Employing retrieval-augmented generation (RAG) is an effective strategy for ensuring large language model (LLM) responses are up-to-date and not hallucinated.
While various retrieval strategies can improve the recall of documents for generation, there is no one-size-fits-all approach. The retrieval pipeline depends on your data, from hyperparameters like the chunk size, and number of documents returned, to retrieval algorithms like semantic search or graph retrieval.
Retrieval strategies may differ, but it’s becoming more common for modern RAG systems to add an agentic framework on top of a retrieval system. This framework handles reasoning, decision-making, and reflection on the retrieved data. An agent is a system that can use an LLM to reason through a problem, create a plan to solve the problem and execute the plan with the help of a set of tools.
For example, LLMs are notoriously bad at solving math problems. Giving an LLM a calculator “tool” that it can use to perform mathematical tasks while it reasons through calculating a YoY increase of a company’s revenue can be described as an agentic workflow.
As generative AI systems start transitioning towards entities capable of performing agentic tasks, we need robust models trained on the ability to break down tasks, act as central planners, and have multi-step reasoning abilities with model and system-level safety checks. With the Llama 3.1 family, Meta is launching a suite of LLMs spanning 8B, 70B, and 405B parameters with these tool-calling capabilities for agentic workloads. NVIDIA has partnered with Meta to make sure the latest Llama models can be deployed optimally through NVIDIA NIMs.
With the general availability of the NVIDIA NeMo Retriever collection of NIM microservices, enterprises have access to scalable software to customize their data-dependent RAG pipelines. The NeMo Retriever NIMs can be easily plugged into existing RAG pipelines and interfaces with open-source LLM frameworks like LangChain or LlamaIndex, so you can easily integrate retriever models into generative AI applications.
LLMs and NIMs: A powerful RAG duo
In a customizable agentic RAG, an LLM capable of function calling plays a greater role than the final answer generation. While NeMo Retriever NIMs bring the power of state-of-the-art text embedding and reranking to your retrieval pipeline, the LLM can be used for higher-level decision-making on retrieved data, structured output generation, and tool calling.
NVIDIA NeMo Retriever NIMs
To create the final pipeline, a set of NeMo Retriever microservices can be used for embedding and reranking. These microservices can be deployed within the enterprise locally, and are packaged together with NVIDIA Triton Inference Server and NVIDIA TensorRT for optimized inference of text for embedding and reranking. Additional enterprise benefits include:
- Scalable deployment: Whether you’re catering to a few users or millions, NeMo Retriever embedding and reranking NIMs can be scaled seamlessly to meet your demands.
- Flexible integration: Easily incorporate NeMo Retriever embedding and reranking NIMs into existing workflows and applications, thanks to the OpenAI-compliant API endpoints–and deploy anywhere your data resides.
- Secure processing: Your data privacy is paramount. NeMo Retriever embedding and reranking NIMs ensure that all inferences are processed securely, with rigorous data protection measures in place.
Meta Llama 3.1 tool calling
The new Llama 3.1 set of models can be seen as the first big push of open-source models towards serious agentic capabilities. These models can now become part of a larger automation system, with LLMs planning and picking the right tools to solve a larger problem. Since NVIDIA Llama 3.1 NIMs have the necessary support for OpenAI style tool calling, libraries like LangChain can now be used with NIMs to bind LLMs to Pydantic classes and fill in objects/dictionaries. This combination makes it easier for developers to get structured outputs from NIM LLMs without resorting to regex parsing.
As seen in the following Langchain tool calling snippet.
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documents."""
binary_score: str = Field(
description="Documents are relevant to the question, 'yes' or 'no'"
)
# LLM with function calling capability
llm = ChatOpenAI(
base_url="https://integrate.api.nvidia.com/v1",
model="meta/llama3.1-405b-instruct",
temperature=0
)
structured_llm_grader = llm.with_structured_output(GradeDocuments)
score = structured_llm_grader.invoke(
{"question": question, "document": documents}
grade = score.binary_score
RAG with agents
Retrieving passages or documents within a RAG pipeline without further validation and self-reflection can result in unhelpful responses and factual inaccuracies. Since the models aren’t explicitly trained to follow facts from passages post-generation verification is necessary.
To solve this, several RAG strategies like self-RAG and corrective RAG etc have been proposed which essentially market an agentic framework on top of the baseline RAG pipeline. These frameworks can be multi-agent, which provides the additional decision-making abilities needed to improve the quality of retrieved data and generated responses.
Architecture
Multi-agent frameworks, like LangGraph, enable developers to group LLM application-level logic into nodes and edges, for finer control over agentic decision-making. LangGraph with NVIDIA LangChain OSS connectors can be used for embedding, reranking, and implementing the necessary agentic RAG techniques with LLMs (as discussed previously).
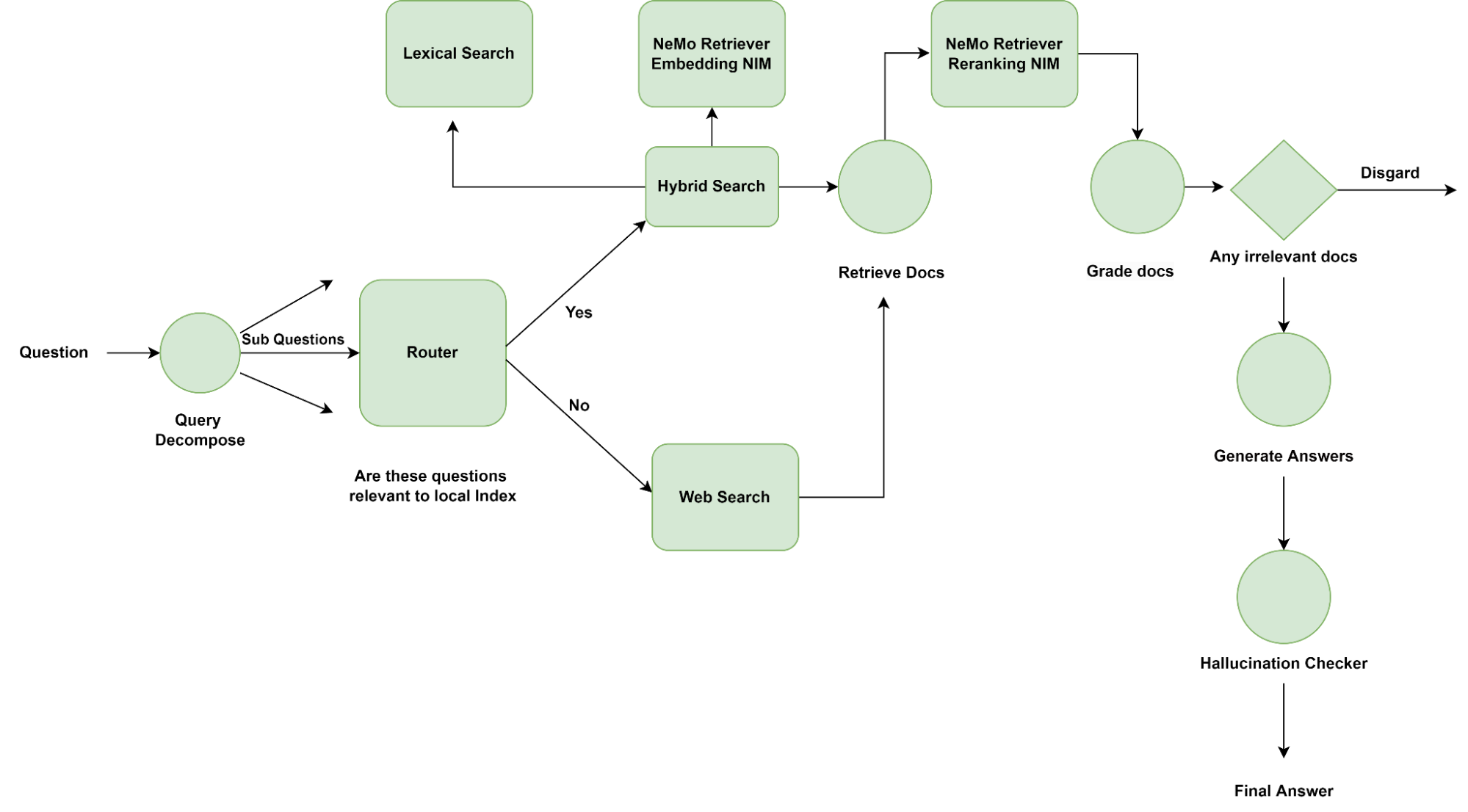
To implement this, an application developer must include the finer-level decision-making on top of their RAG pipeline. Figure 1 shows one of the many renditions on a router node depending on the use case. Here, the router switches between retrieving documents from local search or answering with an “I don’t know.”
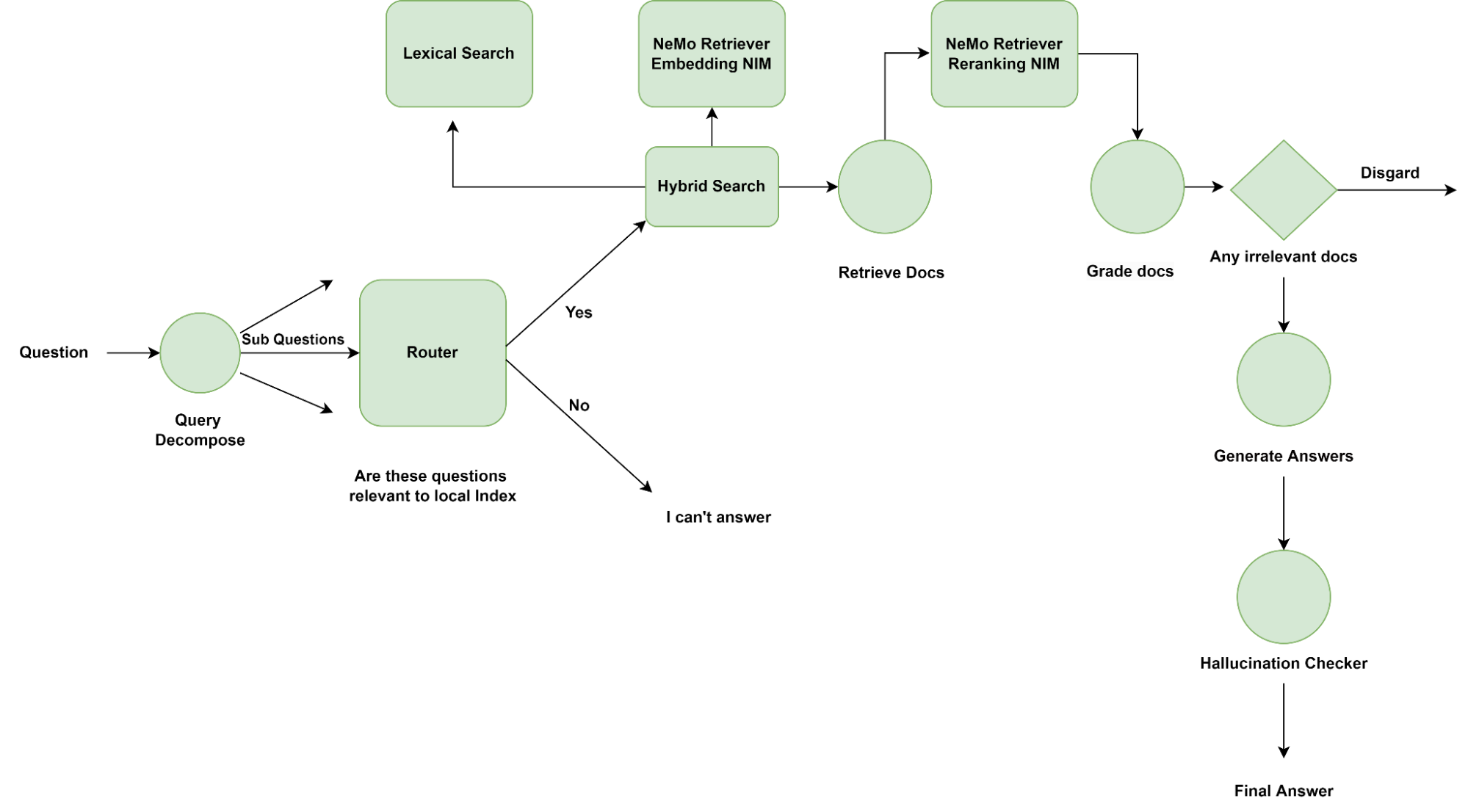
In Figure 2, we replace the default router with a web search tool, which resorts to searching the web for documents in case the questions aren’t relevant to documents stored locally.
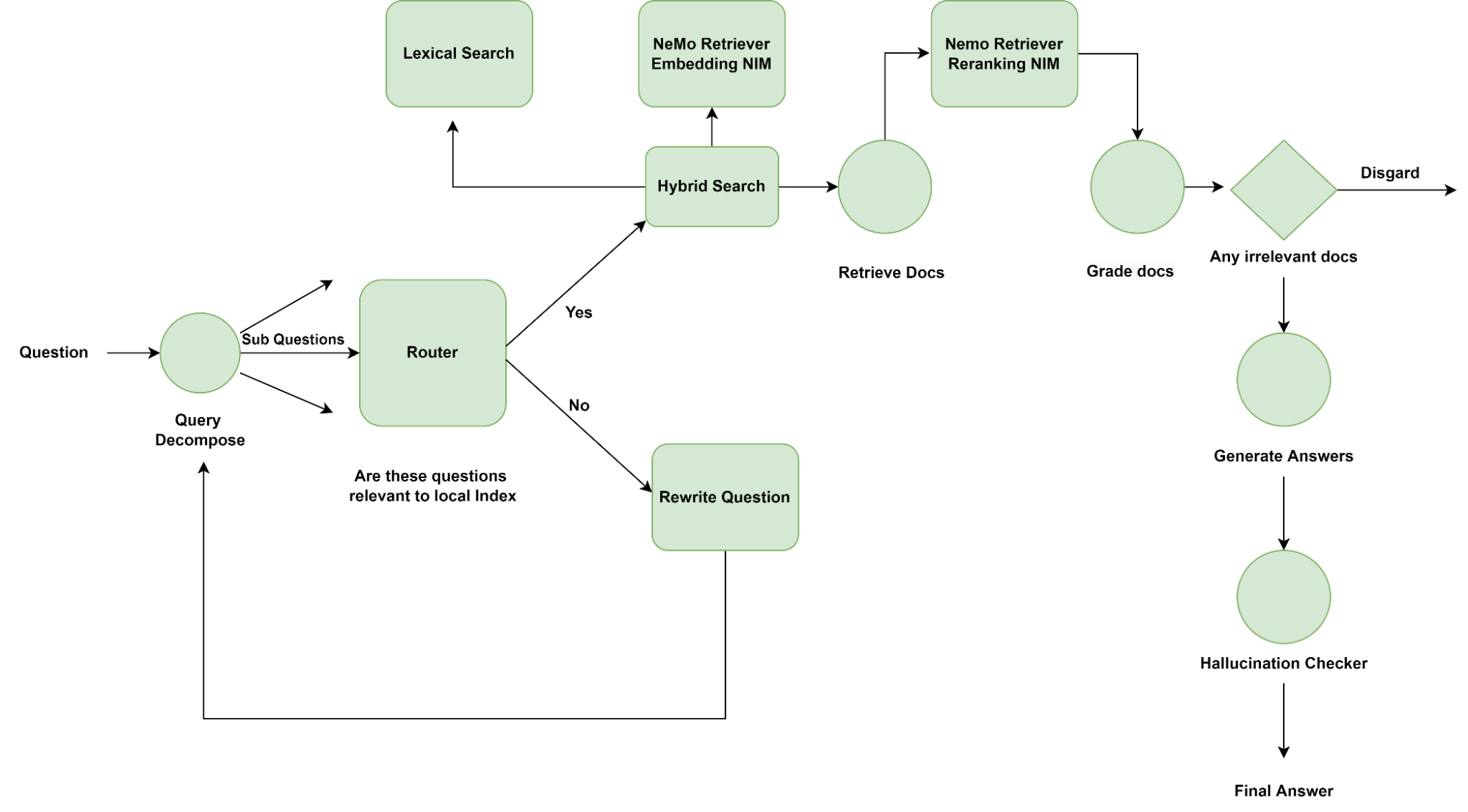
Finally, a decision can be made to ask the question differently by rewriting the query with help on an LLM, perchance of better recall from the retriever as shown in Figure 3.
Node specifications
Some of the noteworthy nodes and checkers, which every RAG pipeline may benefit from include
- Query decomposer: Breaks down the question into multiple smaller logical questions, and is helpful when a question needs to be answered using chunks from multiple documents.
- Router: Decides if chunks need to be retrieved from the local retriever to answer the given question based on the relevancy of documents stored locally. Alternatively, the agent can be programmed to do a web search or simply answer with an ‘I don’t know.’
- Retriever: This is the internal implementation of the RAG pipeline. For example, a hybrid retriever of a semantic and keyword search retriever.
- Grader: Checks if the retrieved passages/chunks are relevant to the question at hand.
- Hallucination checker: Checks if the LLM generation from each chunk is relevant to the chunk. Post-generation verification is necessary since the models are not explicitly trained to follow facts from passages.
Depending on the data and the use case, additional nodes and tools can be added to the example multi-agent workflow above. For example, a financial service copilot might need a calculator tool to go along with the query decomposition tool, to accurately answer questions about trends, percentage increases, or YoY growth.. Ultimately, a developer’s final decision for graph construction depends on accuracy, throughput, and cost requirements.
Getting started
NeMo Retriever embedding and reranking NIM microservices are available today. Developers can download and deploy docker containers and find Llama 3.1 NIMs at ai.nvidia.com. Check out our developer Jupyter notebook with a step-by-step implementation of the agentic RAG on GitHub.