from a Randomized Control Trial (September 19, 2017). Available at SSRN: https://ssrn.com/abstract=3039505
↑Sneha Narayan, Jake Orlowitz, Jonathan Morgan, Benjamin Mako Hill, and Aaron Shaw. 2017. The Wikipedia Adventure: Field Evaluation of an Interactive Tutorial for New Users. In Proceedings of the 2017 ACM Conference on Computer Supported Cooperative Work and Social Computing (CSCW '17). ACM, New York, NY, USA, 1785-1799. DOI: https://doi.org/10.1145/2998181.2998307PDF
↑Andrew Hall, Sarah McRoberts, Jacob Thebault-Spieker, Yilun Lin, Shilad Sen, Brent Hecht, and Loren Terveen. "Freedom versus Standardization: Structured Data Generation in a Peer Production Community", CHI 2017. https://doi.org/10.1145/3025453.3025940PDF
↑Warncke-Wang, M, Ranjan, V., Terveen, L., and Hecht, B. "Misalignment Between Supply and Demand of Quality Content in Peer Production Communities", ICWSM 2015. pdf See also: Signpost/Research Newsletter coverage