

Die Rohdaten des UX-Berichts für Chrome (CrUX) sind in BigQuery verfügbar, einer Datenbank in Google Cloud. Für die Verwendung von BigQuery sind ein GCP-Projekt und SQL-Grundkenntnisse erforderlich.
In diesem Leitfaden erfahren Sie, wie Sie mit BigQuery Abfragen für das CrUX-Dataset schreiben, um aufschlussreiche Ergebnisse zur Nutzererfahrung im Web zu erhalten:
- Verstehen, wie die Daten organisiert sind
- Eine einfache Abfrage schreiben, um die Leistung eines Ursprungs zu bewerten
- Erweiterte Abfrage schreiben, um die Leistung im Zeitverlauf zu verfolgen
Datenorganisation
Beginnen Sie mit einer einfachen Abfrage:
SELECT COUNT(DISTINCT origin) FROM `chrome-ux-report.all.202206`
Um die Abfrage auszuführen, geben Sie sie in den Abfrageeditor ein und klicken Sie auf „Abfrage ausführen“ Schaltfläche:
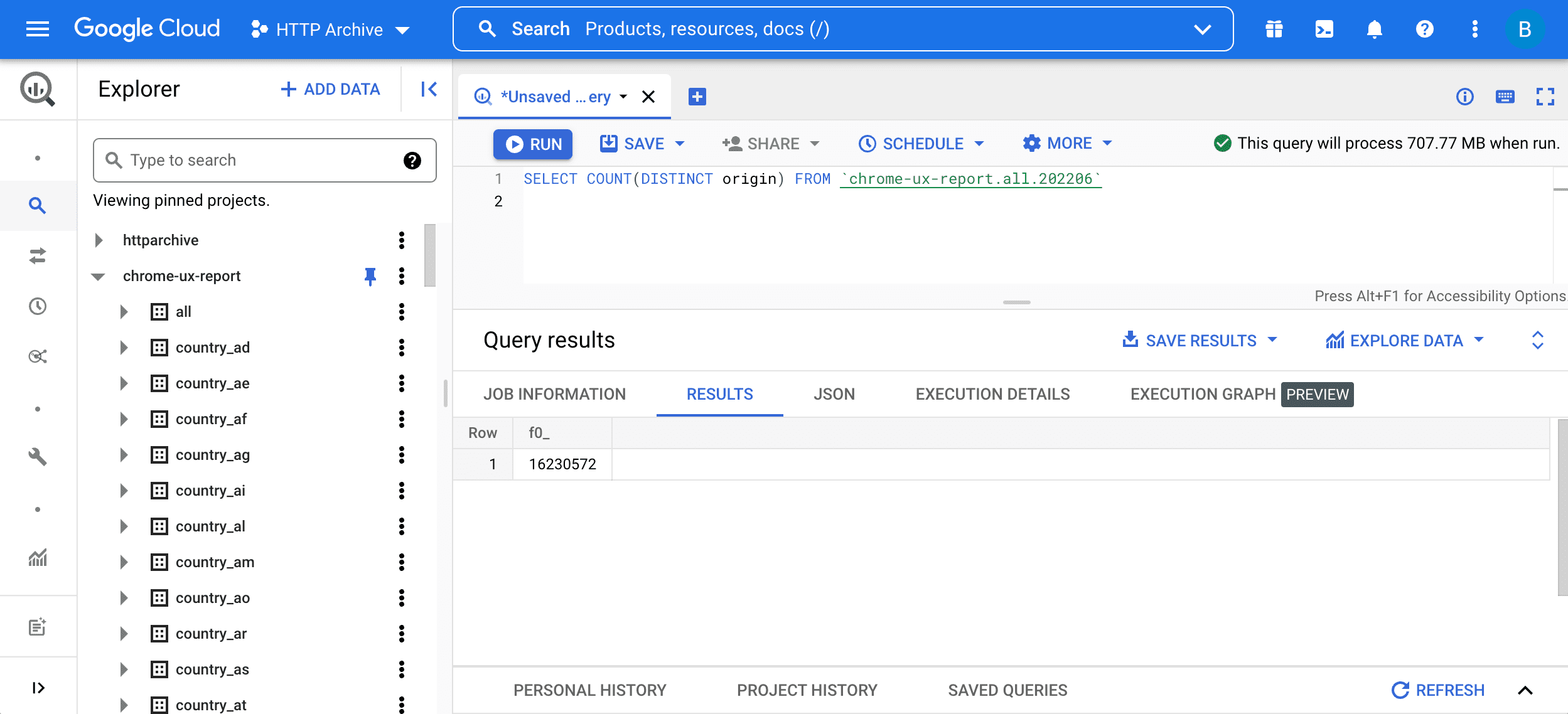
Diese Abfrage besteht aus zwei Teilen:
SELECT COUNT(DISTINCT origin)bedeutet, dass die Anzahl der Ursprünge in der Tabelle abgefragt werden soll. Kurz gesagt: Zwei URLs gehören zum selben Ursprung, wenn sie dasselbe Schema, denselben Host und denselben Port haben.FROM chrome-ux-report.all.202206gibt die Adresse der Quelltabelle an. Sie besteht aus drei Teilen:- Der Name des Cloud-Projekts
chrome-ux-report, in dem alle CrUX-Daten organisiert sind - Das Dataset
all, das Daten aus allen Ländern darstellt - Die Tabelle
202206mit dem Jahr und dem Monat der Daten im Format JJJJMM
- Der Name des Cloud-Projekts
Außerdem gibt es Datensätze für jedes Land. Beispielsweise repräsentiert chrome-ux-report.country_ca.202206 nur Daten zur Nutzererfahrung aus Kanada.
Jedes Dataset enthält Tabellen für jeden Monat seit 201710. Für den vorherigen Kalendermonat werden regelmäßig neue Tabellen veröffentlicht.
Die Struktur der Datentabellen (auch Schema genannt) enthält:
- Die Quelle, z. B.
origin = 'https://www.example.com', die die aggregierte Verteilung der Nutzererfahrung für alle Seiten dieser Website darstellt - Die Verbindungsgeschwindigkeit zum Zeitpunkt des Seitenaufbaus, z. B.
effective_connection_type.name = '4G' - Der Gerätetyp, z. B.
form_factor.name = 'desktop' - Die UX-Metriken selbst
<ph type="x-smartling-placeholder">
- </ph>
- first_paint (FP)
- First_contentful_paint (FCP)
- dom_content_loaded (DCL)
- Onload (OL)
- experimentell.first_input_delay (FID)
Die Daten für jeden Messwert sind als Array von Objekten organisiert. In JSON-Notation würde first_contentful_paint.histogram.bin so aussehen:
[
{"start": 0, "end": 100, "density": 0.1234},
{"start": 100, "end": 200, "density": 0.0123},
...
]
Jeder Container enthält eine Start- und eine Endzeit in Millisekunden sowie eine Dichte, die den Prozentsatz der Nutzererfahrungen innerhalb dieses Zeitraums angibt. Mit anderen Worten: 12,34% der FCP-Nutzung für diesen hypothetischen Ursprung, die Verbindungsgeschwindigkeit und den Gerätetyp betragen weniger als 100 ms. Die Summe aller Bin-Dichten ergibt 100%.
Struktur der Tabellen in BigQuery durchsuchen.
Leistung auswerten
Wir können unser Wissen über das Tabellenschema nutzen, um eine Abfrage zu schreiben, die diese Leistungsdaten extrahiert.
SELECT
fcp
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
effective_connection_type.name = '4G' AND
form_factor.name = 'phone' AND
fcp.start = 0
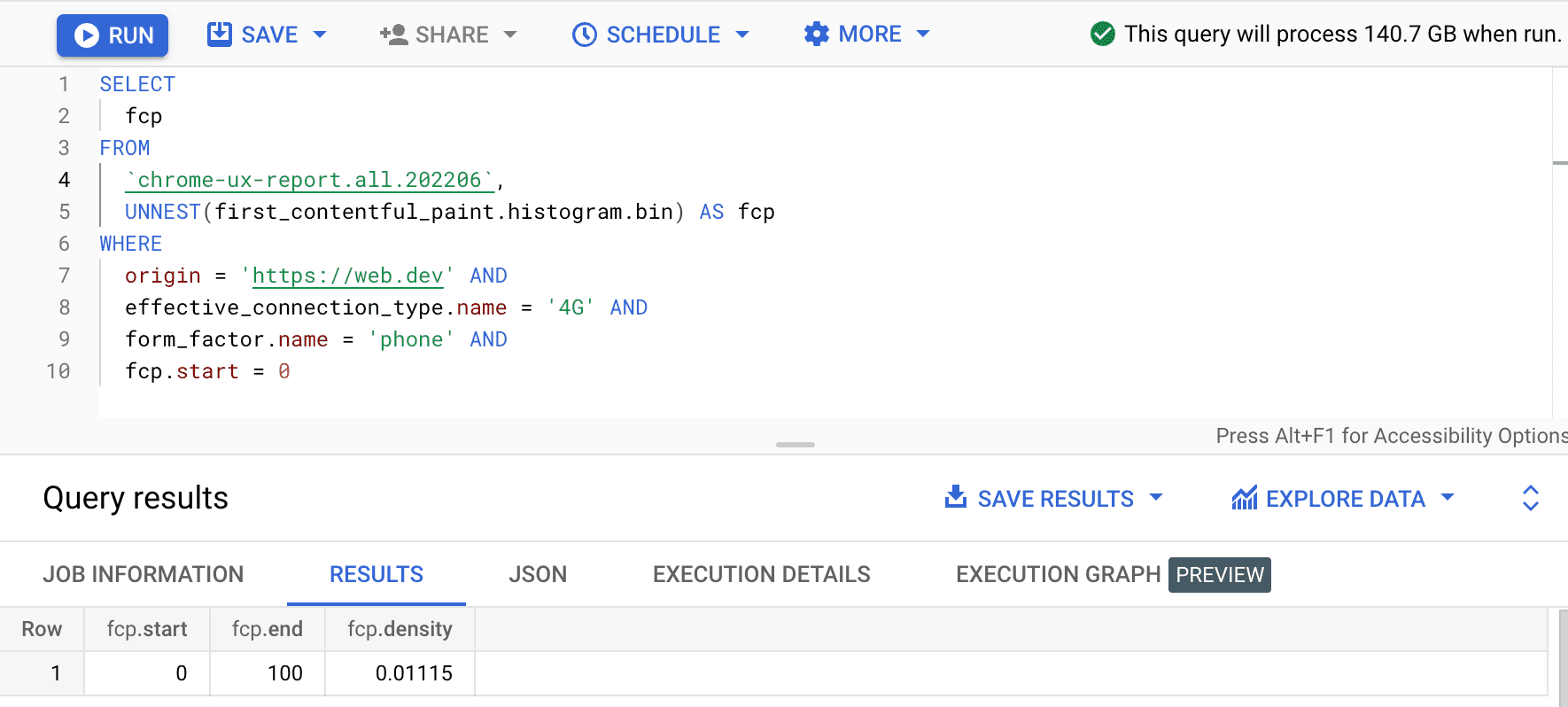
Das Ergebnis ist 0.01115, was bedeutet, dass 1,115% der Nutzererfahrungen bei diesem Ursprung bei 4G und auf einem Smartphone zwischen 0 und 100 ms liegen. Wenn wir unsere Abfrage für jede Verbindung und jeden Gerätetyp generalisieren möchten, können wir sie in der WHERE-Klausel weglassen und mit der Aggregator-Funktion SUM die entsprechenden Bin-Dichten addieren:
SELECT
SUM(fcp.density)
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start = 0
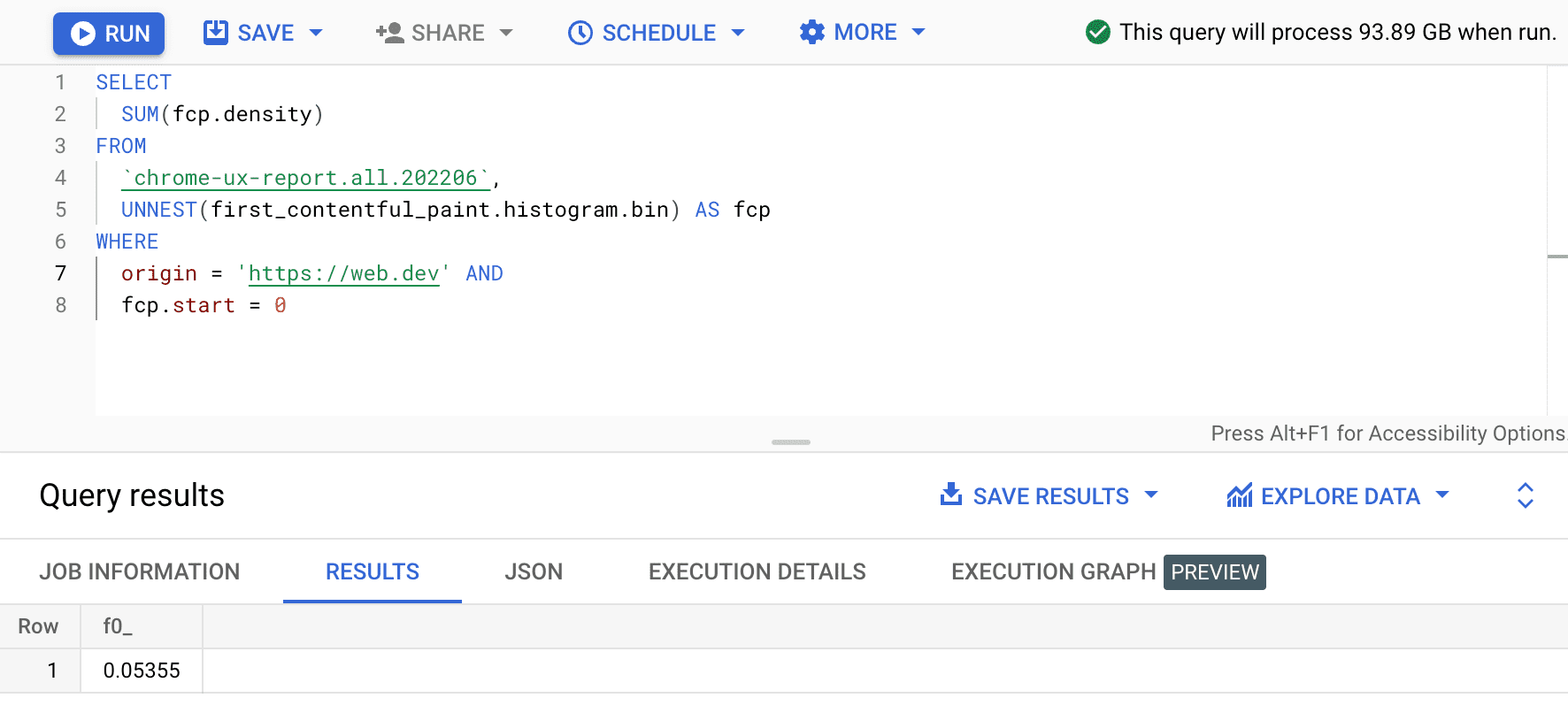
Das Ergebnis ist 0.05355 oder 5, 355% für alle Geräte und Verbindungstypen. Wir können die Abfrage leicht ändern und die Dichten für alle Klassen addieren, die sich im schnellen FCP-Bereich von 0–1.000 ms:
SELECT
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.202206`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
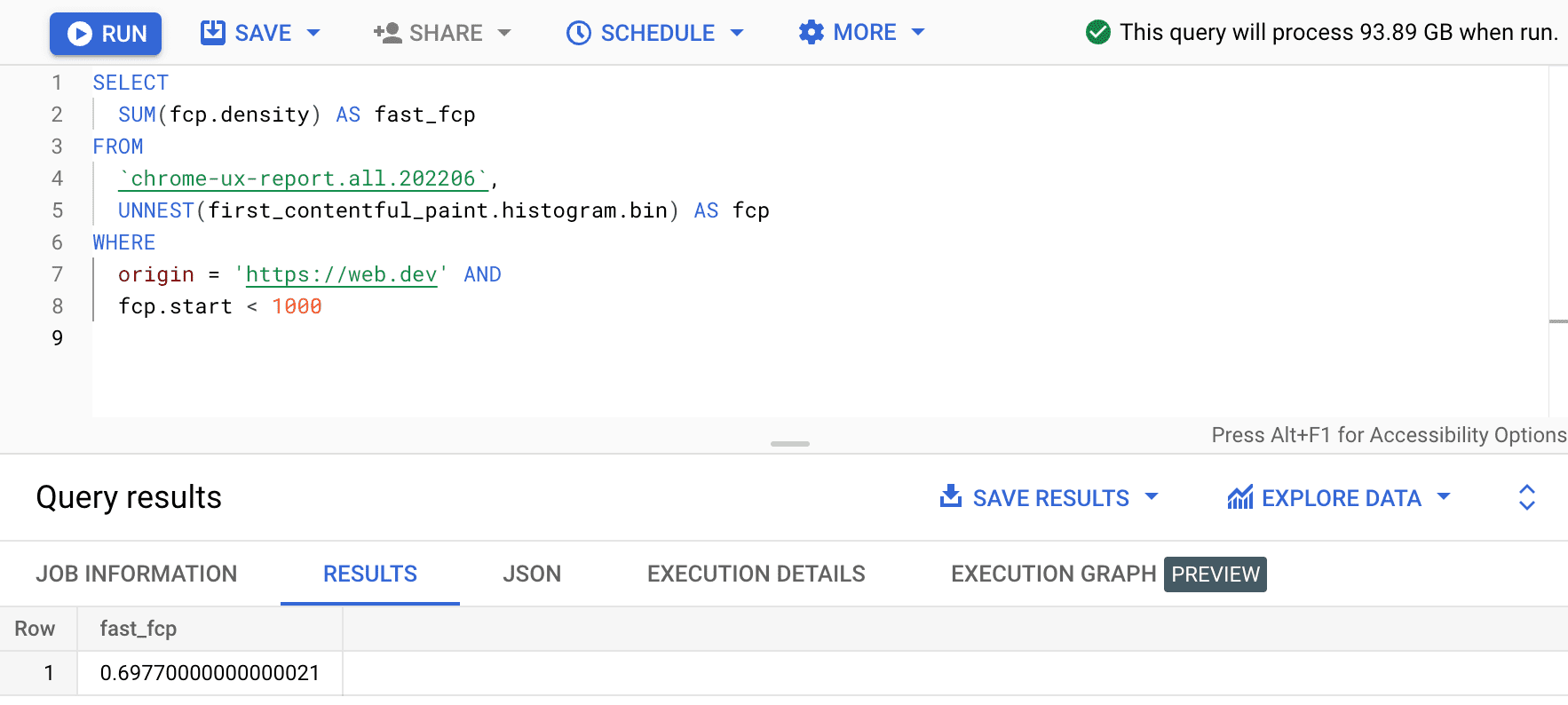
Dadurch erhalten wir 0.6977. Mit anderen Worten: 69, 77% der FCP-Nutzererfahrungen auf web.dev gelten als „schnell“. gemäß der Definition des FCP-Bereichs.
Leistungserfassung
Nachdem wir nun die Leistungsdaten zu einem Ursprung extrahiert haben, können wir sie mit den Verlaufsdaten aus älteren Tabellen vergleichen. Dazu könnten wir die Tabellenadresse in einen früheren Monat umschreiben oder die Platzhaltersyntax verwenden, um alle Monate abzufragen:
SELECT
_TABLE_SUFFIX AS yyyymm,
SUM(fcp.density) AS fast_fcp
FROM
`chrome-ux-report.all.*`,
UNNEST(first_contentful_paint.histogram.bin) AS fcp
WHERE
origin = 'https://web.dev' AND
fcp.start < 1000
GROUP BY
yyyymm
ORDER BY
yyyymm DESC
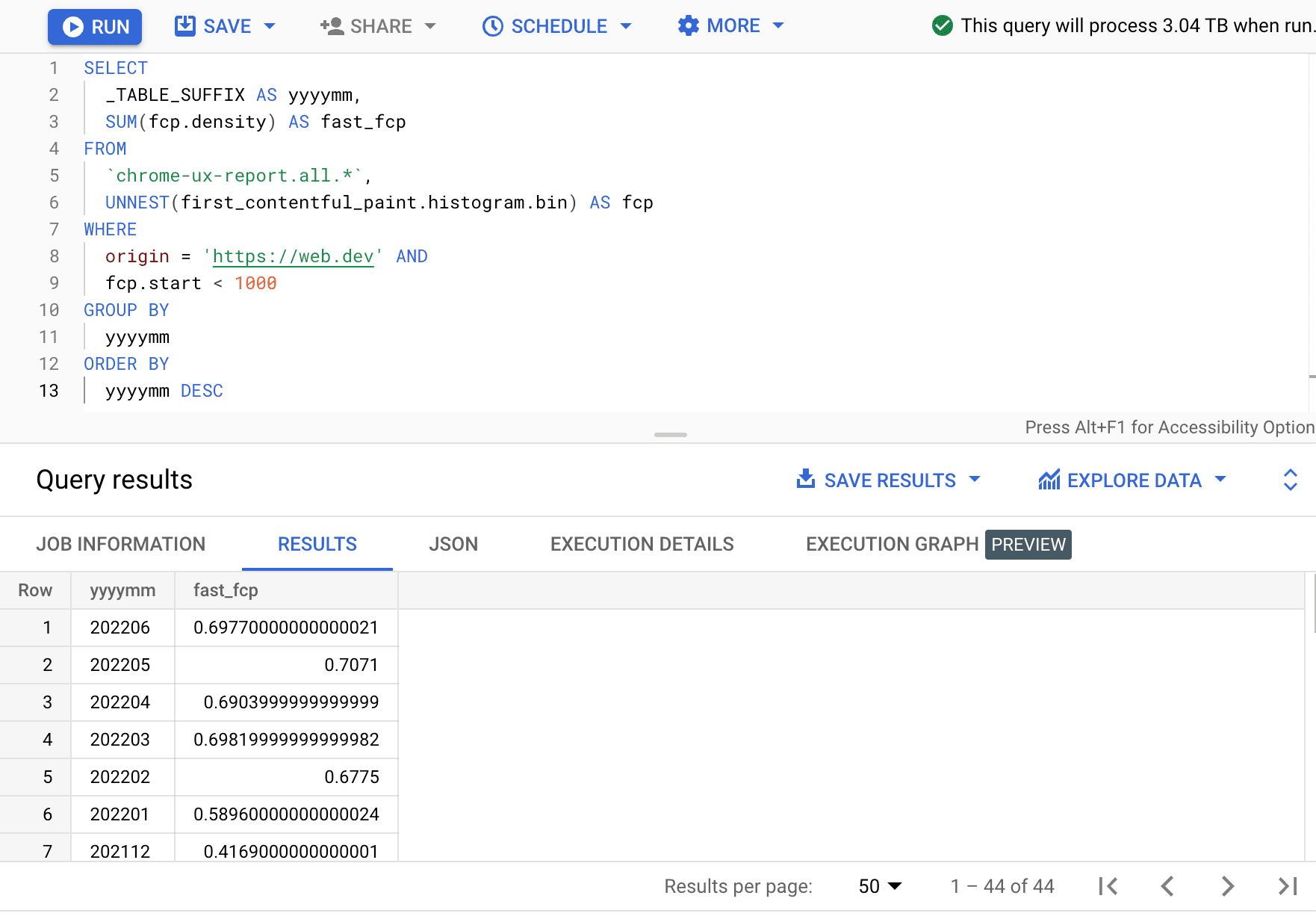
Hier sehen wir, dass der Prozentsatz der schnellen FCP-Nutzung jeden Monat um einige Prozentpunkte schwankt.
| jjjjmm | fast_fcp |
|---|---|
| 202206 | 69,77% |
| 202205 | 70,71% |
| 202204 | 69,04% |
| 202203 | 69,82% |
| 202202 | 67,75% |
| 202201 | 58,96% |
| 202112 | 41,69% |
| … | … |
Mit diesen Techniken können Sie die Leistung für einen Ursprung abrufen, den Prozentsatz der schnellen Tests berechnen und sie im Zeitverlauf verfolgen. Versuchen Sie als Nächstes, zwei oder mehr Ursprünge abzufragen und deren Leistung zu vergleichen.
FAQ
Im Folgenden finden Sie einige der häufig gestellten Fragen zum BigQuery-Dataset für CrUX-Dateien:
Wann verwende ich BigQuery und wann andere Tools?
BigQuery wird nur benötigt, wenn Sie mit anderen Tools wie dem CrUX-Dashboard und PageSpeed Insights nicht dieselben Informationen erhalten können. Mit BigQuery können Sie die Daten beispielsweise sinnvoll segmentieren und sogar mit anderen öffentlichen Datasets wie dem HTTP-Archiv für erweitertes Data Mining zusammenführen.
Gibt es Einschränkungen für die Verwendung von BigQuery?
Ja, die wichtigste Einschränkung besteht darin, dass Nutzer standardmäßig nur 1 TB Daten pro Monat abfragen können. Darüber hinaus gilt der Standardpreis von 5 $pro TB.
Wo erhalte ich weitere Informationen zu BigQuery?
Weitere Informationen finden Sie in der BigQuery-Dokumentation.